




摘要:中断约40分钟,此次事件背后的原因竟是一次看似普通的对数据库基础设施的改动或升级,后来他们回滚数据库……
GitHub,全球最大的代码托管平台,昨晚崩了。
“所有GitHub服务经历严重的中断,”GitHub的状态页面上写道。

此次事件背后的原因,据GitHub的说法,为了变得更好,对数据库基础设施进行了一次改动或升级,结果没弄好,导致关键服务突然跟数据库断了联系,反而把自家网站给整崩溃了。不过还好,他们反应快,赶紧把改的东西都撤了回去,网站就慢慢恢复了。
据外媒报道,中断始于UTC时间23:00(PT时间16:00)。受影响的服务包括:GitHub Actions、Pages、Issues、Pull Requests、Copilot 和 Codespaces、Packages、Git操作以及 Webhooks。
就连GitHub的网站和它的API接口也进不去了,网站上就显示个独角兽和错误消息,想用SSH进仓库也进不去。
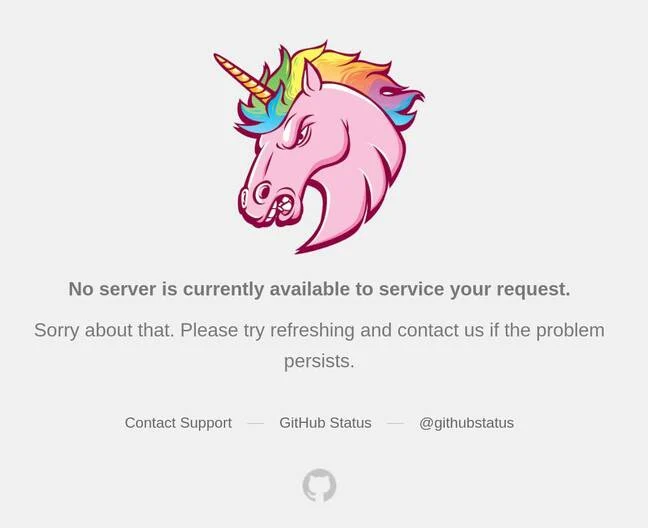
GitHub首页在故障期间的样子……
网站首页上直接写了:“现在没人能帮你处理请求,不好意思。你刷新试试,还不行就联系我们。”
还好,没过多久,到UTC时间23:29,GitHub决定回滚数据库。UTC时间 23:45,它开始恢复正常运行。
“数据库基础设施的改动正在被回滚,”该公司在更新中说,“现在服务好点了,我们还在盯着,确保它完全恢复正常。”
看来,就算是再牛的公司,再顶尖的技术团队,也有失手的时候。这次事件也给行业敲响了警钟,必须高度重视系统的稳定性和安全性。同时,也提醒了其他技术公司在进行关键基础设施改动时要格外谨慎,要重视并加强测试流程,避免此类事件的发生。
- END -
延伸阅读


讲述数据领域的故事

欢迎订阅老鱼笔记
✬如果你喜欢这篇文章,欢迎分享到朋友圈✬
评论功能现已开启,灰常接受一切形式的吐槽和赞美☺
