





本文字数:14190;估计阅读时间:36 分钟
作者:Miel Donkers

Meetup活动
ClickHouse Shenzhen User Group第2届 Meetup 火热报名中,详见文末海报!

Dash0 的创始团队拥有深厚的 Instana 背景——这家公司以其在可观测性工具方面的创新而闻名。在 Instana 发展的早期阶段,我们主要依赖 Cassandra 和 ElasticSearch 作为存储方案。随着平台不断扩展,为满足不断增长的客户需求和功能要求,团队逐渐转向 ClickHouse,作为核心数据库技术,以提升系统的效率和可扩展性。
在创建 Dash0 之初,选择 ClickHouse 作为主要存储系统是一个自然而然的决定,尤其是因为我们的两位联合创始人曾参与构建 ClickHouse 的云产品。如今,ClickHouse 承载了我们所有的 OpenTelemetry 数据,唯一使用的其他数据库是 PostgreSQL,专门用于处理客户相关的配置与数据。
本文将分享我们使用 ClickHouse 的完整历程——从最初的评估到技术实现的细节,并重点介绍一些关键特性,正是这些能力让 Dash0 得以实现。

Dash0 的目标是构建一个原生支持 OpenTelemetry 的系统,充分发挥 OpenTelemetry 信号所提供的丰富信息价值:
- 跨信号关联:工程师可以从指标出发,深入查看相关的追踪信息,并在同一工作流程中排查关联的日志。
- 服务健康监控:平台保留了 OpenTelemetry 的语义约定,可自动生成有意义的仪表板,并创建具备可操作性的告警。
- 简化故障排查:通过维护各类信号之间的关联,Dash0 显著缩短了事故的平均恢复时间(MTTR)。
这些能力对底层存储也提出了新的要求:
能够处理并存储所有类型的信号:指标(Metrics)、日志(Logs)和追踪(Spans) 能够通过资源属性(Resource attributes)或字段(如 TraceId 和 SpanId)在不同信号之间建立引用关系,例如通过日志中的 TraceId 关联到对应的追踪 支持高基数数据结构,因为属性既存在于资源层,也存在于信号层
为了满足这些需求,将所有数据整合到一个统一的系统中是最合适的方案。这不仅使我们可以直接通过 SQL 的 JOIN 操作将不同类型的信号关联起来,同时也能充分利用 ClickHouse 在大规模监控负载中的可扩展能力。
ClickHouse 的列式存储架构特别擅长处理 OpenTelemetry 属性中的高基数数据(即包含丰富上下文和元数据的键值对)。虽然这些属性可以作为 Map(String, String) 类型存储,但我们通常会将查询频率较高的属性(如 service.name)提取为独立的物化列,以提升查询效率。此外,ClickHouse 最近引入的原生 JSON 支持,更高效地处理了复杂的动态数据结构。这种新特性既保留了 Map 的灵活性,又具备物化列的高性能,从而让系统配置更加简洁。
ClickHouse 还提供了完善的 Java 和 Golang 客户端库,这两种语言都是 Dash0 技术栈中的核心。我们团队本身精通 Java,同时也自然地选择了 Golang —— 不仅因为很多 OpenTelemetry 相关的集成库都是用 Golang 编写,还因为我们打算使用的 OpenTelemetry Collector 也是用 Golang 构建的,并且已经在其官方代码库中集成了 ClickHouse 导出器。
除了支持 Dash0 功能所需的表结构(后文会详细说明),我们还基于过往经验对 ClickHouse 的运行策略进行了全面优化,在可维护性、系统性能和成本控制之间实现了良好平衡。当然,我们也通过 Dash0 平台自身实时监控 ClickHouse 的运行状态,确保系统持续稳定。
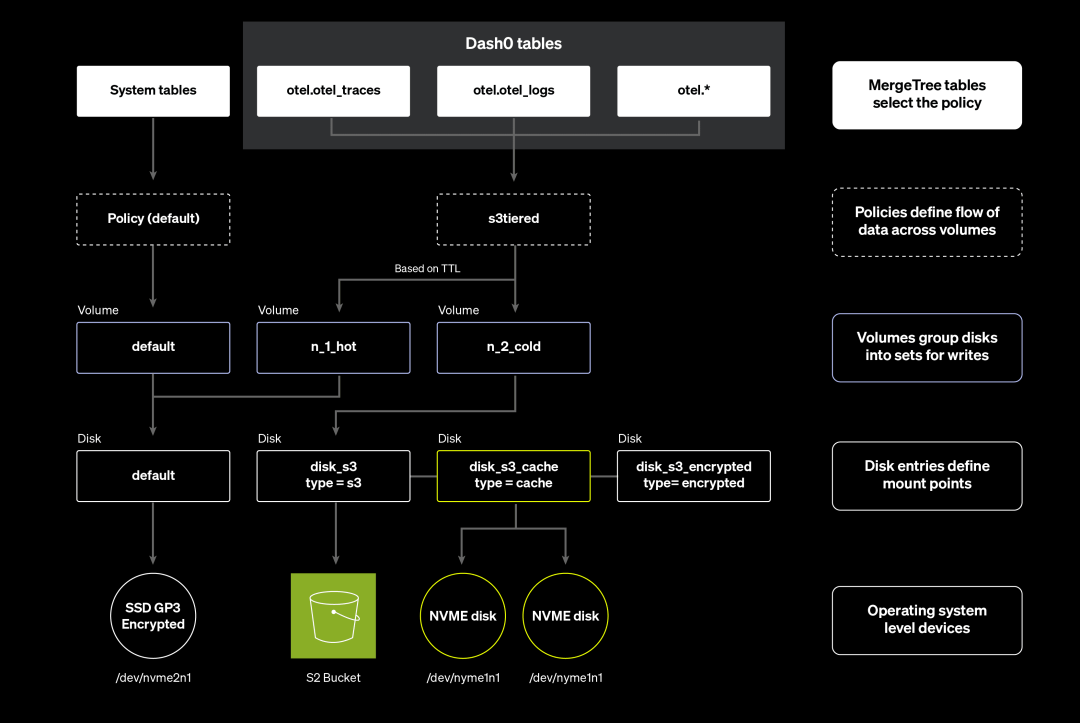
存储策略
对于任何可观测性平台来说,随着客户数量增长,数据体量会迅速膨胀,因此控制存储成本至关重要。但与此同时,又必须满足对查询性能的严格要求。虽然日志和追踪数据(Spans)在几周后可能价值下降,但我们希望能长期保留指标数据(Metrics),以支持一年以上的季节性趋势分析。
借助我们在 ClickHouse 工作期间积累的实践经验,我们采用了混合存储架构:将 AWS S3 作为主要存储,同时结合本地临时存储。ClickHouse 原生就很好地支持这一架构。从用户行为来看,大多数查询集中在过去 1 到 2 天的数据,这正好契合仪表板查看、故障排查等典型场景。
得益于 ClickHouse 高效的压缩能力,数据从热存储迁移至冷存储的时机可以有效延后,这使得短期内保留 1-2 天的热数据成为可行的做法。
我们的多层磁盘结构设计如下:
本地磁盘保留近 1-2 天的热数据 历史数据归档到 AWS S3 使用本地磁盘作为查询缓存
本地缓存机制能够暂时保留从 S3 获取的数据,加快后续相同数据的查询速度,并有效减少 S3 的 GET 请求次数,从而降低整体成本。
磁盘的具体配置如下所示:
<clickhouse><storage_configuration><disks><default><keep_free_space_bytes>536870912</keep_free_space_bytes></default><disk_s3><data_cache_enabled>true</data_cache_enabled><endpoint>...s3 endpoint...</endpoint><type>s3</type></disk_s3><disk_s3_cache><disk>disk_s3</disk><path>/mnt/cache-disk/</path><type>cache</type></disk_s3_cache></disks><policies><s3tiered><move_factor>0.100000</move_factor><volumes><n_1_hot><disk>default</disk></n_1_hot><n_2_cold><disk>disk_s3_cache</disk></n_2_cold></volumes></s3tiered></policies></storage_configuration></clickhouse>
ClickHouse 表结构中的排序优化
虽然我们在此不展开表结构的全部细节,但可以明确的是,ORDER BY、PARTITION BY 以及 TTL 等定义与存储性能密切相关。
其中,TTL 子句用于确保 ClickHouse 能够按期将数据从本地迁移至 S3 存储。
TTL toDateTime(Timestamp) + INTERVAL 25 HOUR TO VOLUME 'n_2_cold',toDateTime(Timestamp) + INTERVAL 13 MONTH DELETE
而 ORDER BY 子句的重要性主要体现在两个方面:
提升查询效率 优化数据压缩率
在表结构设计中,我们对主键的选择进行了深思熟虑的权衡。不同于 ClickHouse Exporter 在所有信号中统一使用 service.name 作为主键的一种方式,我们生成了一个名为 ResourceHash 的哈希值,它基于所有资源属性构成,并起到了类似的索引作用。最终我们采用的主键结构是:ResourceHash + Timestamp。
在 ORDER BY 子句中将 ResourceHash 或 service.name 放在 Timestamp 之前,带来了两个关键优势:
1. 优化过滤效率:在处理 OpenTelemetry 数据时,用户往往需要基于资源属性进行过滤,即通过 ResourceHash 实现信号间的关联。这样的字段排序方式使 ClickHouse 能跳过大量无关数据块(marks,是 ClickHouse 用于定位数据的索引结构),大幅减少扫描记录的数量。
2. 提高压缩效果:来自同一服务或进程的信号往往具有高度相似性,不仅资源属性相似,连日志内容、Span 名称等字段也有相似结构。按 ResourceHash 排序能够将这些相似记录分组存储,显著提升数据压缩比,相比以 Timestamp 开头排序的方式效果更好。
当然,也可以采用另一种顺序:先按 Timestamp,再按 ResourceHash 排序。毕竟 Dash0 的所有查询都要求指定时间范围,这样可以首先根据时间过滤掉大部分无关数据,而资源属性则未必总用于过滤逻辑。为了解决这种排序下可能影响过滤效率的问题,我们采用了按 Timestamp 中的“日期”字段进行 PARTITION BY 的策略,从而确保 ClickHouse 仅扫描查询时间范围内的数据分区,提升整体读写效率。
虽然 ClickHouse 支持通过 projection 为同一张表定义多个主键,但我们最终没有采用这种设计,因为 projection 会带来额外的存储开销,不符合我们对成本控制的要求。
ClickHouse 的复制与分片策略
在当前的 ClickHouse 集群架构中,我们选择了使用多个副本,同时仅保留一个分片。虽然未来可能会根据业务扩展考虑引入多分片机制,但就目前而言,这种设计更为简单,已能够满足我们的使用需求。
一旦启用多分片架构,所有表结构变更和数据迁移操作都需要在每个分片上分别执行,此外,其他与集群相关的变更操作也会变得更加复杂。
接下来,我们将进一步介绍 Dash0 所使用的 ClickHouse 表结构设计,以及一些关键的 ClickHouse 特性,如何帮助实现我们平台的核心能力。
指标元数据优化
OpenTelemetry Collector 中标准的 ClickHouse Exporter 会将不同类型的指标分别存储在不同的表中,且每条记录都包含完整的指标信息。但这种方式存在多个问题:
指标名称(MetricName)、描述(MetricDescription)和单位(MetricUnit)等元数据通常在多个数据点之间保持一致。如果在每条记录中都重复保存这些内容,会导致数据重复度极高,浪费大量存储空间。即便是每个数据点携带的属性值,也往往是类似的,比如 http.response.status_code 这个属性通常取值为 200 或 500。对于这种情况,是可以进行去重优化的。 将属性存储为 Map 类型字段,在查询时效率较低,同时作为主键的组成部分也表现不佳。 如果用户想查询某个指标,但并不确定其具体类型(如 sum、gauge 或 histogram 等),就需要在五张不同的表中分别查找,操作成本较高。
为了优化这些问题,我们采用了一种被 Prometheus Remote Write 库以及 ClickHouse 自有的 Time-Series 引擎广泛使用的策略:将指标的元数据抽出,单独存入一张元数据表中,并通过 ID 与实际的指标数据关联。
尽管我们仍然为不同的指标类型建立了独立的表(因为各类指标在结构设计上存在差异),但该方案显著提升了整体数据的压缩效率。下面是我们为 gauge 类型指标设计的简化表结构示例:
CREATE TABLE IF NOT EXISTS otel.otel_metrics_gauge(`MetricHash` UInt64 Codec(LZ4),`StartTimeUnix` DateTime64(9) CODEC(Delta, LZ4),`TimeUnix` DateTime64(9) CODEC(Delta, LZ4),`Value` Float64 CODEC(LZ4),)ENGINE MergeTreePARTITION BY toDate(TimeUnix)ORDER BY (MetricHash, TimeUnix)
在我们的指标表中,MetricHash 字段作为与元数据表关联的主键字段,后文将会有更详细的介绍。
由于指标数据通常是以固定间隔采集(例如每 15 秒一次),ClickHouse 的 Delta 压缩算法在 TimeUnix 列上可以发挥极佳效果。而且大多数指标值在连续采集的时间段中变化并不大,这进一步提升了压缩比。
我们的指标元数据表结构如下:
CREATE TABLE IF NOT EXISTS otel.otel_metrics_metadata(`TimeUnix` Date CODEC(Delta, LZ4),`MetricName` LowCardinality(String) CODEC(LZ4),`MetricHash` UInt64 CODEC(LZ4),`FirstSeen` SimpleAggregateFunction(min, DateTime64(9)) CODEC(T64, LZ4),`LastSeen` SimpleAggregateFunction(max, DateTime64(9)) CODEC(T64, LZ4),`ResourceAttributes` SimpleAggregateFunction(anyLast, Map(String, String)) CODEC(LZ4),`ResourceSchemaUrl` SimpleAggregateFunction(anyLast, String) CODEC(LZ4),`ScopeName` SimpleAggregateFunction(anyLast, String) CODEC(LZ4),`ScopeVersion` SimpleAggregateFunction(anyLast, String) CODEC(LZ4),`ScopeAttributes` SimpleAggregateFunction(anyLast, Map(String, String)) CODEC(LZ4),`ScopeDroppedAttrCount` SimpleAggregateFunction(anyLast, UInt32) CODEC(LZ4),`ScopeSchemaUrl` SimpleAggregateFunction(anyLast, String) CODEC(LZ4),`MetricDescription` SimpleAggregateFunction(anyLast, String) CODEC(LZ4),`MetricUnit` SimpleAggregateFunction(anyLast, String) CODEC(LZ4),`MetricAttributes` SimpleAggregateFunction(anyLast, Map(String, String)) CODEC(LZ4),`MetricType` SimpleAggregateFunction(anyLast, Enum8('MetricTypeEmpty' = 0, 'MetricTypeGauge' = 1, 'MetricTypeSum' = 2, 'MetricTypeHistogram' = 3, 'MetricTypeExponentialHistogram' = 4, 'MetricTypeSummary' = 5)) CODEC(LZ4),`SumAggTemp` SimpleAggregateFunction(anyLast, Enum8('AggregationTemporalityUnspecified' = 0, 'AggregationTemporalityDelta' = 1, 'AggregationTemporalityCumulative' = 2)) CODEC(LZ4),`SumIsMonotonic` SimpleAggregateFunction(anyLast, Boolean) CODEC(LZ4),)ENGINE = AggregatingMergeTree() PARTITION BY toYYYYMM(TimeUnix)ORDER BY (TimeUnix, MetricName, MetricHash)
其中一些字段可能需要额外说明。
在设计上,我们采用了 ClickHouse AggregatingMergeTree 引擎来构建指标元数据表,这也是 ClickHouse 在其 TimeSeries 引擎的 Tags 表中使用的方式。该引擎支持持续写入数据的同时进行自动去重,对于我们这种属性变化不频繁的数据结构(如资源属性、Scope 属性和指标属性),这种去重机制可以显著减少查询所需处理的数据量。
其中的关键字段 MetricHash,封装了多个核心属性。因为我们可以保证在相同的 MetricHash 值下,这些属性不会发生变化,所以我们可以安全地对它使用 anyLast 聚合函数来提取最新值。
此外,为了记录某个指标时间序列首次出现和最后出现的时间,我们还添加了 FirstSeen 和 LastSeen 字段,分别使用 min 和 max 聚合函数。这些时间范围信息可用于在查询时快速排除不在查询范围内的无效指标,进一步提升执行效率。
我们在主键中引入了 TimeUnix 字段(类型为 Date,精度为天),作为 ORDER BY 子句的一部分。虽然这种设计初看可能不太直观,但它的作用非常关键。由于我们将指标元数据按月进行分区,若主键中缺少时间字段,查询时可能不得不扫描整整一个月的数据。通过增加 TimeUnix 字段,我们可以结合查询中的时间范围过滤条件,有效减少需处理的数据量,提升性能。
值得注意的是,使用 AggregatingMergeTree 时存在一个常被忽略的重要特性:数据合并(merge)操作并不会在查询执行前强制触发。如果忽略这个细节,可能导致查询结果不准确。例如,某个时间序列在查询时间段前后都有数据,但由于中间没有新数据写入,记录未被合并,导致其 FirstSeen 和 LastSeen 无法覆盖整个时间范围,就可能被错误地排除在查询结果之外。
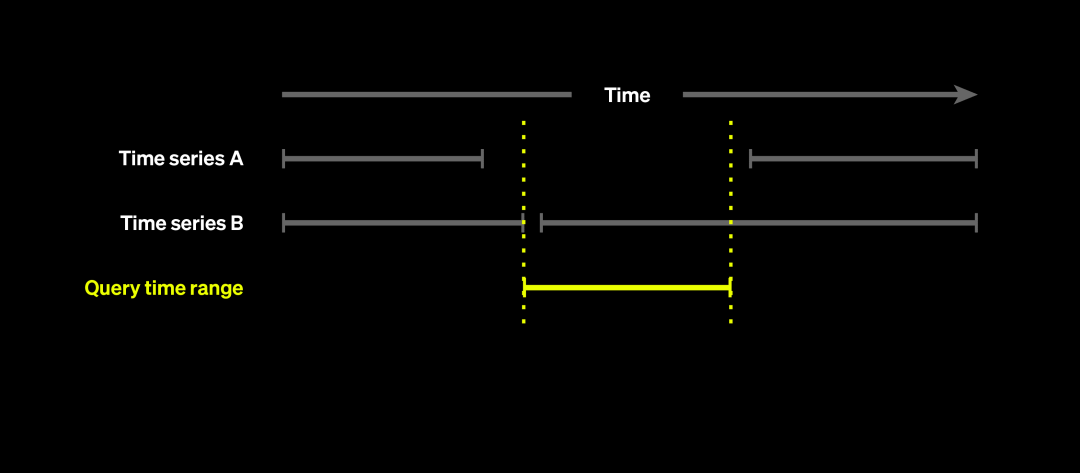
因此,在查询基于 AggregatingMergeTree 构建的表时,应始终采取以下两种方法之一:使用 GROUP BY 并配合与表定义一致的聚合函数处理字段;或者使用 FINAL 关键字强制触发合并逻辑(但通常推荐使用前者以提升性能)。
数据采样策略与评估实践
在 Dash0,我们始终优先保障数据的准确性,因此仅在特定场景中使用采样策略。采样主要用于响应时间较长的查询,帮助用户快速获取初步结果,而完整查询则在后台异步执行。这项机制目前已应用于我们新发布的 triage 故障排查功能中。
为了在 ClickHouse 查询中使用 SAMPLING 子句,表结构必须提前进行设计,并确保采样字段包含在排序键中。这意味着我们往往需要新建表而不是直接修改现有表结构。如何选择一个既适用于普通查询,又能高效支持采样的排序方式,是实现采样时面临的关键挑战。
在实施采样功能时,我们有以下建议:
对不同排序方式进行全面基准测试,确保不会对现有性能产生负面影响; 使用 EXPLAIN indexes=1 命令分析不同排序键和索引组合对查询路径的影响;
此外,还需要注意采样列的数据类型会影响采样比率。虽然你可以选择从 UInt8 到 UInt64 的任意类型,但 ClickHouse 会假定 UInt8 有 256 个取值组。比如,即使你通过 xxh3(SpanId) % 10 构造出仅有 10 个取值的列,ClickHouse 依然会认为有 256 个分组存在,从而导致如 0.1 采样率的查询条件为 WHERE
因此,采样列的数据类型决定了最小可用采样率。以 UInt8 为例,最低采样比例大约为 0.003。若低于该值,ClickHouse 会认为无法执行采样,而是全量扫描数据。
排序策略对比与验证
在已知这些前提后,我们基于已有排序方式,设计并评估了多个新的排序键。原始 spans 表的排序键为:ORDER BY (ResourceHash, Timestamp)
为进行测试,我们设定了如下几种排序方式并分别创建对应数据表:
- traces2:toStartOfHour(Timestamp), ResourceHash, xxh3(SpanId)
- traces3:ResourceHash, SpanName, xxh3(SpanId)
- traces4:ResourceHash, toStartOfHour(Timestamp), xxh3(SpanId)
- traces5:xxh3(SpanId) % 256, ResourceHash, Timestamp
每个表我们都加载了过去三天的数据,主要验证以下几个方面:
新表结构下的压缩效果是否合理,避免大幅增加存储开销; 普通查询的响应时间是否保持稳定; 启用采样后查询是否加速明显; 主索引与次级索引是否生效,输出结果是否一致;
为了更方便地执行基准测试(我们使用的是 clickhouse-benchmark 工具),我们将常用的查询语句整理成多个独立的 SQL 文件,例如下面这个,用于获取按时间戳排序的 spans 列表:
WITH subtractHours(toDateTime('${QUERY_TS}'), ${QUERY_DURATION} + 1) AS startTime, subtractHours(toDateTime('${QUERY_TS}'), 1) AS endTimeSELECTResourceHash,Timestamp,SpanAttributes,SpanNameFROM ${QUERY_TABLE} ${QUERY_SAMPLE}WHERE (Timestamp >= startTime) AND (Timestamp <= endTime) AND (ParentSpanId = '')ORDER BYTimestamp ASCLIMIT 50FORMAT NullSETTINGS use_query_cache=false;
我们将典型查询封装为 SQL 脚本,替换变量后可用于不同表和时间范围的自动测试。
此外,测试中使用 FORMAT Null 以排除客户端响应耗时,使查询耗时更接近真实的执行性能。
我们用于触发查询的脚本如下:
#!/usr/bin/env bashTIMESTAMP=$(date +%Y-%m-%d-%H-%M)RESULTS_FOLDER="results"mkdir -p ${RESULTS_FOLDER}# Some fields replaced in the scriptsQUERY_TS=$(date --utc +'%F %H:%M:%S')for DURATION in "1" "12" "24" "72"; dofor FILE in *.sql; dofor TABLE in traces traces2 "traces2 SAMPLE 0.01"; doOUTPUT_FILENAME="${FILE#queries/}"OUTPUT_FILENAME="${OUTPUT_FILENAME%.sql}"OUTPUT_FILENAME="${RESULTS_FOLDER}/${TIMESTAMP}-${OUTPUT_FILENAME}-${DURATION}h-${TABLE}.txt"echo "##################################################"echo "Running benchmark for ${FILE} and table ${TABLE}"# Need to export the template variables otherwise not available in the subshellexport QUERY_TABLE=${TABLE%%SAMPLE*}export QUERY_SAMPLE=${TABLE#$QUERY_TABLE}export QUERY_DURATION=${DURATION}export QUERY_TSQUERY=$(envsubst < ${FILE})# Print the query also to the OUT_FILE to have it for referenceecho -e "Query:\n\n${QUERY}\n\n" | tee "${OUTPUT_FILENAME}"# Remove all linebreaks from the query, but add one at the end for ClickHouseecho "${QUERY}" | tr '\n' ' ' | xargs -0 printf '%s\n' | clickhouse-benchmark --cumulative --user otel --password otel --host localhost --port 9000 -i 10 2>&1 | tee --append "${OUTPUT_FILENAME}"sleep 5donedonedone
通过这套基准测试流程,我们观察到一些值得关注的结果:
“traces2”、“traces3” 和 “traces4” 三张表的压缩率差别不大,但都不如原始表 “traces5” 表(排序键为 xxh3(SpanId) % 256, ResourceHash, Timestamp)在采样查询中速度最快,因为它可以高效跳过大量数据块;但在执行普通查询时性能最差 “traces4” 表略优于 “traces2” 和 “traces3”,但差距不大 对于时间范围小于 12~24 小时的查询,采样效果提升并不明显
综合这些结果,我们最终选择了排序键:ResourceHash, toStartOfHour(Timestamp), xxh3(SpanId)。另外我们发现,在 Timestamp 上增加一个 minmax 类型的次级索引,对查询性能提升最为显著。这也解释了为什么原始表查询性能较好,而 “traces5” 表表现较差 —— 因为其 Timestamp 字段被打散分布,难以利用索引优化查询。
其他经验总结
最后,我们快速回顾一些其他经验教训,这些看起来可能不太明显,但却可能带来显著的差异。
索引的使用
跳过数据的索引(data skipping indexes)可以显著减少 ClickHouse 需要读取的数据块(granules)数量,但其效果依赖于使用兼容的子句和函数。更具体地说,不同类型的 Bloom Filter 支持不同的函数。虽然 Bloom Filter 在正向匹配方面表现良好,但无法用于优化负向匹配。
在索引 Map 内容时,可以创建如下类型的索引:
INDEX idx_attr_key mapKeys(Attributes) TYPE bloom_filter(0.01) GRANULARITY 1
然而,查询语法的细节非常关键——尤其是在判断 Map 类型中某个 key 是否存在时:
has(Attributes, 'some_key') 可以正确利用 Bloom Filter Attributes['some_key'] = ''(空字符串)则无法使用该索引。因为一个有意设置为空的值与某个 key 不存在在语义上是相同的,这种情况无法区分,因此 Bloom Filter 无法用于后者。
为了确保查询能够充分利用现有索引,可以在查询前加上前缀 EXPLAIN indexes=1
例如,当仅查找 Attributes['error'] 值非空的记录(本质上相当于判断 key 是否存在)时,EXPLAIN 查询如下:
EXPLAIN indexes = 1SELECT Attributes['error']FROM logsWHERE (toDateTime(Timestamp) >= subtractMinutes(now(), 10)) AND (NOT ((Attributes['error']) = ''))Query id: 6b792380-5937-4cb7-9617-c846a4543895┌─explain──────────────────────────────────────────────────────────────────────┐│ Expression ((Project names + Projection)) ││ Expression ││ ReadFromMergeTree (logs) ││ PrimaryKey ││ Keys: ││ Timestamp ││ Condition: and((toDateTime(Timestamp) in [1741693620, +Inf))) ││ Parts: 11/11 ││ Granules: 3030/6868 ││ Skip ││ Name: idx_timestamp ││ Description: minmax GRANULARITY 1 ││ Parts: 9/11 ││ Granules: 1715/3030 │└──────────────────────────────────────────────────────────────────────────────┘
此时 idx_attr_key 索引并未被使用。反之,如果我们在查询中额外加入 has(Attributes, 'error') 条件,则可以触发该索引:
EXPLAIN indexes = 1SELECT Attributes['error']FROM logsWHERE (toDateTime(Timestamp) >= subtractMinutes(now(), 10))AND (NOT ((Attributes['error']) = ''))AND has(Attributes, 'error')Query id: a5a6181f-9359-49d7-ab78-921e1cc64c86┌─explain──────────────────────────────────────────────────────────────────────┐│ Expression ((Project names + Projection)) ││ Expression ││ ReadFromMergeTree (logs) ││ PrimaryKey ││ Keys: ││ Timestamp ││ Condition: and((toDateTime(Timestamp) in [1741693620, +Inf))) ││ Parts: 11/11 ││ Granules: 3030/6868 ││ Skip ││ Name: idx_timestamp ││ Description: minmax GRANULARITY 1 ││ Parts: 9/11 ││ Granules: 1715/3030 ││ Skip ││ Name: idx_attr_key ││ Description: bloom_filter GRANULARITY 1 ││ Parts: 8/9 ││ Granules: 279/1715 │└──────────────────────────────────────────────────────────────────────────────
定期检查索引使用情况,有助于在表结构和访问模式变化后,持续维持良好的查询性能。
JOIN 和子查询的优化建议
在当前版本的 ClickHouse 中,我们建议尽可能减少使用 JOIN 操作(尽管官方团队正在该方向积极优化,未来表现会持续改善)。在大多数情况下,ClickHouse 使用子查询往往能获得更好的性能表现。不过,当确实需要使用 JOIN 时,可参考以下几点优化建议:
- 选择合适的 JOIN 类型:如果左表中的某个值在右表中能匹配多条记录,JOIN 操作会返回多行结果,也就是所谓的“笛卡尔积”。如果你的业务场景只需要匹配一条任意结果,可以使用 ANY JOIN(例如 LEFT ANY JOIN),相比标准 JOIN,它更高效、内存占用也更低。你可以参考 ClickHouse 的官方文档和技术博客,选择最适合的 JOIN 类型。
- 控制 JOIN 表的数据量:JOIN 操作的执行性能与参与表的大小直接相关。为了减少处理数据量,可以在 WHERE 或 JOIN ON 子句中加入更多过滤条件。ClickHouse 的查询优化器通常会尽可能将过滤条件下推至 JOIN 之前执行。如果未能自动下推(可使用 EXPLAIN 检查),可以将其中一侧改写为子查询,强制优化器进行下推处理。此外,直接在 JOIN ON 中加入时间或业务字段的条件(例如:ON a.ServiceName = b.ServiceName AND b.Timestamp BETWEEN startTime AND endTime)也有助于降低 JOIN 的数据扫描量。
- 外连接时使用默认值替代 NULL:在执行外连接(如 LEFT JOIN、RIGHT JOIN 或 FULL OUTER JOIN)时,如果某一侧未能找到匹配项,ClickHouse 默认会用特殊标记替代,遵循 SQL 标准为 NULL。但在 ClickHouse 中,这要求使用 Nullable 类型字段,带来额外的内存开销和性能损失。为提升效率,你可以设置参数 join_use_nulls = 0,让系统使用字段默认值作为未匹配占位标志,避免引入 Nullable 类型。
随着 ClickHouse 团队在 JOIN 性能上的不断投入,以上建议在未来可能会逐渐被替代或简化。我们建议持续关注 ClickHouse 的更新文档与发布日志,以获取最新的优化能力。
Dash0 选择 ClickHouse 作为其 OpenTelemetry 原生可观测性平台的核心存储引擎,充分体现了架构设计上的专业性与前瞻性。依托 ClickHouse 的列式架构、高压缩比与灵活的数据模型,我们构建了一个既能承载海量高基数遥测数据,又能保持良好性能表现的可观测性平台。
我们通过合理设计主键、精心构建聚合策略,有效实现了查询效率与存储空间的双重优化。在运维层面,我们在存储分层、采样机制、索引技术与 JOIN 性能等方面所做的工程权衡,展现了我们结合大规模数据场景与底层引擎能力的深厚经验。随着 Dash0 的持续发展,我们坚信基于 ClickHouse 构建的技术底座,将助力平台在面对客户可观测性需求不断增长的同时,依然能够提供稳定、高效、快速的查询体验,保障系统监控与故障排查的核心能力。

好消息:ClickHouse Shenzhen User Group第2届 Meetup 已经开放报名了,将于2025年05月17日在深圳BIO ONE创新中心会议室(深圳市南山区海天一路17-6软件产业基地4栋B座1楼大堂)举行,扫码免费报名

/END/
 注册ClickHouse中国社区大使,领取认证考试券
注册ClickHouse中国社区大使,领取认证考试券

ClickHouse社区大使计划正式启动,首批过审贡献者享原厂认证考试券!
试用阿里云 ClickHouse企业版
轻松节省30%云资源成本?阿里云数据库ClickHouse 云原生架构全新升级,首次购买ClickHouse企业版计算和存储资源组合,首月消费不超过99.58元(包含最大16CCU+450G OSS用量)了解详情:https://t.aliyun.com/Kz5Z0q9G

征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


