




点击蓝字
关注我们
某公司在迁移从阿里云DataWorks到自建大数据平台过程中,遇到海豚调度器在定时任务触发时导致CPU负载激增甚至系统崩溃的问题。经过排查,发现并非任务数量过多引起,而是调度器配置不当。通过调整海豚调度器的线程数和CPU限制值,成功解决了CPU飙升问题,确保了任务的平稳运行。参考此案例,用户在调整线程数时需平衡机器负载和并发任务需求。
1
背景
公司最近准备将之前一直使用的阿里云 DataWorks 产品进行下线,然后建设自己的大数据平台,全部采用开源组件。由于成本方面的控制,刚开始,公司并拿不出很多的资金去买很多的服务器,直接一步到位,只能是先购买 4 台 ECS 服务器,然后先将所有的组件进行混布,之后随着任务的迁移,将 DataWorks 的资源慢慢的下掉一些,然后再把对应的成本放到自建的大数据平台上。
对于调度平台,我们也是直接选择了目前比较火的海豚调度器。
2
遇到的问题
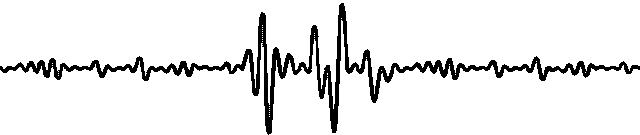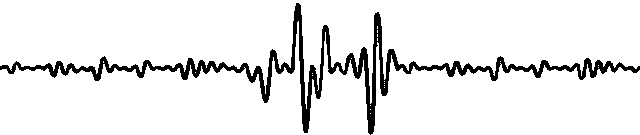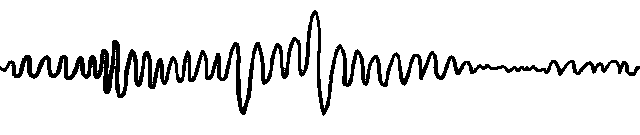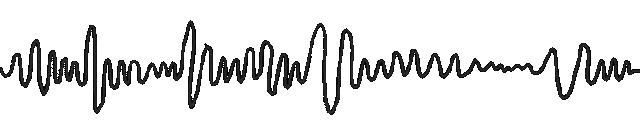
其他同事最近一直在将 DataWroks 上的离线任务迁移到海豚调度器上,改为 hive sql 实现。一段时间之后,海豚调度器上的任务已经有很多了,除了每天凌晨 2 点和 3 点的任务,每 5 分钟定时调度的任务也有很多。后来我们发现,每到 5 分钟定时触发的时候,我们的 ECS 机器的 CPU 负载就会从不到 5% 飙升到 100%,并且持续几秒钟。早上 2 点和 3 点的时候更严重,经常导致机器上其他组件角色停止运行,严重时,会直接导致机器底层操作系统奔溃,如下图所示:
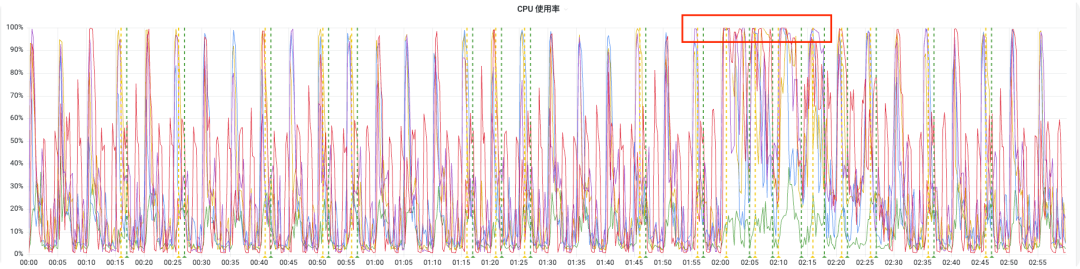
3
排查过程
我们刚开始以为是每到 5 分钟,或者是凌晨 2 点定时调度很多任务的时候,由于瞬间调度器来的任务有很多,同时运行的任务太多,导致资源消耗突然增高。然后我们手动将所有的任务放到同一个任务组中,然后观察资源消耗情况。之后我们发现,资源的使用曲线上,确实是更平滑了一些,但是每到 5 分钟,和凌晨 2 点的时候,还是会飙升,问题依旧没有得到根本解决。
然后我们就下线了所有任务的定时调度,只上线了 hive sql 类型任务的 5 分钟定时调度。但是,每到 5 分钟调度的时候,CPU 使用率还是会飙升到 100%,这说明,并不是瞬间运行的任务过多造成的,因为此时被调度的任务并不是很多,而且相对修改之前,任务数量已经下降了很多了。
最后,我们只能去排查海豚调度器自身是否会占用很多资源了。
4
解决方案
通过查看海豚调度器的 master、worker 配置文件,我们发现,在他们的 application.yaml 文件中,有一些和线程数以及 CPU、内存相关的配置,master 下的 application.yaml 文件中相关配置如下:
# 线程数相关配置
fetch-command-num: 10
# master prepare execute thread number to limit handle commands in parallel
pre-exec-threads: 10
# master execute thread number to limit process instances in parallel
exec-threads: 100
# master dispatch task number per batch, if all the tasks dispatch failed in a batch, will sleep 1s.
dispatch-task-number: 3
# CPU、内存相关配置
# master max cpuload avg, only higher than the system cpu load average, master server can schedule. default value -1: the number of cpu cores * 2
# 如果 cpu load 值大于下面设置的值,则该 worker 角色会停止服务,直到 cpu load 值小于下面设置的值,默认不限制
max-cpu-load-avg: -1
# master reserved memory, only lower than system available memory, master server can schedule. default value 0.3, the unit is G
# 如果剩余的内存小于下面设置的值(单位:G),则该 worker 角色会停止服务,直到剩余的内存值大于下面设置的值,默认为 0.3G
reserved-memory: 0.3
worker 下的application.yaml
文件中相关配置如下:
# 线程数相关配置
# worker execute thread number to limit task instances in parallel
exec-threads: 100
# CPU、内存相关配置
# worker max cpuload avg, only higher than the system cpu load average, worker server can be dispatched tasks. default value -1: the number of cpu cores * 2
# 如果 cpu load 值大于下面设置的值,则该 worker 角色会停止服务,直到 cpu load 值小于下面设置的值,默认不限制
max-cpu-load-avg: -1
# worker reserved memory, only lower than system available memory, worker server can be dispatched tasks. default value 0.3, the unit is G
# 如果剩余的内存小于下面设置的值(单位:G),则该 worker 角色会停止服务,直到剩余的内存值大于下面设置的值,默认为 0.3G
reserved-memory: 0.3
master 下的start.sh
文件有关 jvm 启动内存设置如下:
JAVA_OPTS=${JAVA_OPTS:-"-server -Duser.timezone=${SPRING_JACKSON_TIME_ZONE} -Xms4g -Xmx4g -Xmn2g -XX:+PrintGCDetails -Xloggc:gc.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=dump.hprof"}
worker 下的start.sh
文件有关 jvm 启动内存设置如下:
JAVA_OPTS=${JAVA_OPTS:-"-server -Duser.timezone=${SPRING_JACKSON_TIME_ZONE} -Xms4g -Xmx4g -Xmn2g -XX:+PrintGCDetails -Xloggc:gc.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=dump.hprof"}
如果自己的机器内存不是很多,也可以调整start.sh
中有关 JVM 内存设置。
我们主要调整了 master 和 worker 下的application.yaml
文件中有关线程数量和 cpu 限制值,线程数量全部调整为 3,CPU 限制,从 -1 调整为 4,我们机器的 CPU 核数均为 8,具体调整的数字,可以按照自己机器的配置来决定,也可以进行多次尝试。
之后我们再次观察机器的 CPU 使用率,发现每到 5 分钟调度时候,十分平稳,而且在凌晨 2 点和 3 点的时候,即使瞬间要调度器很多任务,也不会造成 CPU 飙升的情况,而且任务也在平稳运行,如下图所示:
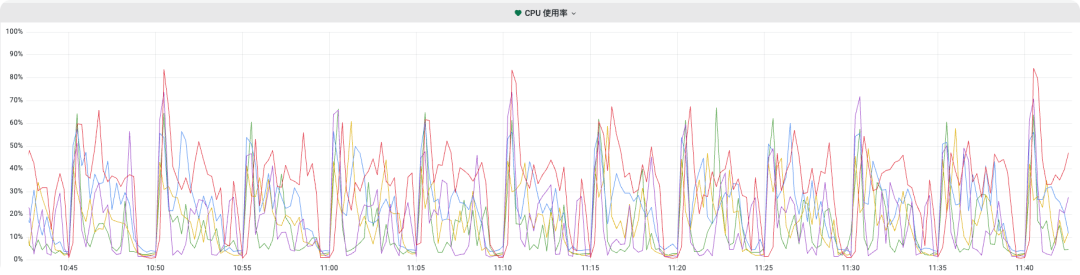
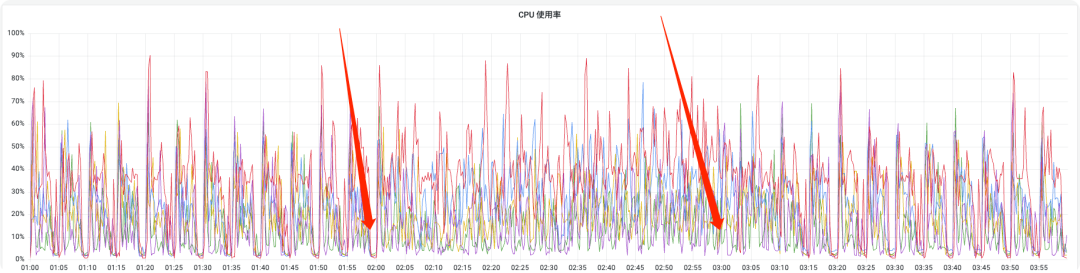
不过需要注意的是:
当把线程数调整小之后,可以被同时调度器来的任务数量将会变小,比如我上面调整每个 worker 的线程数为 3,一共 5 个 worker 节点,则整个海豚调度器并发执行的任务数量最大为 15,所以具体的线程数量,需要根据自己机器的负载,以及需要被同时调度的任务数量来共同调度,找到一个合理的值,既能够保证机器的负载不会突然飙升,也能够保证被定时调度的任务能够在合理的时间内执行完成。
转载自第一片心意
原文链接:https://blog.csdn.net/u012443641/article/details/129777498


用户案例
迁移实战
发版消息
加入社区
关注社区的方式有很多:
GitHub: https://github.com/apache/dolphinscheduler 官网:https://dolphinscheduler.apache.org/en-us 订阅开发者邮件:dev@dolphinscheduler@apache.org X.com:@DolphinSchedule YouTube:https://www.youtube.com/@apachedolphinscheduler Slack:https://join.slack.com/t/asf-dolphinscheduler/shared_invite/zt-1cmrxsio1-nJHxRJa44jfkrNL_Nsy9Qg
同样地,参与Apache DolphinScheduler 有非常多的参与贡献的方式,主要分为代码方式和非代码方式两种。
📂非代码方式包括:
完善文档、翻译文档;翻译技术性、实践性文章;投稿实践性、原理性文章;成为布道师;社区管理、答疑;会议分享;测试反馈;用户反馈等。
👩💻代码方式包括:
查找Bug;编写修复代码;开发新功能;提交代码贡献;参与代码审查等。

你的好友秀秀子拍了拍你
并请你帮她点一下“分享”
