




本文对亚马逊发表的2024 SIGMOD论文《Amazon MemoryDB,A Fast and Durable Memory-First Cloud Database》进行解读,文共5692字,预计阅读需要20至30分钟。
Amazon MemoryDB for Redis是一款专为实现持久性和内存级性能设计的数据库服务。在本文中,将描述MemoryDB的架构,以及如何利用流行的数据结构存储开源软件Redis构建企业级云数据库。MemoryDB将持久性需求卸载到独立的低延迟持久化事务日志服务,使我们能够从内存执行引擎中独立扩展性能、可用性和持久性。本文将阐述如何通过这一架构,在保持与Redis完全兼容的同时,提供单数字毫秒级写入延迟、微秒级读取延迟、强一致性和高可用性。
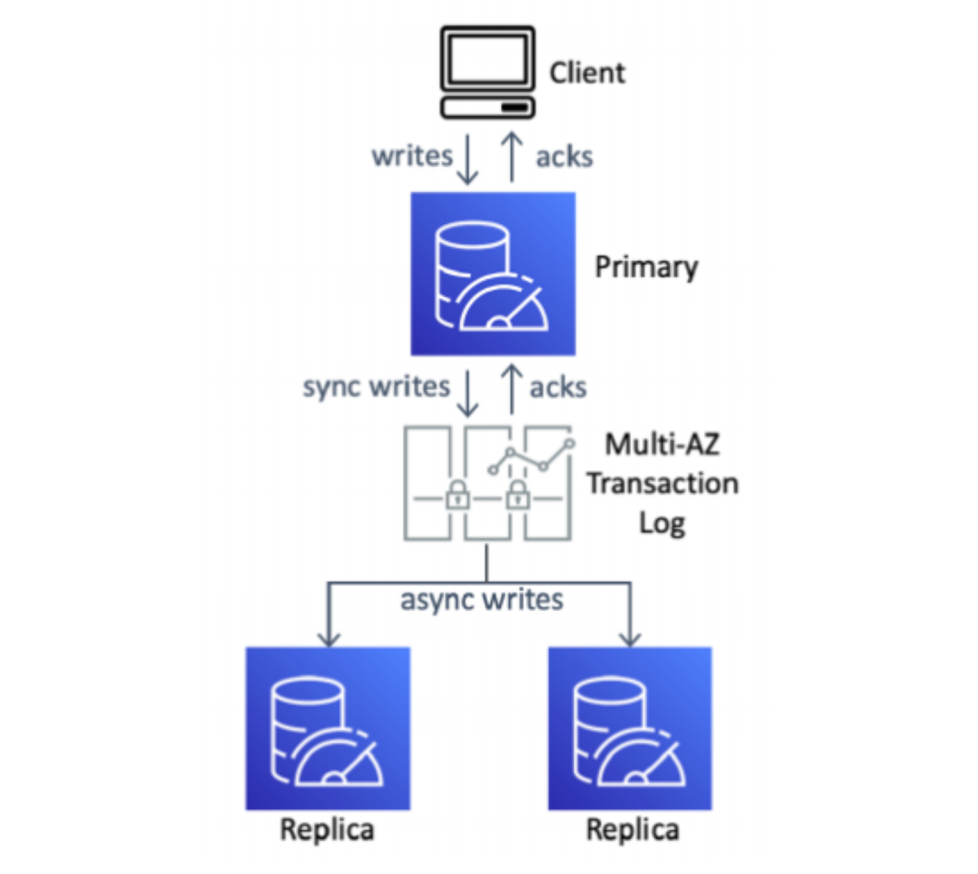
MemoryDB架构概览
主节点同步执行并复制更新到多可用区(MultiAZ)事务日志中,从节点则异步地从事务日志中获取更新
1.1研究背景
实时数据处理场景中,低延迟与高持久性至关重要。开源Redis虽具内存性能优势,但异步复制导致数据易丢失,企业需依赖复杂管道实现持久化,成本高且架构复杂。MemoryDB旨在通过解耦架构,在保持Redis兼容性的同时,提供企业级持久性与性能。
1.2Redis的局限性与企业级挑战
1.2.1 持久性缺陷
原生Redis依赖异步复制(asynchronous replication)和本地AOF日志,主节点故障时未同步到副本的写入会永久丢失,无法满足金融交易等场景的"零数据丢失"需求。即使启用AOF同步模式,单节点持久性仍受限于磁盘IO,且多节点故障时无法保证副本数据一致性。
1.2.2架构复杂度
企业用户为弥补Redis持久性不足构建了复杂数据管道:先将数据持久化到DynamoDB等存储,再通过流(如DynamoDB Stream)同步到Redis。当Redis数据丢失时,需要通过额外作业重建缓存实现持久化存储,但这增加了运维成本和延迟。
1.2.3一致性与扩展性问题
副本滞后(replica lag)不可控,读副本可能返回过时数据,需客户端显式处理stale数据问题。不支持跨分片任务,使得复杂业务逻辑被迫拆分,增加应用层复杂度。
1.3MemoryDB的设计任务
1.3.1简化架构
为了让用户能够更加便捷地使用Redis作为其主数据库,MemoryDB提供了一种无需额外组件的解决方案。通过MemoryDB,用户可以直接实现“内存计算+持久化存储”的一体化功能。
1.3.2性能与可靠性
在保持Redis微秒级响应优势的同时,通过事务日志服务实现强一致性和多AZ冗余,可以有效解决传统内存数据库"易失性"痛点。
2.1Redis核心技术架构
2.1.1数据模型与操作
Redis支持字符串、哈希、列表、集合、有序集合等 10多种数据结构,每个数据结构提供丰富操作(如ZSET的排序、HSET的字段操作),支持原子性批量命令(MULTI/EXEC)和图灵完备的Lua脚本,减少网络往返。
单线程模型(single-threaded)确保命令执行的原子性,但也导致 CPU密集型操作(如大键删除)可能阻塞主线程。
2.1.2分片与复制
分片机制:通过CRC16算法将键空间划分为16384个槽(slot),分布在多个分片(shard),每个分片包含1个主节点和N个副本,支持水平扩展。
异步复制:主节点执行写命令后,通过复制流异步发送到副本,副本可能因负载过高导致滞后,甚至在故障时丢失未同步数据。
2.1.3持久化方案
RDB快照:通过子进程生成全量数据快照,依赖操作系统的写时复制(COW),但在高写负载下可能导致内存激增(如翻倍)和CPU开销。
AOF日志:追加写命令到磁盘,支持每秒同步(默认)或每次同步(安全模式),但日志重写过程可能影响性能,且故障恢复需重放日志,耗时随数据量增长。
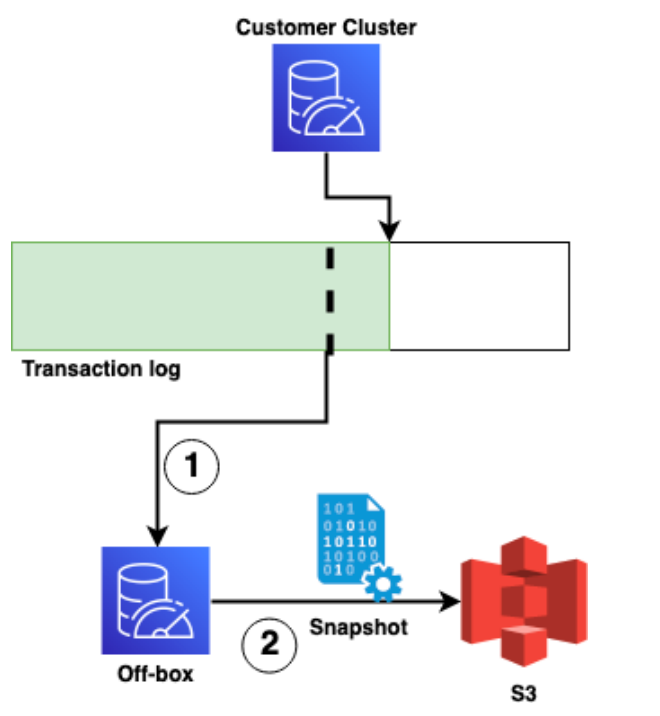
MemoryDB中的离线快照创建过程
离线集群会定期按计划创建,且使用最新生成的快照进行初始化。在此之后,(1)离线集群会读取事务日志,直至最新已知的更新(该更新记录于离线集群创建之时)。最后,离线集群进行快照操作(2),并将其上传至S3,这样一来,该快照就成为了此集群最新生成的快照。
2.2企业应用核心诉求
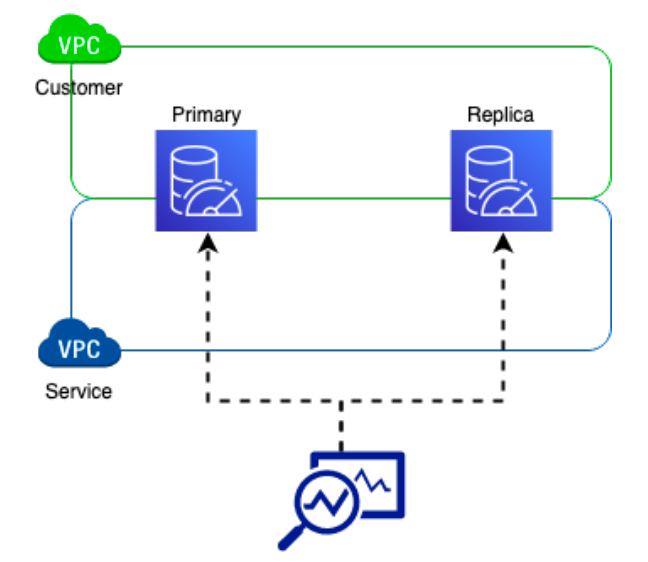
MemoryDB监控。MemoryDB客户集群通过客户提供的虚拟私有云(VPC)进行访问。MemoryDB服务使用另一个VPC与客户集群进行交互。一个多租户集群负责监控和管理MemoryDB集群。
2.2.1零数据丢失
在金融交易和实时竞价等关键应用场景中,数据的写入操作必须具备高度的可靠性和持久性。这意味着一旦数据被确认写入系统,就必须永久保存,不能有任何丢失或错误的可能性。然而,传统的Redis数据库采用的是异步复制机制,这种机制并不能完全保证数据的持久性和一致性。
2.2.2强一致性读取
在库存管理、用户画像等场景都需要读取最新数据,最终一致性意味着在分布式系统中,各个副本的数据在经过一段时间的同步后,最终会达到一致的状态,但这个过程中可能会存在短暂的数据不一致现象。
2.2.3简化运维
通过采用自动化工具来管理快照、故障恢复脚本以及跨多个系统的同步管道,可以显著降低人力资源的投入和减少因手动操作导致的错误概率。这样不仅提高了整体的工作效率,还确保了数据备份和恢复过程的准确性和可靠性。
2.3计算引擎与持久
2.3.1分层架构核心
(1)内存执行层(In-Memory Engine):
直接使用Redis内核(版本7.0.7)处理客户端请求,包括命令解析、数据结构操作、Lua脚本执行等,保留Redis原生性能(微秒级延迟)。
拦截Redis复制流(replication stream),将写命令转换为事务日志条目(log record),而非直接发送到副本,实现持久性层的解耦。
(2)持久性层(Durability Layer):
Multi-AZ事务日志服务:
分布式日志系统,支持跨3个可用区同步写入,确保日志条目至少持久化到多数AZ后才向客户端返回ACK,实现"11个9"(99.999999999%) 持久性。
提供有序Append API,每个日志条目包含唯一ID和前序ID,确保写入顺序性和原子性,支持高效的日志回放和故障恢复。
快照服务:
离线快照集群(off-box cluster)定期从S3加载最新快照并回放日志,生成新快照存储到S3,避免占用客户集群资源,解决Redis快照导致的内存激增问题
复制层操作主要将工作分为主节点和副本节点运行:
主节点:执行写命令→生成复制流→同步提交到事务日志→日志确认后返回客户端成功,确保写操作的强一致性。
副本节点:异步从事务日志拉取日志条目,按顺序回放(replay)到本地Redis实例,最终与主节点数据一致,支持读扩展(需客户端显式启用READONLY)。
2.3.2关键技术实现
技术突破主要聚焦于写入路径优化以及读取路径的设计上:
写路径优化:
写后日志:在命令执行后生成复制流,避免阻塞主线程,同时支持非确定性命令(如SPOP)的正确复制(记录操作结果而非命令本身)。
客户端阻塞机制:写命令提交到日志前,客户端响应暂存,待日志确认后返回,确保未持久化的写操作不被客户端感知,避免数据不一致。
读路径设计:
主节点读:线性一致,直接返回最新数据,适用于订单查询、库存校验等场景。
副本读:顺序一致,基于日志回放的时间点一致性,延迟由副本消费日志速度决定,适用于非实时分析、报表生成等场景。
3.1持久性
3.1.1日志架构特性
多AZ冗余:每个日志条目同步写入3个AZ的持久化存储(如SSD集群),通过多数派确认(majority commit)保证故障时数据不丢失,持久性达“11个9”(99.999999999)。
低延迟提交:日志服务与主节点部署在同区域,网络延迟控制在1-2ms,写入总延迟(命令执行+日志提交)为5-6ms(p99),接近Redis异步模式的3ms。
3.1.2与Redis耦合实现
利用Redis复制流的开放性,在主节点内存引擎执行写命令后,拦截其生成的复制协议(如RESP格式),转换为日志服务支持的二进制格式,无需修改Redis内核,保持版本兼容性(如支持Redis 7.x 新特性)。
3.2一致性
3.2.1强一致写入
主节点必须等待事务日志确认写入成功(即至少3个AZ持久化)后,才向客户端返回ACK,确保即使主节点立即故障,写入也已持久化,避免Redis异步复制的"未确认丢失"问题。
3.2.2键级阻塞机制
当读请求涉及未持久化的键(即对应写命令尚未提交到日志),MemoryDB会阻塞读响应,直到该键的所有关联写操作完成持久化,避免脏读。例如,用户写入键K后,在日志确认前读取K,需等待日志提交后才返回最新值。
3.2.3副本一致性
副本通过顺序消费事务日志实现与主节点的最终一致,且仅在日志条目提交后才应用到本地,确保副本数据不会落后于已确认的写操作。客户端通过READONLY命令选择副本读时,获得基于日志时间点的一致视图。
Redis集群架构属于具有基于多数的Quorum的leader-follower类别。它利用一种称为cluster bus 的gossip协议。每个分片中的主节点通过集群总线不断相互检测。
4.1领导者选举机制
4.1.1强一致写入
构建在事务日志之上事务日志服务提供了一个条件附加API。每个日志条目都分配有一个唯一标识符,并且要求每个append请求必须指定它打算遵循的条目的标识符作为前提条件。
租约(Lease)机制:主节点定期向事务日志写入租约续约条目(每1秒),副本通过检测租约过期(如3秒未更新)触发选举。
4.1.2一致性故障转移
利用附加API确保一致的故障转移变得更加简单。只有观察到最新写入的唯一标识符的副本才能成功将条目附加到日志中。当副本完全赶上事务日志时,将通过控制消息通知它。当多个副本争夺领导地位时,只有一个副本会成功,并且它将使任何其他并发请求的前提条件失效。
4.1.3领导者唯一性
以便在MemoryDB中提供内存中性能,同时保持一致性。许多基于共识的系统通过使用某种形式的租约来提高性能,其中节点可以在本地满足读取请求,而无需使用相对更昂贵的共识协议提交作。这种优化提高了读取吞吐量和延迟,但也通过减少必须通过共识处理的作总数来提高写入性能。
4.2恢复流程
4.2.1数据恢复
数据恢复的效率对于冷重启的平均恢复时间 (MTTR) 至关重要。其成为还原副本的主要本地过程,它们不会以任何方式与可用的对等节点交互。
4.2.2开箱快照
Redis通过分叉数据库进程来创建内存数据的快照。利用底层作系统提供的写入时复制虚拟内存管理技术,子进程捕获数据集的时间点并将其序列化为快照文件,而原始主进程继续接受更改。此作会放大数据库的整体内存使用率,并且会占用大量CPU。一些Redis用户习惯于保留额外的内存空间来抵消这种影响。
4.2.3创建快照计划
快照创建调度快照通常是比事务日志更有效的存储和恢复数据的格式。快照以紧凑的形式捕获每条数据及其最新内容一次,而事务日志包含对一条数据的所有历史更改,其中许多更改可能已与其最新内容无关。因此,为了优化数据恢复效率和冷重启时间,MemoryDB旨在使数据恢复始终以快照为主。
5.1控制平面
5.1.1自动化部署
用户通过API指定实例类型(如r7g.16xlarge)、分片数、副本数,控制平面自动创建EC2实例、配置VPC网络、挂载KMS加密密钥(支持客户自定义密钥),并初始化事务日志分片。
5.1.2滚动升级(N+1策略)
升级时先创建新实例,同步数据后替换旧实例,确保升级期间集群正常服务。例如,主节点升级前,先将领导权转移到新副本,避免服务中断。
5.1.3监控与自愈
秒级采集节点指标(CPU、内存、日志消费延迟),结合客户端请求成功率、延迟异常检测故障。
检测到节点故障后,自动重启数据库进程或替换硬件,新节点作为副本加入集群,通过快照+日志快速恢复数据。
5.2弹性扩展
5.2.1分片扩展
数据迁移:源主节点将目标槽的键序列化后发送到目标主节点,同时继续处理该槽的写操作,将后续变更通过日志同步到目标节点。
所有权转移:通过两阶段提交(2PC)更新事务日志中的槽所有权记录,确保新旧主节点在切换时无写丢失,迁移期间槽写不可用时间仅约 1-2ms。
5.2.2副本扩展
新增副本时,从S3加载最新快照并回放日志,无需依赖主节点传输全量数据,支持快速扩容(分钟级完成)。减少副本时,直接终止实例,释放资源
5.2.3实例类型调整
升级实例(如从r7g.large到r7g.2xlarge)时,先创建高配置副本,同步数据后替换旧节点;降级时若检测到内存不足(如目标实例内存小于当前数据量),自动回滚并报警,避免服务中断。
6.1性能评估
6.1.1基准测试
使用AWS Graviton3 实例(r7g系列),从r7g.large到r7g.16xlarge,均运行Redis 7.0.7 引擎。只读(GET)、只写(SET)、混合(80% GET + 20% SET),数据预填充100万键,值大小100字节,10个EC2客户端节点同AZ部署以减少网络延迟。
6.1.2读写吞吐量对比
读性能:MemoryDB通过Enhanced IO 技术(多路复用客户端连接)在大实例类型上超越Redis,最大吞吐量提升50%。
写性能:MemoryDB因同步日志提交引入额外延迟,吞吐量比Redis低约40%,但单分片可达到 100MB/s写带宽,满足多数实时场景需求。
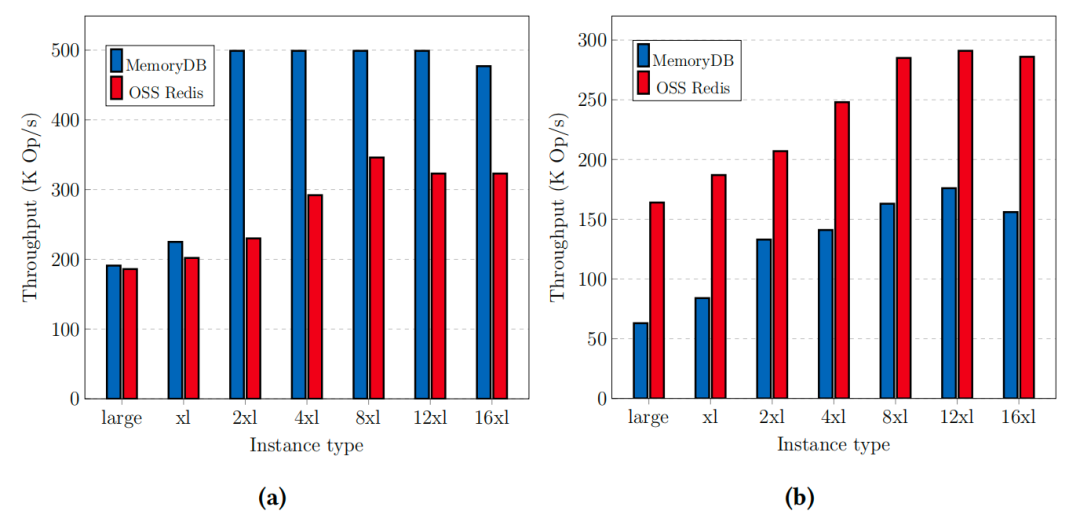
MemoryDB和Redis在只读(a)和只写(b)工作负载下的吞吐量
6.1.3延迟对比
读延迟:两者均为亚毫秒级(p50<1ms),p99延迟MemoryDB 为 2ms,Redis 为1.8ms,差异可忽略。
写延迟:MemoryDB p99 为6ms(含日志同步),Redis为 3ms(异步AOF),但MemoryDB确保每次写均持久化到 3个AZ,牺牲部分延迟换取强持久性。
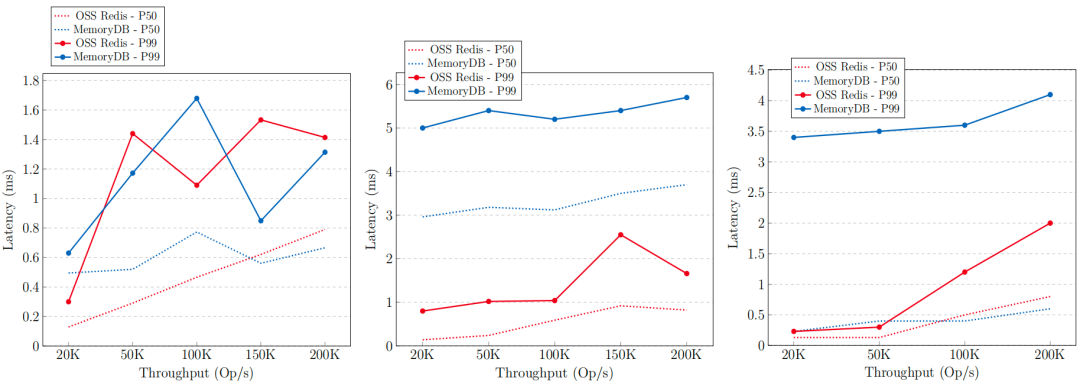
在16xlarge实例类型上,针对只读(a)、只写(b)和混合读写(c)工作负载,MemoryDB与Redis在不同提供吞吐量下的延迟表现
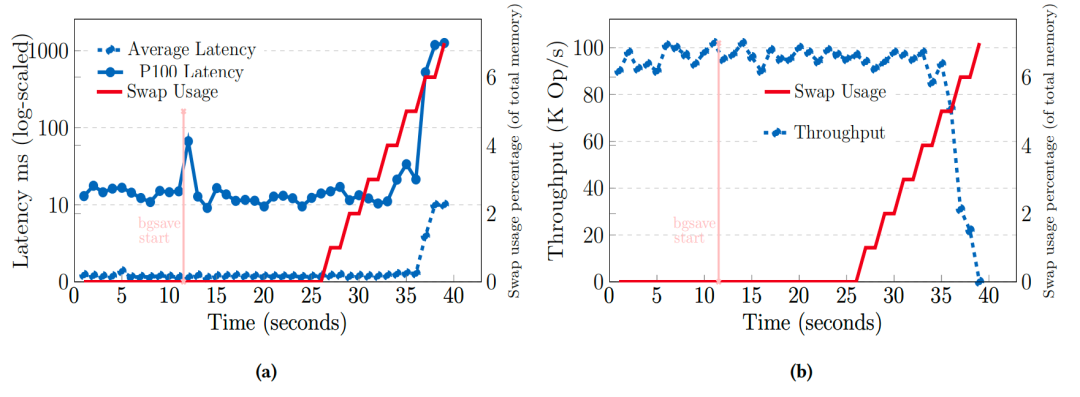
在Redis内存受限设置下执行BGsave(后台保存)期间客户端感知到的延迟(a)和吞吐量(b)
6.1.4快照性能优化
Redis BGSave:
高写负载下触发COW,内存占用可能翻倍,导致swap使用激增,P100延迟飙升至67ms,吞吐量骤降为0。
MemoryDB离线快照:
独立集群执行快照,客户集群内存占用无变化,平均延迟稳定在1ms,P100延迟10-20ms,且无需预留额外内存空间。
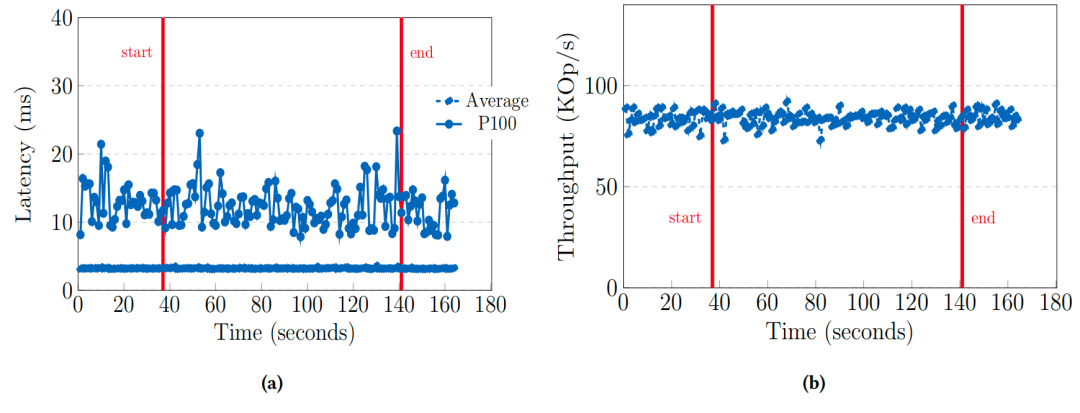
使用离线技术进行BGsave(后台保存)期间客户端感知到的延迟(a)和吞吐量(b)
6.2大规模维持一致性验证
6.2.1升级期间一致性
MemoryDB当前使用开源Redis维护版本。由于其存储和持久性解耦特点,Redis被用作内存中执行引擎。为保持升级后的一致性,MemoryDB不从根本上改变复制策略。这样可以允许MemoryDB的客户选择升级引擎版本以获得其他功能,例如新的数据结构或命令。
6.2.2验证正确性
MemoryDB主要通过以下两种方法进行安全性验证:
快照正确性验证:MemoryDB 会验证生产中每个新创建的快照,以确保其一致性不变。MemoryDB 维护整个事务日志的运行校验和,并定期将当前校验和值注入事务日志本身。
一致性:在保持强一致性同时,通过分解系统正确性验证,验证 Redis API的功能正确性。MemoryDB允许应用一套不同的形式化方法工具来最好地检查每个属性。
7.1结论
MemoryDB证明了通过解耦架构可突破传统内存数据库的局限性,在保持高性能和生态兼容性的同时,实现企业级持久性和一致性。其核心创新在于分布式事务日志服务、租约式选举、离线快照。为同类系统设计提供了可复用的解决方案。
7.2相关工作
7.2.1解耦数据库
已经为分解存储构建了许多分布式数据库系统。Amazon Aurora将重做处理卸载到多租户横向扩展存储服务。Sinfonia是通过横向扩展服务抽象事务访问方法的系统,允许使用这些抽象实现数据库系统。MemoryDB利用数据库节点进行存储和命令处理,同时将复制和持久性卸载到横向扩展事务日志服务。
7.2.2日志复制
将日志复制和分布式存储系统作为提供持久性的一种方式。MemoryDB通过构建一种类似于一致的复制日志协议使其具有类似的安全属性。MemoryDB通过利用横向扩展事务日志服务来建立共识和持久性,从而提高系统的活动性。
7.2.3内存数据库
近年来,大规模Web应用程序系统发现动态随机存取内存对于实现其性能目标是必不可少的。但是,由于Redis的持久性保证较弱,用户很难依赖Redis作为主数据库。MemoryDB是基于内存的云原生数据库,可提供强大的一致性、11个9的持久性和4个9的可用性。
论文解读联系人:
刘思源
13691032906(微信同号)
liusiyuan@caict.ac.cn





