




摘要:亚马逊为什么选择Ray来接替Spark?如何实现年节省超1亿美元?
大规模的分布式计算框架迁移绝非易事,这事儿得保证跟以前的版本兼容,还得达到性能上的要求,同时还要解决扩展性的问题,并且始终要提防着别给生产环境带来什么大乱子。如果要从一个每天处理exabytes级别的数据、为企业提供关键决策依据、有成千上万的用户依赖、还必须保证几乎不宕机的系统上做迁移,那问题就更复杂了。
但这正是亚马逊零售业务数据技术团队(BDT)现在正在干的事情。他们刚启动了迁移计划,悄悄地把一些最大的生产业务智能(BI)数据集从Apache Spark迁移到Ray,目的是为了缩短数据处理时间和降低成本。作为这个过程的一部分,他们还把自己开发的一个重要组件(叫做Flash Compactor)贡献给了Ray的开源项目DeltaCAT。这个贡献对于让其他用户在使用Ray管理像Apache Iceberg、Apache Hudi和Delta Lake这样的开放数据目录时也能获得类似的好处来说,是个重要的第一步。
那么,究竟是什么让他们下定决心冒这么大的风险?再者,他们为什么选择Ray一个以机器学习(ML)出名而不是大数据处理的开源框架来接替Spark完成这项任务?
一个巨大的湖仓一体(Lakehouse)
2018年,亚马逊完成了从Oracle数据库的大迁移,把7500个Oracle数据库实例中的大部分用于在线交易处理(OLTP)的工作负载都搬到了Amazon Aurora。一些写入特别频繁的任务则转到了Amazon DynamoDB。
然而,根据亚马逊的博客作者所述,包括亚马逊首席工程师Patrick Ames、Anycale的前首席开发倡导者Jules Damji以及Anycale的开源工程负责人Zhe Zhang,还有一个庞大的Oracle数据仓库留了下来,亚马逊的首席技术官Werner Vogels说这是地球上最大的Oracle数据仓库,规模达到了50PB。亚马逊零售业务数据技术(BDT)团队用他们自己的Lakehouse平台替换了这个Oracle数据仓库。
亚马逊建造了一个Lakehouse平台来取代其Oracle数据仓库(图片来自亚马逊博客)
这个Lakehouse平台主要构建在AWS自家的基础设施之上,包括Amazon S3、Amazon Redshift、Amazon RDS和通过Amazon EMR使用的Apache Hive。
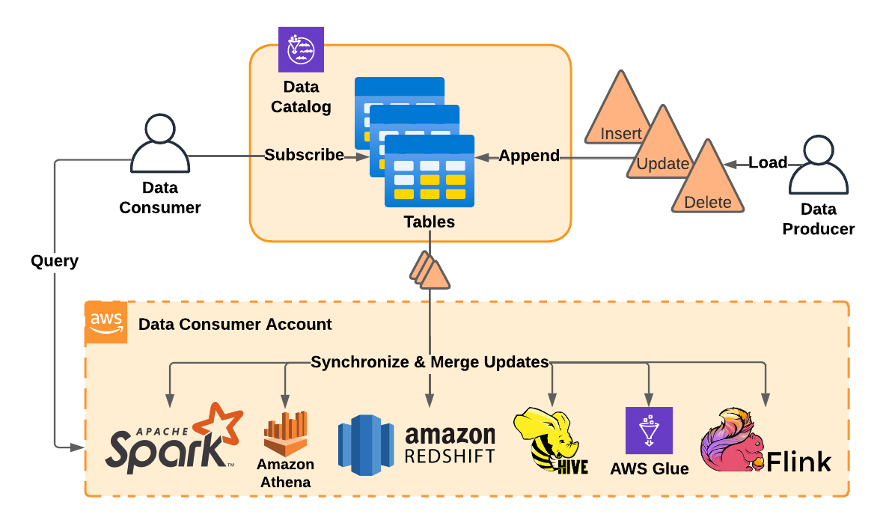
BDT团队还搞了个“表订阅服务”,让分析师和其他数据用户可以订阅存储在S3的数据目录表,然后用他们喜欢的框架来查询数据,这些框架包括开源引擎如Spark、Flink和Hive,还有Amazon Athena(无服务器Presto和Trino)和Amazon Glue(可以把它看作是Apache Iceberg、Apache Hudi或Delta Lake的早期版本)。
但BDT团队很快又遇到了新问题:S3中的无限制数据流,包括插入、更新和删除操作,所有这些都需要在用于业务关键分析之前进行压缩。
压缩问题
“每个订阅者选择的计算框架都需要在读取时动态地应用或‘合并’所有这些更改,以得出正确的当前表状态,”亚马逊的博客作者写道。“不幸的是,这些用于插入、更新和删除的记录变更数据捕获(CDC)日志已经变得过于庞大,无法在最大规模的集群上在读取时完全合并。”
BDT团队还遇到了“难以处理的问题”,比如有数百万个非常小的文件需要合并,或者只有少数几个大文件。“对最大表的新订阅可能需要数天或数周才能完成合并,或者根本无法完成,”他们写道。
他们最初用于压缩这些无限制的S3文件流的工具是在Amazon EMR上运行的Apache Spark(EMR过去代表Elastic MapReduce,但现在不再代表任何缩写)。亚马逊的工程师构建了一个管道,Spark会运行一次合并操作,“然后写回一个经过优化的表版本供其他订阅者使用,”他们在博客中写道。这有助于减少读取时合并的记录数,从而有助于控制问题。
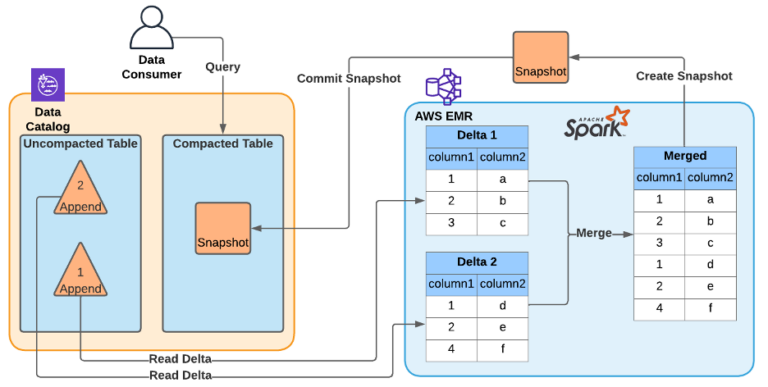
亚马逊面临着S3中无限制数据流问题,这促使他们开发了一个Spark压缩器(图片来亚马逊博客)
然而,工程师们写道,没过多久,Spark压缩器就开始显露出压力迹象。亚马逊的Lakehouse不再仅仅是50PB,而是已经超越了exascale级的门槛,即1000PB,而Spark压缩器“开始显现出一些老旧的迹象”。
基于Spark的系统已无法跟上庞大的工作负载,开始错过服务水平协议(SLA)。工程师们不得不手动调整Spark作业,但这很困难,因为“Apache Spark成功地(不幸的是在这种情况下)抽象掉了大多数低级数据处理细节,”亚马逊的工程师写道。
在考虑过在Spark之外构建自己的定制压缩系统后,BDT团队考虑了另一种他们刚刚了解到的技术:Ray。
Ray的登场
Ray在2017年从加州大学伯克利分校的RISELab崭露头角,作为一个有前景的新型分布式计算框架。它是由加州大学伯克利分校的研究生Robert Nishihara和Philipp Moritz,以及他们的导师Ion Stoica和Michael Jordan共同开发的。Ray提供了一种新颖的机制,可以以多层方式运行任意计算机程序。大数据分析和机器学习工作负载无疑是Ray关注的重点,但由于Ray的通用灵活性,它并不局限于这些领域。
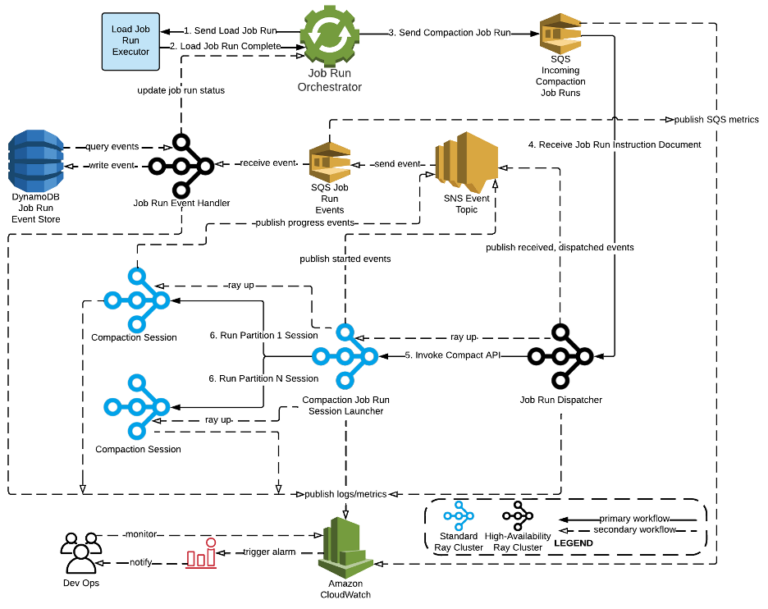
亚马逊的工程师构建了自己的Ray集群来管理压缩工作(图片来自亚马逊博客)
“我们正在努力做的是让在云端、集群上编程变得像在你的笔记本电脑上编程一样简单,这样你就可以在你的笔记本电脑上编写应用程序,并在任何规模上运行它,”2020年Datanami值得关注的人物Nishihara在2019年告诉我们。“你可以在数据中心运行相同的代码,而不必过多考虑系统基础设施和分布式系统。这就是Ray想要实现的。”
亚马逊BDT团队的成员们无疑对Ray在扩展机器学习应用方面的潜力感到兴趣,这无疑是当今地球上最大、最复杂的分布式计算问题之一。但他们也看到,Ray可能有助于解决他们的压缩问题。
亚马逊的博客作者列出了Ray的积极特性:
“Ray的直观的任务和Actor API、水平可扩展的分布式对象存储、支持节点内零拷贝对象共享、高效的局部感知调度器以及自动扩展集群,提供了解决他们在Apache Spark和内部表管理框架中面临的许多关键限制的方法。”
Ray胜出
亚马逊在2020年开始将Ray用于其压缩问题的概念验证(POC),结果相当不错。他们发现,经过适当的调优,Ray能处理比Spark大12倍的数据集,成本效率提高了91%,而且每小时处理的数据量是Spark的13倍。
亚马逊的博客作者写道:“这些成果得益于多种因素,包括Ray减少了任务管理和垃圾回收的开销、利用节点内零拷贝对象交换进行位置感知的混洗,以及通过细粒度自动扩展更好地利用了集群资源。但最关键的因素是Ray编程模型的灵活性,这让亚马逊能够定制一个分布式应用程序,专门针对高效运行压缩操作进行优化。”
亚马逊在2021年继续与Ray合作。那一年,亚马逊团队在Ray峰会上展示了他们的工作,并将他们的Ray压缩器贡献给了Ray DeltaCAT项目,目的是支持“其他开放目录,如Apache Iceberg、Apache Hudi和Delta Lake”,博客作者写道。
到2022年,亚马逊已将Ray用于一项新服务,该服务用于分析产品数据目录中表格的数据质量。他们逐步解决了Ray产生的错误,并努力将Ray工作负载集成到EC2中。到年底,从Spark迁移到Ray的工作正式开始,工程师们写道。到2023年,Ray已经开始作为Spark的影子版本运行,并允许管理员根据需要在这两者之间来回切换。
全面迁移与结果
到2024年,亚马逊已经全面启动了其全EB级Lakehouse从Spark向Ray的迁移工作。Ray压缩了“来自亚马逊S3的超过1.5EiB的Apache Parquet输入数据,这相当于合并和切片了超过4EiB的相应内存中的Apache Arrow数据”,他们写道。“处理这一数据量的工作,在包含多达26,846个vCPU和每个集群210TiB RAM的Ray集群上,需要超过10,000年的亚马逊EC2 vCPU计算时间。”
亚马逊继续每天使用Ray压缩超过20PiB的S3数据,每天运行1,600个Ray作业,亚马逊的博客作者写道。“现在,平均每个Ray压缩作业在7分钟内就能完成,包括读取超过10TiB的亚马逊S3输入数据、合并新表更新,并将结果写回S3,这还包括了集群的搭建和拆除时间。”
这为亚马逊带来了巨大的成本节省。该公司估计,如果它是一个标准的AWS客户(而不是这些数据中心的所有者),那么它将节省220,000年的EC2 vCPU计算时间,相当于每年节省1.2亿美元。
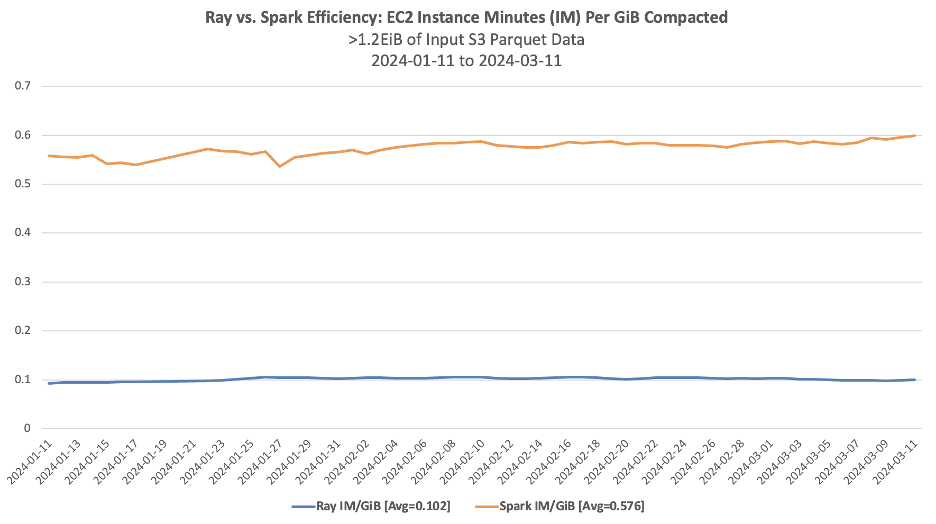
效率对比图
不过,虽然这些结果看起来很有前景,但仍有很大的改进空间。目前,BDT仅使用Ray来更新其数据目录表中的少数几个表,他们希望在将更多表迁移到Ray压缩之前,看到更长且一致的可靠性记录。例如,在2023年,Ray的首次压缩作业成功率比Spark低了多达15%,而在2024年则低近1%。这意味着Ray平均需要更多的压缩作业重试次数才能成功应用新表更新,并且在规模扩大时需要更多的手动操作。
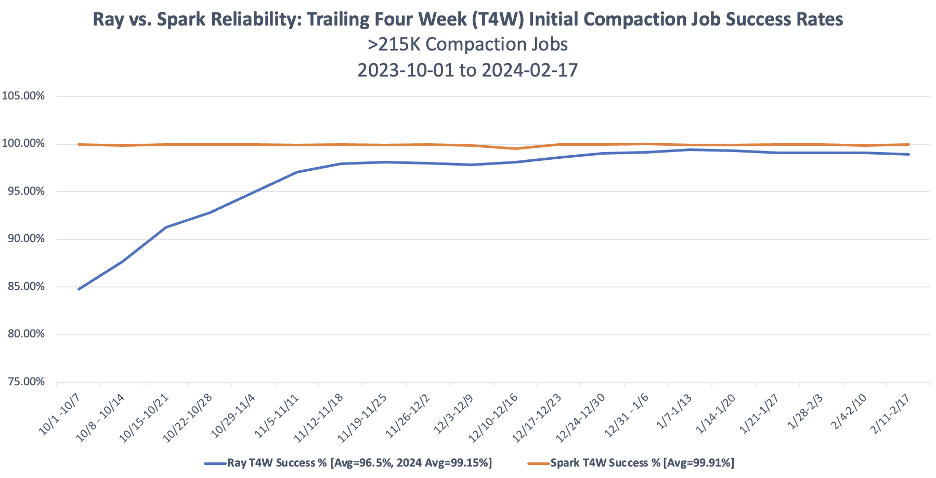
可靠性对比图
尽管Ray在2024年正在缩小与Apache Spark之间的可靠性差距,其平均首次作业成功率达到了99.15%,但这仍然落后于 Apache Spark 的平均首次作业成功率 99.91%,差距约为 0.76%。此外,集群规模的调整也面临挑战,难以在效率和稳定性之间找到最佳平衡点。
为了更好地理解这一点,我们可以看看BDT的Ray压缩集群内存利用率。在 2024年的第一季度里,BDT为所有正在进行的Ray压缩作业分配了总共 36TiB的集群内存,但他们实际使用的内存大约是19.4TiB。这意味着他们的平均内存利用率只有54.6%。由于内存是他们的瓶颈资源,因此其他资源如 CPU、网络带宽和磁盘空间的平均利用率就更低了。可用资源与实际使用资源之间的这个差距导致Ray相对于Apache Spark的实际成本效率提升低于它的潜在能力。
举个例子,如果BDT能够将其 Ray压缩器优化到平均使用90%的可用集群内存,那么相对于Apache Spark的成本效率提升也将从82%提升到超过 90%。
因此,BDT面临的挑战不仅在于提高Ray的可靠性,还包括优化集群资源的利用率,以便在保持高效率的同时实现更高的稳定性。这可能需要进一步调整集群配置、优化作业调度策略以及改进Ray压缩器的性能。
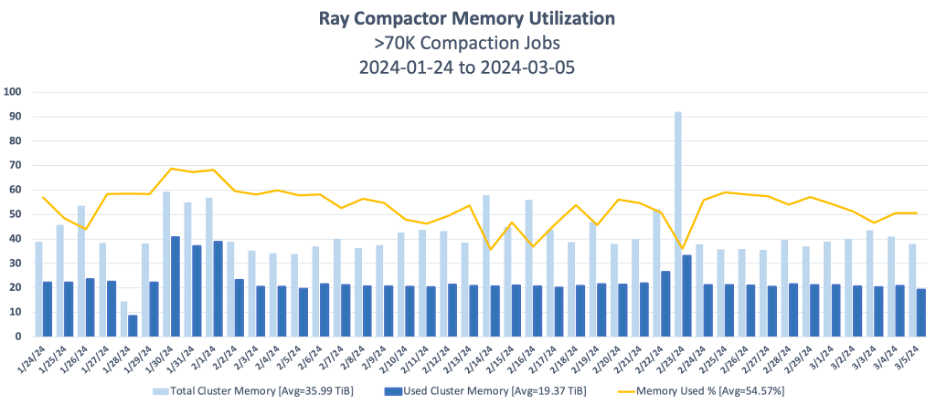
所以,这些结果是否意味着你也应该开始把所有Apache Spark的数据处理任务迁移到Ray上呢?嗯,可能还不至于,至少现在还不用。像 Apache Spark这样的数据处理框架提供了丰富的抽象层,对于日常使用的场景来说依然足够好。目前也没有一条现成的道路可以让你自动地把Apache Spark应用转换成在Ray上运行效率相当甚至更好的原生应用。
不过,亚马逊在压缩方面取得的成绩,表明Ray有可能成为世界级的数据处理框架,同时也是世界级的分布式机器学习框架。如果你像BDT那样遇到任何昂贵且操作起来很头疼的关键数据处理任务,那你可能真的要考虑把它们转到Ray上去,用专门构建的应用来处理这些问题。
参考资料:
https://www.datanami.com/2024/07/30/the-spark-to-ray-migration-that-will-save-amazon-100m-per-year/
https://aws.amazon.com/cn/blogs/opensource/amazons-exabyte-scale-migration-from-apache-spark-to-ray-on-amazon-ec2/
- END -
延伸阅读


讲述数据领域的故事

欢迎订阅老鱼笔记
✬如果你喜欢这篇文章,欢迎分享到朋友圈✬
评论功能现已开启,灰常接受一切形式的吐槽和赞美☺
