





题图:来自Dayan Quinteros on Unsplash
本文属于【降本增效】系列,是一篇国外降本增效的真实案例,为了避免广告,隐去了其中厂商及产品名,但被替代的数据库产品名保留,便于理解,本文目的是为了从这些案例中获得实际的经验和教训,了解在特定情境下如何应对和解决问题。
大家可能都遇到过这样的问题:现有的数据库跟不上服务的需求了。这时候,团队常常会考虑加个外部缓存来提速。这看起来是个明智的选择,但往往事与愿违,外部缓存就像是“双刃剑”,用不好反而会带来更多麻烦。
外部缓存的坑,你踩过几个?
延迟问题:你以为加个缓存能提速?其实,每次请求都得先问问缓存有没有,缓存没有才去找数据库。这不,路上就多了一个绊脚石,延迟可能就上去了。
成本问题:缓存得用DRAM吧?那价格可是比固态硬盘还要贵啊!除非你的数据集很小,否则全放内存里得花不少钱。
可用性下降:别觉得缓存就能高枕无忧了。缓存要是挂了或者数据失效,那数据库可就得遭殃了。因为数据库里的缓存本来就没啥用,还得从磁盘上读数据,延迟就更大了。
搞复杂了应用程序:加了缓存,你的应用就得处理更多情况。比如,怎么让缓存和数据库保持一致?客户端设置怎么匹配缓存和数据库的属性?这些问题都很难搞啊!
安全风险:缓存可是个新的攻击点哦!你怎么保证缓存里的数据安全、隔离和访问控制呢?
……
换个思路,让数据库自己搞定!
其实,一些团队已经发现,通过转向更高效的数据库,例如某些内置专门内部缓存的数据库,可以更有效地满足延迟要求,同时减少麻烦和降低成本。
让我们看看一些成功案例,这些团队如何通过升级数据库实现了显著的性能提升和成本节约。
案例一:SecurityScorecard
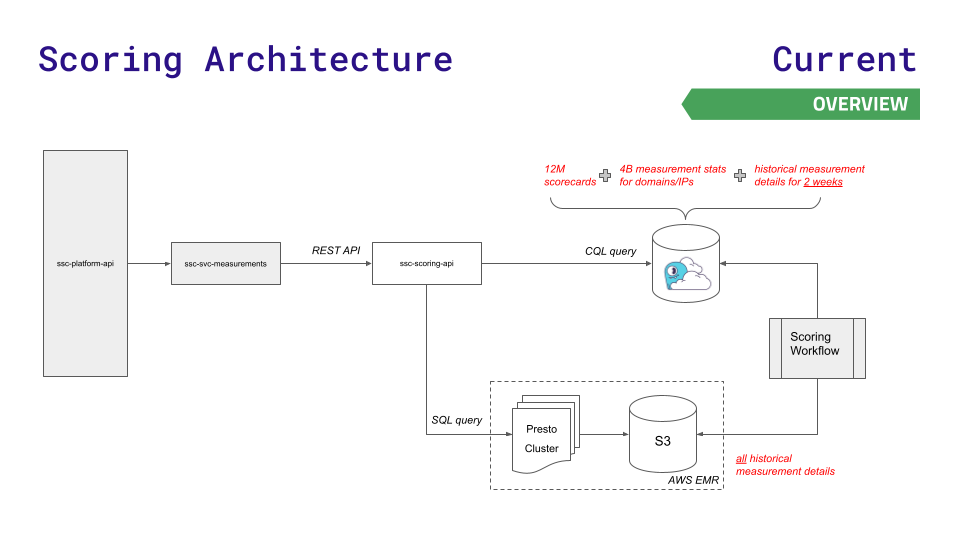
SecurityScorecard 是一家监控网络安全风险的公司,全球安全评级领导者。之前他们的数据架构还挺好用,但随着数据的飞速增长,就开始捉襟见肘了。
他们的平台API会从三个数据源中查询数据:Redis(用于更快地查找1200万份记分卡),Aurora(用于跨节点存储40亿条测量统计信息),以及基于Hadoop分布式文件系统的Presto集群(用于对历史结果进行复杂的SQL查询)。
在高吞吐量下,Aurora和Presto的延迟急剧增加。即使使用Redis的最大实例仍不够用,他们也不想处理Redis集群的复杂性。
为此,他们迁移到了一个更高效的数据库,并开发了新的评分API,将延迟敏感性较低的请求路由到Presto和S3存储。
结果呢?服务端点延迟减少了90%,生产事故减少了80%,每年还省下了100万美元的基础设施成本!数据处理速度提高也提高了30%,客户体验大幅改善。
案例二:IMVU
IMVU是一个超火的3D人物和场景聊天软件。它使人们能够通过桌面、平板电脑和移动设备上的3D头像进行互动。
为了满足不断增长的规模需求,他们觉得之前的MySQL+Redis+Memcached架构不够高效,于是开始寻找一个配置更简单、扩展更容易,并且如果成功的话,规模更容易扩大的解决方案。
“Redis做原型还行,但一旦大规模部署,成本就难以控制了。”IMVU的高级软件工程师Ken Rudy坦言,于是,他们转向了一个能将热点数据保存在内存中,而将其他数据存储在磁盘上的高效数据库。
这种迁移使他们能够在Redis可以处理的一百倍规模上保持相同的响应能力。”
案例三:Comcast
Comcast是美国传媒巨头,旗下主要有三项业务:有线电视、宽带网络和电话服务。康卡斯特有线电视(Comcast Cable)是美国最大的有线电视供应商;NBC环球(NBCUniversal),和天空电视台(Sky)。
Comcast的Xfinity服务为1500万户家庭提供服务,每天处理超过20亿次API调用(读取/写入)和超过2亿个新对象。七年来,该项目从支持3万台设备扩展到支持超过3100万台设备。
随着业务的飞速增长,他们面临了一个挑战:Cassandra数据库的长尾延迟问题。为了解决这个问题,他们曾在数据库前部署了60台缓存服务器,但维护这些缓存与数据库的一致性让管理员们头疼不已。
在努力应对这种方法的开销之后,他们转向了另外一个新型数据库。该数据库通过内部缓存机制最小化延迟峰值,让Comcast能够轻松告别外部缓存层,数据服务直接连接到数据存储,简单又高效。结果怎样?
他们用78个新型数据库节点替换了962个Cassandra节点,不仅提高了整体性能和可用性,还彻底摆脱了60台缓存服务器的负担。
最重要的是,长尾延迟降低了95%,处理能力翻倍,而运营成本仅为原来的60%!这为他们节省了高达250万美元的年度基础设施成本和人员开销。
写在最后
外部缓存确实能在某些情况下帮助减少延迟,比如用于静态内容和不需要持久性的个性化数据。但话说回来,如果你把它们放在数据库前面,往往可能会带来更多问题而不是好处。
这些问题包括成本增加、应用变得复杂、数据库请求增多,以及安全风险变大。但别担心,有一个简单的方法:重新考虑你的缓存策略,转向一个能在大规模下提供稳定低延迟的更强数据库。这样,团队不仅能简化基础设施、降低成本,还能轻松满足SLA,不再受外部缓存带来的各种麻烦和复杂性的困扰。
参考资料
https://thenewstack.io/why-and-how-teams-are-replacing-external-database-caches/
- END -
延伸阅读


讲述数据领域的故事

欢迎订阅老鱼笔记
✬如果你喜欢这篇文章,欢迎分享到朋友圈✬
评论功能现已开启,灰常接受一切形式的吐槽和赞美☺
