




一般来说,pgvector 为我们提供了两种类型的索引可供使用:
- hnsw
- ivfflat
核心问题是:我们什么时候需要哪种类型的索引,以及我们首先该如何创建这些索引?
通常来说,HNSW(多层图)在执行(“SELECT”)时速度更快,但在创建索引时速度会慢很多,我们稍后会看到。如果索引创建时间不是问题,那么 HNSW 绝对是一个不错的选择——但如果索引创建时间真的很重要呢?嗯,其实没那么重要。
索引包含向量的表
为了展示如何进行索引,我们使用下表,该表是通过上一篇文章中描述的矢量化过程创建的:
cybertec=# \d demo_wiki_emb_store
Table "public.demo_wiki_emb_store"
Column | Type | Collation | Nullable | Default
----------------+-------------+-----------+----------+-------------------
embedding_uuid | uuid | | not null | gen_random_uuid()
id | text | | not null |
chunk_seq | integer | | not null |
chunk | text | | not null |
embedding | vector(384) | | not null |
Indexes:
"demo_wiki_emb_store_pkey" PRIMARY KEY, btree (embedding_uuid)
"demo_wiki_emb_store_id_chunk_seq_key" UNIQUE CONSTRAINT, btree (id, chunk_seq)
Foreign-key constraints:
"demo_wiki_emb_store_id_fkey" FOREIGN KEY (id) REFERENCES wiki(id) ON DELETE CASCADE
让我们回顾一下这两个表的内容(=原始数据和向量数据)。包含维基百科数据的关系包含 640 万行数据,这些数据被分解成 4100 万个块,并被转换成向量:
cybertec=# SELECT count(*) FROM demo_wiki_emb;
count
----------
40961670
(1 row)
下一步,我们要为这些表创建索引。各种参数对于获得良好的索引性能至关重要。如果您想了解更多关于“PostgreSQL 中的索引创建调优”的信息,我们准备了一些相关的技术信息,希望能对大家有所帮助。
就我的情况而言,机器足够大,足以证明 maintenance_work_mem 的值相当高是合理的。这里需要注意的是:人们经常会问,如果并行创建索引会发生什么。这个参数是“每个 CREATE INDEX”还是“每个参与 CREATE INDEX 的进程”?答案是:这取决于您正在创建的索引类型。对于那些常用的索引类型,例如标准 B 树,它是允许的总内存量。但是,准确地说:索引类型可以自行决定 - 因此,对于所有不常用的索引类型,它可能并不总是相同的。
cybertec=# \timing
Timing is on.
cybertec=# SET maintenance_work_mem TO '32 GB';
SET
Time: 6.509 ms
无论如何,让我确保PostgreSQL正在使用多个进程来进一步加快该进程:
cybertec=# SET max_parallel_maintenance_workers TO 8;
SET
Time: 0.214 ms
最后,我们可以部署索引了。首先,我们将创建一个“HNSW”索引,使用余弦距离来组织索引内的数据:
cybertec=# CREATE INDEX ON demo_wiki_emb_store
USING hnsw (embedding vector_cosine_ops);
NOTICE: hnsw graph no longer fits into maintenance_work_mem after 15488425 tuples
DETAIL: Building will take significantly more time.
HINT: Increase maintenance_work_mem to speed up builds.
CREATE INDEX
Time: 44216893.145 ms (12:16:56.893)
说创建索引需要一段时间,这还只是轻描淡写。事实上,部署这个索引只需要半天时间。
监控 HNSW 索引创建
当索引创建开始时,我们会看到 PostgreSQL 自动启动几个并行进程来处理该索引。CPU 已满负荷运行,因为我们可以看到各种进程全速运行:
top - 18:51:56 up 2:09, 1 user, load average: 2.89, 3.06, 3.00
Tasks: 661 total, 9 running, 652 sleeping, 0 stopped, 0 zombie
%Cpu(s): 24.5 us, 2.5 sy, 0.0 ni, 72.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 128687.4 total, 62662.7 free, 43548.9 used, 57218.3 buff/cache
MiB Swap: 8192.0 total, 8192.0 free, 0.0 used. 85138.5 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
14311 hs 20 0 32.3g 321752 317456 R 99.7 0.2 3:16.71 postgres
14539 hs 20 0 32.2g 314060 310532 R 99.7 0.2 0:13.76 postgres
14541 hs 20 0 32.2g 313812 310028 R 99.7 0.2 0:13.75 postgres
14542 hs 20 0 32.2g 314152 310368 R 99.7 0.2 0:13.75 postgres
14545 hs 20 0 32.2g 314588 311060 R 99.7 0.2 0:13.74 postgres
14540 hs 20 0 32.2g 314276 310748 R 99.3 0.2 0:13.76 postgres
14543 hs 20 0 32.2g 313996 310724 R 99.3 0.2 0:13.75 postgres
14544 hs 20 0 32.2g 313728 309944 R 99.3 0.2 0:13.73 postgres
...
那么,问题来了:是什么占用了这么多 CPU?分析器揭开了谜底:
40.31% vector.so [.] vector_negative_inner_product
17.10% vector.so [.] HnswSearchLayer
15.87% postgres [.] pg_detoast_datum
2.31% vector.so [.] offsethash_insert_hash_internal
这一切都是关于一个被反复调用的函数;但它实际上做了什么呢?代码如下:
VECTOR_TARGET_CLONES static float
VectorInnerProduct(int dim, float *ax, float *bx)
{
float distance = 0.0;
/* Auto-vectorized */
for (int i = 0; i < dim; i++)
distance += ax[i] * bx[i];
return distance;
}
欢迎来到机器学习和人工智能领域一个非常重要的功能。在我们的实现中,它是在 CPU 内部运行的。当然,这也可以实现在 GPU 中,但考虑到它所基于的标准接口,实现起来并不容易。尽管仍有改进空间,但这至少意味着我们
已经很好地理解了这个问题。
最终的索引是什么样的?在回答这个问题之前,我们先检查一下表的大小:
List of relations
Schema | Name | Type | ... | Size |
--------+---------------------+-------+-----+---------+
public | demo_wiki_emb | view | | 0 bytes |
public | demo_wiki_emb_store | table | | 92 GB |
public | wiki | table | | 13 GB |
(3 rows)
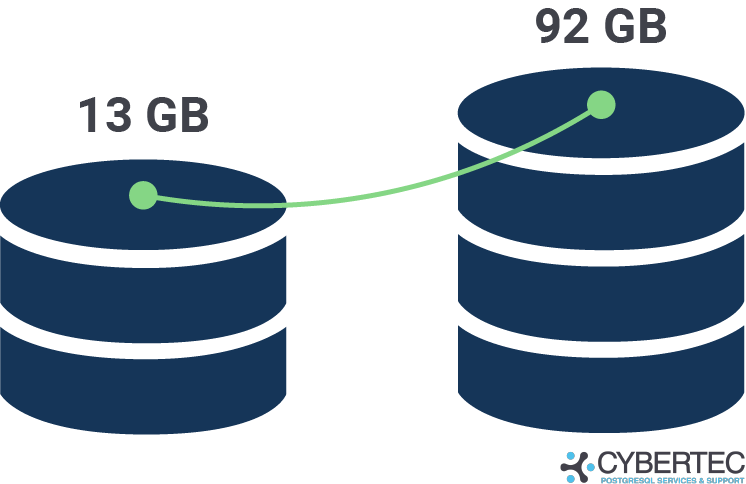
第一个观察结果是,矢量数据给场景增加了相当多的空间消耗。我们刚刚创建的索引也是如此:
PgSQL
cybertec=# SELECT pg_size_pretty(
pg_total_relation_size('demo_wiki_emb_store_embedding_idx'));
pg_size_pretty
----------------
77 GB
(1 row)
哇,索引有 77 GB,比底层数据多得多。
使用 pgvector 创建 IVFFLAT 索引
我们刚刚看到,使用 HNSW 需要很长时间。它确实提供了更好的查询性能,但耗时更长。
为了进行比较,我们可以看看 IVFFLAT 索引。以下是生成 IVFFLAT 索引的方法:
cybertec=# CREATE INDEX ON demo_wiki_emb_store
USING ivfflat (embedding vector_cosine_ops);
首先要注意的是,索引创建显示的 CPU 使用率完全不同。CPU 消耗要低得多。我们可以在最终结果中清楚地看到这一点:
Time: 2314162.345 ms (38:34.162)
哇,我们只用了 38 分钟就完成了所有操作。其中相当一部分时间都花在了 I/O 上,而 CPU 并没有在向量积上耗费数小时。然而,正如之前所说:虽然索引速度更快,但它确实会对后续性能产生影响,我们将在下一篇博文中讨论。
该索引的大小约为 63 GB,因此索引大小的差异实际上并不重要。
总结
对于那些对 PostgreSQL 和 pgvector 感兴趣的人来说,关键的一点是:并非所有索引都是平等创建的,决定使用哪种类型的索引会影响创建和查询方面的各个方面的性能(将在下一篇文章中详细介绍)。
原文地址:https://www.cybertec-postgresql.com/en/indexing-vectors-in-postgresql/
原文作者:Hans-Jürgen Schönig
