




AI时代,大模型的成功应用不仅依赖于模型算法的构建,更在于数据的有效处理与挖掘。面对非结构化数据的日益增长,如何让向量数据库在保障性能的前提下,处理越来越大的向量数据集,并进行高效地向量相似度检索,已成为一项迫切需求。
对此,海量数据库Vastbase V100致力于提供高效、专业的向量存储与检索能力。用户可直接在Vastbase数据库中进行向量数据的高效存储、操作和矢量分析,并通过两种优秀的近似搜索算法:IVFFLAT算法和HNSW算法,实现数据在高维向量空间内有效快速的搜索。本期海量智库为大家介绍这两种索引的工作原理。
IVFFLAT索引工作原理
IVFFLAT索引生成时,会找到相似的向量形成多个簇,为每个簇计算一个中心点(质心),并将每个向量分配到其最近的质心。这种聚类确保在相似性搜索期间,只寻找与查询向量接近的向量,排除不那么相似的向量,大大提升搜索速度。
1
IVFFLAT空间划分
为直观了解 IVFFLAT 的工作原理,下面将在二维空间中,用以下几点表示一组向量:
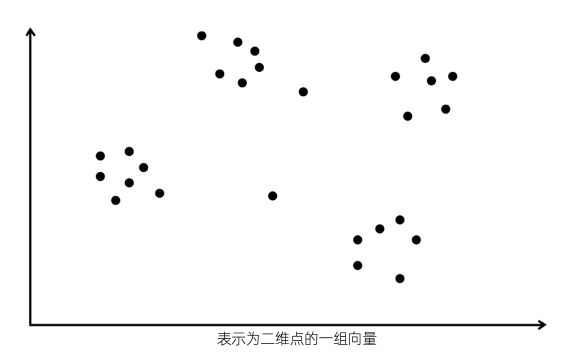
在IVFFLAT算法中,第一步是对向量进行k-means聚类,查找聚类质心(聚类中心点) 。假设在给定向量的情况下,执行 k-means聚类并识别出四个聚类及其质心,如下图:

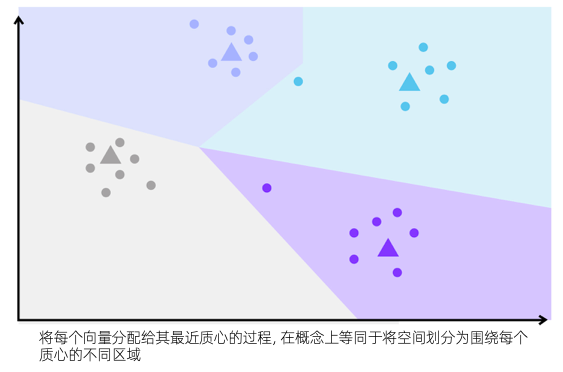
计算质心后,下一步是将每个向量分配给其最近的质心。这是通过计算向量和每个质心之间的距离,并选择距离最小的质心作为最近的质心来完成的。该过程从概念上等同于将空间中的每个点,根据邻近度映射到最近的质心。
通过建立映射,空间被划分为围绕每个质心的不同区域。每个区域代表一组表现出相似特征或语义接近的向量。这种划分使得在搜索操作期间,能够有效地组织和检索近似最近邻。因为同一区域内的向量,可能比不同区域内的向量彼此更相似。
2
构建IVFFLAT索引
继续创建一个倒排索引,将每个质心映射到相应区域内的向量集。在伪代码中,索引可以表示如下:
inverted_index = {
质心_1: [vector_1, vector_2, ...],
质心_2: [vector_3, vector_4, ...],
质心_3: [vector_5, vector_6, ...],
...
}
每个质心充当倒排索引中的键,对应的值是属于与该质心关联的区域的向量列表。这种索引结构允许在执行相似性搜索时,有效地检索区域的向量。
3
搜索IVFFLAT索引
假设要查找由问号表示的向量的最近邻,如下所示:
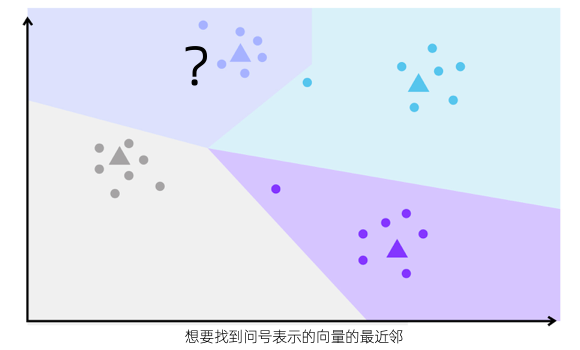
假设最近的向量将位于与查询向量相同的区域中,IVFFLAT 将采用以下步骤:
计算查询向量(黑色问号)与索引中每个质心之间的距离。
选择距离最小的质心,作为距离查询最近的质心(本例中为第一个质心)。
从倒排索引中检索与最近质心对应的区域关联的向量。
计算查询向量与检索集中的每个向量之间的距离。
选择距离最小的K个向量,作为查询的近似最近邻。
IVFFLAT索引的使用,将搜索限制在与最近质心相关的区域,使搜索过程中需要检查的向量数量显着减少,加速搜索过程。如果有C个聚类(质心),就可以将要搜索的向量数量减少到1/C。
4
边界搜索
如果限定最近的向量,只能在与查询向量相同的区域中找到,可能会在 IVFFLAT 中引入召回误差。则考虑以下查询:

明显看出,尽管查询向量落在第一个区域,但其中一个向量(位于第二个区域)比任何第一个区域内的向量,更接近查询向量。这就是假设最近的向量总是和查询向量,在同一个区域的潜在误差。
为了减轻此类误差,一种方法是不仅搜索同一片区域内的所有向量,而且搜索下一个最近质心所在的区域,扩大搜索范围,提高找到真正最近邻的机会。
在海量数据库Vastbase V100中,该功能通过参数probes指定搜索的区域数量。
HNSW索引工作原理
HNSW(层次化导航网格)算法是最有效的最近邻搜索算法之一。基于图的和多层的性质,它可以支持大数据量的高维向量搜索, 在召回率和性能上都有优秀的表现。与IVFFLAT索引相比,HNSW 使用邻近图(根据节点之间的距离连接节点的图)。
为了理解 HNSW的工作原理,可以将其分为两部分:
分层 (H):算法在多个层上运行。
可导航小世界 (NSW):每个向量是图中的一个节点,并连接到其他几个节点。
1
分层
HNSW 的分层方面建立在跳表的思想之上。
跳跃列表是多层链表,底层是一个连接有序元素序列的规则链表。上面的每个新层会从底层删除一些元素(基于固定概率),产生一个“跳过”元素的稀疏子序列。这个过程比链表中普通的线性搜索快得多。
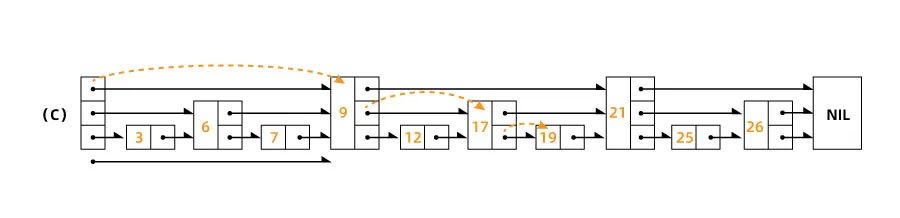
HNSW 继承了相同的思想,但它使用的不是链表,而是图。
2
可导航小世界(NSW)
NSW是一个图结构。其中每个顶点都连接到其他顶点,形成好友列表。用NSW搜索将从与附近顶点相连的入口点开始,通过贪婪路由迭代地移动到最近的顶点。这个过程持续到达到局部最小值,即没有更近的顶点可用。
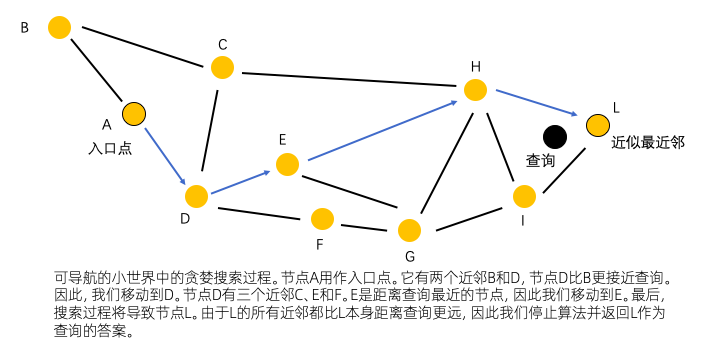
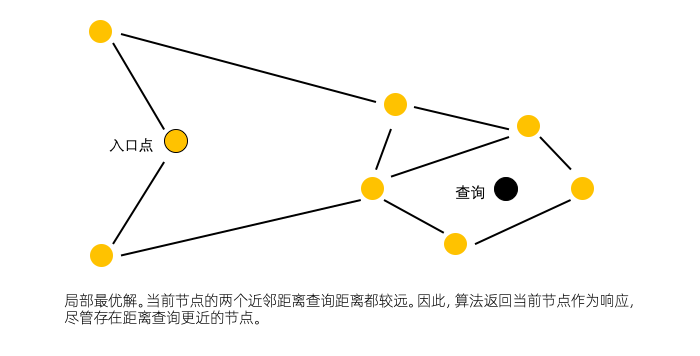
这种贪婪策略不能保证会找到精确的最近邻居,返回的是局部最优解。
3
HNSW层次化导航网络
理解上述两种算法后,再来理解HNSW 的运作原理。
HNSW 的主要思想与六次握手规则(人与人之间的社会关系距离不超过6个)有异曲同工之妙。即构建一个图:其中任何一对顶点之间的路径,都可以通过少量步骤遍历。HNSW 把向量划分到不同的层中,最高层有最少的向量,最底层有完整的向量,层与层之间的关系类似于跳表。每一层中的向量,可以通过NSW算法构建成一个图,然后使用贪婪算法,找到图中和目标向量最接近的向量。
以下图为例:
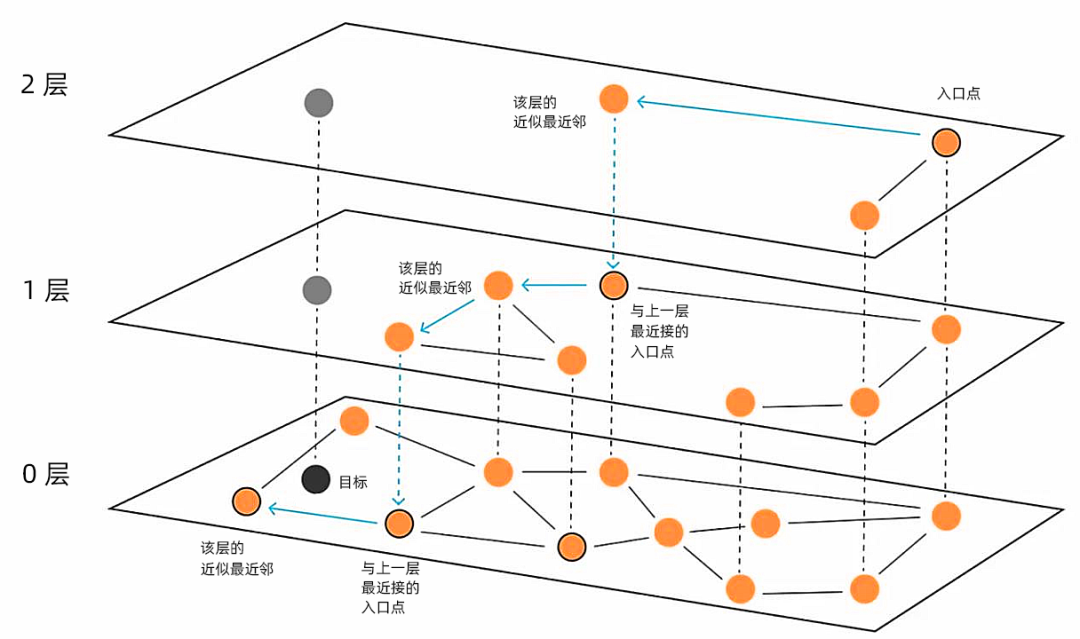
黑色的向量是要寻找的目标,想要知道离它最近的向量都有哪些,可以从最高层layer2开始,任选一个入口点,找到该层与其对应且离目标向量最近的向量。这就像跳表一样,可以很快缩小查询范围,进入到下一层。此时入口点就是上一层最接近的点,然后继续同样的动作,直至最下面一层。在HNSW中插入方法类似,但需要随机确定这个点出现的最大层l。
如下图新插入的点l=2,即它只会出现在0,1,2三层中。与查询过程同样,从最上层往下找,找到第2层中离插入点最近的点,并选择M个点构建邻居关系,在第1层和第0层以此类推。
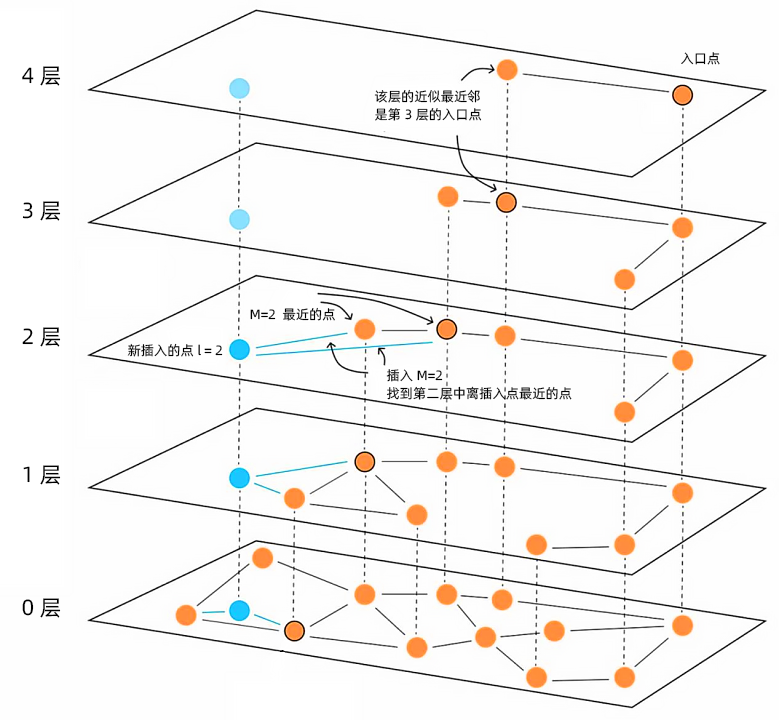
在海量数据库Vastbase V100中,HNSW图索引图的稀疏与否,通过m参数和ef_construction参数控制,搜索范围由参数hnsw_ef_search控制。
IVFFLAT与HNSW有何不同?
IVFFLAT索引 | HNSW索引 | |
特征 | 将向量空间划分为分区 | 构建类似图结构的相似向量 |
构建时间 | 显著更快 | 显著更慢 |
内存使用 | 较少内存 | 更多内存 |
准确性 | 对高维向量通常准确性有限 | 尤其是对于高维向量,通常具有更好的准确性 |
适应性 | 可能不适用于所有向量分布,向量数据更新频繁时搜索准确性下降, 需要定期重建索引 | 很好地处理各种向量分布, 向量数据更新不影响搜索准确性 |
想要理解IVFFLAT和HNSW的真实世界,可以想象你住在一个城市,需要找到一个与你喜欢的餐厅相似的餐厅(“最近邻”)。
IVFFLAT就像有一张带有标签的社区地图:
● 根据一般特征将城市划分为不同的区域。
● 可以快速告诉你哪些社区可能有类似的餐厅。
● 引导你到那些社区内的餐厅,可能接近,但不一定是每个方面都最相似。
● 快速开始使用地图(更快的索引构建)。
● 需要较少的内存来存储地图。
HNSW就像有一个了解城市的当地向导:
● 了解城市如何连接餐厅(相似的口味、氛围等)。
● 可以快速引导你,到体验上接近你最喜欢的餐厅,即使它们区域分布不完全相同。
● 需要向导花更多时间了解城市(构建索引)。
● 需要向导记住更多信息(更高的内存使用)。
选择正确的方法取决于业务场景的优先级。HNSW适用于复杂的城市布局(大型数据集)。它就像向导,优先找到各个方面都最相似的餐厅,即使需要更长的时间。IVFFLAT适用于中小型城市(中小型数据集)。它就像地图,专注于快速找到类似的餐厅,即使它不是完美的。
在AI时代,向量数据的检索效率决定了AI应用的落地效果。海量数据库Vastbase V100可通过IVFFLAT和HNSW两种算法,实现对高维向量数据的快速检索与查询,帮助用户真正实现AI应用的高质量落地。
• END •
往期推荐




关于海量数据
北京海量数据技术股份有限公司(股票代码:603138.SH)成立于2007年,是国内首家以数据库为主营业务的主板上市企业。公司十余年来秉承“专注做好数据库”的初心,始终致力于数据库产品的研发、销售和服务。核心产品海量数据库Vastbase系列、数据库一体机Vastcube系列、海量大数据Datalink系列,全栈国产化,应用满足度高,目前广泛应用于政务、制造、金融、通信、能源、交通等多个重点行业,已成为国产企业级数据库的首选之一。


