




前言
大家好,我是田螺。好久没给大家出大厂面试真题了,有位朋友去转转面试。我们本文一起来看下这份面试真题
1. Arraylist与LinkedList区别
可以从它们的底层数据结构、效率、开销进行阐述哈
ArrayList是数组的数据结构,LinkedList是链表的数据结构。 随机访问的时候,ArrayList的效率比较高,因为LinkedList要移动指针,而ArrayList是基于索引(index)的数据结构,可以直接映射到。 插入、删除数据时,LinkedList的效率比较高,因为ArrayList要移动数据。 LinkedList比ArrayList开销更大,因为LinkedList的节点除了存储数据,还需要存储引用。
2. Arraylist与LinkedList 的时间复杂度对比
ArrayList 时间复杂度
随机访问(get 操作)
时间复杂度:O(1) 理由:ArrayList 基于数组实现,元素在内存中是连续存储的,通过索引可以直接访问。 插入(add 操作,在尾部添加)
平均时间复杂度:O(1)(在容量足够的情况下) 最坏时间复杂度:O(n)(当数组需要扩容时,需要复制元素到新的数组) 理由:在大多数情况下,ArrayList 会在尾部添加元素,这不需要移动其他元素。但如果数组已满,则需要扩容,并复制所有现有元素到新的数组。 插入(add 操作,在指定位置插入)
时间复杂度:O(n) 理由:需要在插入位置后的所有元素向后移动一个位置。 删除(remove 操作,按索引删除)
时间复杂度:O(n) 理由:需要删除指定位置的元素,并将该位置后的所有元素向前移动一个位置。
LinkedList 时间复杂度
随机访问(get 操作)
时间复杂度:O(n) 理由:LinkedList 基于链表实现,元素在内存中不是连续存储的,需要从头节点开始遍历链表直到找到目标元素。 插入(add 操作,在尾部添加)
时间复杂度:O(1)(如果已知尾节点)或 O(n)(如果未知尾节点,需要遍历链表找到尾节点) 理由:在单向链表中,如果已知尾节点,则可以直接在尾节点后添加新节点。如果未知尾节点,则需要遍历链表找到尾节点。在双向链表中,通常会有指向头节点和尾节点的引用,因此可以在 O(1) 时间内完成尾部插入。 插入(add 操作,在指定位置插入)
时间复杂度:O(n) 理由:需要遍历链表找到插入位置的前一个节点,然后更改相关节点的引用。 删除(remove 操作,按索引删除或按值删除)
时间复杂度:O(n) 理由:需要遍历链表找到要删除的节点(按索引删除)或找到第一个匹配的节点(按值删除),然后更改相关节点的引用。
3. Arraylist里边有100个元素,有一个为2,如何移除?
如果直接这样for-each遍历移除,就会抛出ConcurrentModificationException异常:
// 尝试在遍历过程中使用list.remove(num)删除元素
for (Integer num : list) {
// 注意:这里直接使用了list.remove(num),而不是迭代器的remove方法, 这将导致ConcurrentModificationException异常
if (num == 2) {
list.remove(num);
}
}
Exception in thread "main" java.util.ConcurrentModificationException at java.base/java.util.ArrayList$Itr.checkForComodification(ArrayList.java:1013)
正确的实现:
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()) {
if (iterator.next() == 2) {
iterator.remove();
}
}
如果还是for + size遍历,是否可以呢?是否会报错呢。我跑了一个demo,正常运行:
for (int i = list.size() - 1; i >= 0; i--) {
Integer num = list.get(i);
if (num == 2) {
list.remove(num);
}
}
大家知道原因吗?欢迎评论区留言哈~~
4. HashMap和LinkedHashMap的区别?
底层数据结构
HashMap: 使用数组加链表实现,基于哈希函数将键映射到数组的索引。 LinkedHashMap: 在 HashMap 的基础上增加了一个双向链表,用于维护元素的插入顺序。
插入顺序
HashMap: 不保证插入顺序,遍历时元素的顺序可能是随机的。 LinkedHashMap: 保持元素的插入顺序,遍历时元素按照插入的顺序返回。
性能
HashMap: 平均时间复杂度为 O(1)(查找、插入、删除)。 最坏情况下时间复杂度可能退化到 O(n)。 LinkedHashMap: 平均时间复杂度为 O(1)(查找、插入、删除),略低于 HashMap。
内存开销
HashMap: 内存开销相对较小,仅需存储键、值和链表节点。 LinkedHashMap: 内存开销更大,因为还需存储指向前后节点的引用。
使用场景
HashMap: 适合于对元素顺序没有要求的场景,通常用于频繁查找的情况。 LinkedHashMap: 适合于需要保持插入顺序的场景,例如实现缓存机制(如 LRU 缓存)。
线程安全
HashMap: 不是线程安全的。 LinkedHashMap: 也不是线程安全的。可考虑使用 Collections.synchronizedMap()
或ConcurrentHashMap
。
迭代性能
HashMap: 迭代时没有固定的顺序。 LinkedHashMap: 迭代时按插入顺序返回元素。
5.concurentHashMap 17 18区别
特性 JDK 1.7 JDK 1.8 底层结构 分段锁 + 哈希表 桶数组 + 链表/红黑树 性能 性能较低,受限于分段数量 性能更高,CAS + 锁分离 锁机制 分段锁机制 锁分离机制,使用 CAS 操作 并发支持 支持多线程并发,但超过 16 个线程时性能下降 支持更高的并发,特别是在高并发场景下性能更佳 新特性 仅支持基本的线程安全操作 支持 forEach()
, compute()
, computeIfAbsent()
等新方法 线程安全性 在同一 Segment 中存在锁竞争问题 改进了锁机制,更好地支持高并发
5.concurentHashMap 17 18区别
| 特性 | JDK 1.7 | JDK 1.8 |
|---|---|---|
| 底层结构 | 分段锁 + 哈希表 | 桶数组 + 链表/红黑树 |
| 性能 | 性能较低,受限于分段数量 | 性能更高,CAS + 锁分离 |
| 锁机制 | 分段锁机制 | 锁分离机制,使用 CAS 操作 |
| 并发支持 | 支持多线程并发,但超过 16 个线程时性能下降 | 支持更高的并发,特别是在高并发场景下性能更佳 |
| 新特性 | 仅支持基本的线程安全操作 | 支持 forEach(), compute(), computeIfAbsent()等新方法 |
| 线程安全性 | 在同一 Segment 中存在锁竞争问题 | 改进了锁机制,更好地支持高并发 |
6. 编程题:输入字符串:12*34 输出 1234数字,不能用Integer parseint自带的api
我们可以手动解析字符串并忽略非数字字符。在 Java 中,我们可以利用字符串的字符操作来完成这一任务
public class Main {
public static void main(String[] args) {
String input = "12*34";
StringBuilder result = new StringBuilder();
// 遍历输入字符串
for (int i = 0; i < input.length(); i++) {
char ch = input.charAt(i);
// 检查是否为数字字符
if (Character.isDigit(ch)) {
result.append(ch);
}
}
// 输出拼接后的数字字符串
System.out.println(result.toString());
}
}
7. mysql一个用户表,有id,name,age字段,查询name数三个以上的用户,如何写SQL
SELECT name, COUNT(*) as name_count
FROM users_tab
GROUP BY name
HAVING COUNT(*) > 3;
8. 一次B+树索引树查找过程
假设有以下表结构,并且初始化了这几条数据
CREATE TABLE `employee` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`date` datetime DEFAULT NULL,
`sex` int(1) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_age` (`age`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into employee values(100,'小伦',43,'2021-01-20','0');
insert into employee values(200,'俊杰',48,'2021-01-21','0');
insert into employee values(300,'紫琪',36,'2020-01-21','1');
insert into employee values(400,'立红',32,'2020-01-21','0');
insert into employee values(500,'易迅',37,'2020-01-21','1');
insert into employee values(600,'小军',49,'2021-01-21','0');
insert into employee values(700,'小燕',28,'2021-01-21','1');
执行这条查询SQL,需要执行几次的树搜索操作?可以画下对应的索引树结构图~
select * from Temployee where age=32;
其实这个,这个大家可以先画出idx_age普通索引的索引结构图,大概如下:
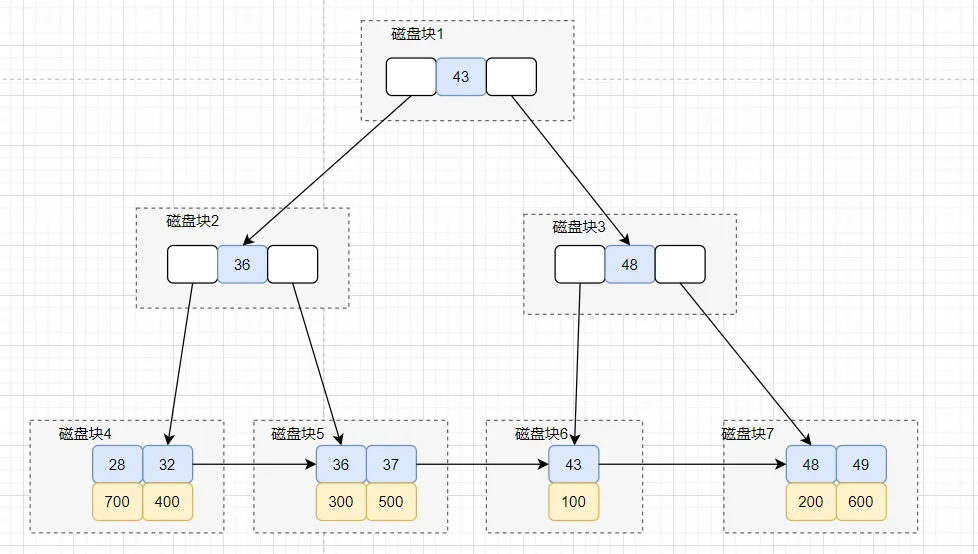
再画出id主键索引,我们先画出聚族索引结构图,如下:

这条 SQL 查询语句执行大概流程是这样的:
搜索idx_age 索引树,将磁盘块1加载到内存,由于32<43,搜索左路分支,到磁盘寻址磁盘块2。 将磁盘块2加载到内存中,由于32<36,搜索左路分支,到磁盘寻址磁盘块4。 将磁盘块4加载到内存中,在内存继续遍历,找到age=32的记录,取得id = 400. 拿到id=400后,回到id主键索引树。 搜索id主键索引树,将磁盘块1加载到内存,因为300<400<500,所以在选择中间分支,到磁盘寻址磁盘块3。 虽然在磁盘块3,找到了id=400,但是它不是叶子节点,所以会继续往下找。到磁盘寻址磁盘块8。 将磁盘块8加载内存,在内存遍历,找到id=400的记录,拿到R4这一行的数据,好的,大功告成。
9. 聚簇索引与非聚簇索引的区别
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。它表示索引结构和数据一起存放的索引。非聚集索引是索引结构和数据分开存放的索引。
接下来,我们分不同存存储引擎去聊哈~
在MySQL
的InnoDB
存储引擎中, 聚簇索引与非聚簇索引最大的区别,在于叶节点是否存放一整行记录。聚簇索引叶子节点存储了一整行记录,而非聚簇索引叶子节点存储的是主键信息,因此,一般非聚簇索引还需要回表查询。
一个表中只能拥有一个聚集索引(因为一般聚簇索引就是主键索引),而非聚集索引一个表则可以存在多个。 一般来说,相对于非聚簇索引,聚簇索引查询效率更高,因为不用回表。
而在MyISM
存储引擎中,它的主键索引,普通索引都是非聚簇索引,因为数据和索引是分开的,叶子节点都使用一个地址指向真正的表数据。
10. 回表一定发生吗?
不一定的。
当查询的数据在索引树中,找不到的时候,才需要回到主键索引树中去获取,这个过程叫做回表。
假设普通索引树有需要的数据,则不用回表。
比如表结构
CREATE TABLE `employee` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`date` datetime DEFAULT NULL,
`sex` int(1) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_age` (`age`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
以下的SQL 不用回表:
select id,age from employee where age ='28'
其实,因为id
和age
的值,都在idx_age
索引树的叶子节点上,这就涉及到覆盖索引的只是点了。
覆盖索引是
select
的数据列只用从索引中就能够取得,不必回表,换句话说,查询列要被所建的索引覆盖。
11. CMS 和g1的区别
CMS收集器是老年代的收集器,一般配合新生代的Serial和ParNew收集器一起使用;G1收集器收集范围是老年代和新生代,不需要结合其他收集器使用; CMS收集器是一种以获取最短回收停顿时间为目标的收集器, G1收集器可预测垃圾回收的停顿时间。 CMS收集器是使用“标记-清除”算法进行的垃圾回收,容易产生内存碎片;而G1收集器使用的是“标记-整理”算法,进行了空间整合,降低了内存空间碎片。 CMS和G1的回收过程不一样,垃圾回收的过程不一样。CMS是初始标记、并发标记、重新标记、并发清理;G1是初始标记、并发标记、最终标记、筛选回收。
12.垃圾回收的三色标记法介绍一下。标记完黑色再解释一下
JVM 垃圾回收的三色标记法
JVM 中的垃圾回收采用 三色标记法(Three-Color Marking)来进行对象的标记与回收。它将对象分为三种颜色:
白色:表示尚未被扫描或访问的对象,最终可能会被回收。 灰色:表示已经被扫描,但它的引用对象还需要进一步扫描的对象。 黑色:表示已经完全扫描过且没有引用未扫描对象的对象。标记为黑色的对象和它们引用的对象是存活的。
标记过程:
根节点开始:从 GC Roots(如栈、静态变量等)开始,标记所有能访问到的对象为 灰色。 扫描引用:扫描灰色对象引用的对象,标记它们为 黑色,并继续扫描这些新标记的对象。 最终回收:经过这两步后,所有未被访问的对象将保持为 白色,它们最终会被回收。
黑色标记
黑色对象是已经完全标记过且没有引用未扫描对象的对象。它们被认为是存活的,并且不再需要进一步扫描。
13.秒杀活动,如何保证不超卖
保证不超卖,那就是控制好并发、事务一致性嘛。
并发的话,一般就是加redis分布式锁和数据库乐观锁。
有关于redis分布式锁,大家可以看我的文章哈:七种方案!探讨Redis分布式锁的正确使用姿势
有关于redis八股文回答技巧,大家有兴趣可以看我这篇文章哈(这个是付费的哈,29.9买断整个专栏):通用八股文面试技巧:聊聊Redis分布式锁(https://xiaobot.net/post/57219052-00d9-45d4-b19e-ae79f0648440)

有关于事务的话,我们多个数据库操作,肯定要用事务保证数据的一致性。有关于事务原理的话,或者被问到MVCC原理,则可以看我这篇文章:通用八股文技巧:MVCC原理拆解
14. 订单详情表,字段很多,业务方总是提需求,提需求就要添加字段,如何设计更合理
字段比较多的话,可以考虑这些方案:使用 JSON 字段、拆分表结构、与业务方沟通、使用 EAV 模型
使用 JSON 字段
优点:灵活、无需修改表结构。 缺点:查询性能较差,数据一致性较难管理。
拆分表结构
优点:清晰、易于维护。 缺点:需要多表连接,性能可能下降。
与业务方沟通
优点:避免频繁变化,集中处理需求。
使用 EAV 模型(Entity-Attribute-Value)
主表存储基本信息(如订单 ID、用户 ID)。额外表存储属性(Attribute)和对应值(Value)。
优点:灵活性高,可以动态添加新属性。 缺点:查询复杂,性能较差,数据一致性管理困难。
15.为什么想要离职,原因是什么
一般来说,就是钱给得不够嘛,或者干得不开心,还有就是被裁员了。
大家这个可以根据自身情况来更好回答哈。
最后
这篇文章会收录到我的八股文通用技巧专栏,创作不易,大家有兴趣可以来支持一波哈,29.9永久买断。

