





在数据仓库领域,Apache Doris 凭借其卓越性能与便捷性被广泛应用。其中,FE(Frontend)作为核心组件,承担着接收查询请求、管理元数据等关键任务。然而,在实际使用中,FE 难免会遭遇各类问题,影响系统的正常运行与性能表现。本文将深入剖析 Doris FE 常见问题及其处理办法。

一、定位 FE 问题的关键信息
当 FE 出现问题时,精准定位是解决问题的首要步骤。首先,需关注出问题前后 1 天左右的日志,若为多节点部署,每个节点的相关日志都至关重要。这些日志包括:
fe/log
目录下的fe.log
(记录 FE 运行的关键事件与错误信息)、fe.audit.log
(审计日志,可用于追踪操作记录)、fe.gc.log
(垃圾回收日志,对分析内存问题有重要参考价值)以及fe.out
(包含fe启动和宕机的相关信息)。fedoris - metabdbje.info.0
(bdbje 日志,其打印时间为 UTC 时间,需注意加上 8 小时转换为北京时间)。精确到 commit 号的版本信息,可通过执行
start_fe.sh --version
在控制台输出或fe.out
中获取。show frontends
的全部输出,能展示 FE 节点的详细状态信息。若有 prometheus 监控,还需提供如 jvm heap 堆内存使用情况、线程数量、导入 job 数量、checkpoint 失败次数等监控数据。
当 FE 卡住时,需通过
jstack -l $(pid)> jstack txt
搜集 jstack 信息;若内存使用高达数十 GB,则需jmap
信息。机器的 cpu、内存、磁盘 io、网络的 promethues 监控情况,排查是否存在 cpu 打满、物理内存耗尽、磁盘 io 秒级延迟、网络丢包等问题。
dmesg -T > dmesg txt
信息,常用于定位FE OOM的问题。
二、FE 常见问题解析与应对
(一)FE 挂掉
master 节点写达不成多数派挂
Insufficient acks for policy:SIMPLE_MAJORITY. Need replica acks: 1. Missing replica acks: 1
原因:
内存使用过高,可能是 cms 垃圾回收器遭遇 “promotion failed” 或者 “concurrent mode failure”,此时需排查内存使用情况,可通过
jmap
dump 内存镜像并用jprofiler
进行分析(搞不了的话,可以联系社区同学协助分析)。多节点环境下,若其他节点状态逻辑错误已死掉,仅剩一个 master 节点,需同时查看其他 fe 节点日志,确认其存活状态与是否有异常退出栈。
某些节点机器的物理资源(cpu、内存、io)存在瓶颈,需查看机器相应监控。
master 因 gc 或者 io 写 io 消耗时间太长,如在
je.info.0
中出现类似日志
2025 - 03 - 04 01:27:00.165 UTC WARNING [fe_026093bb_658d_41dc_8f8b_96bd5a968c24] FSync time of 106698 ms exceeds limit (5000 ms)” 的日志。
fe 堆内存 OOM
现象与处理:fe.out
中会有相应打印,出现该情况需分析 fe jvm 堆内存占用情况。 需要在后续内存高的时候dump内存出来,具体分析一下

★几种常见的oom场景见下文 “fe内存问题”
操作系统 oom 杀掉 java 进程
原因:机器上其他进程占据过多内存,致使 fe 无法获取 jvm - Xmx 配置的堆内存,操作系统启动 oom - killer 线程杀掉 fe。
排查方法:通过dmesg -T | grep -i java
查看日志信息,
(二)FE 内存问题
堆内存内存高,遇到 gc 降级,master pause 太长时间,导致 fe 挂
场景:尤其在高频导入情况下,事务和 LoadJbb 占内存多,其他 follower 重新选举后,原 master 退出,新接任的 master 节点重复出现该问题。
解决办法:
配置label 保留参数:
label_keep_max_second = 21600 6 hour
streaming_label_keep_max_second = 21600 // 6 hour
修改FE JVM 的 gc算法为g1,参考如下
JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false -Xmx8g -XX:+UnlockExperimentalVMOptions -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:$LOG_DIR/log/fe.gc.log.$DATE -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=50M -Dlog4j2.formatMsgNoLookups=true"
schema change job 数量多
影响:可能导致 fe com 或者出现上述堆内存高的情况(较新版本有优化)。
误开 profile 或者 profile 功能存在 bug(2.0.2版本之后已经优化了)
cms 垃圾回收器回收不及时
现象:待回收临时对象多,导致内存使用高,遇到 gc 降级 fe 挂,内存使用量监控呈锯齿状,类似下图(同堆内存高问题,新版本改为 g1 回收器)。
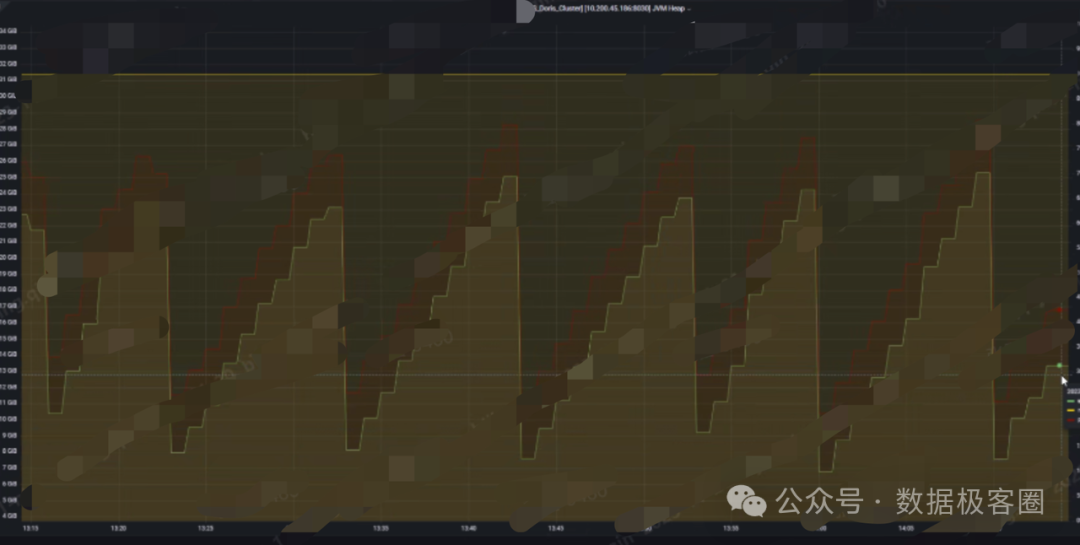
(三)FE 启动不起来
meta out of date 或者 wait catalog to be ready
原因:
磁盘空间不足,bdbje 禁止写入,出现 “com.sleepycat je.DiskLimitException” 错误。
meta out of date 偶尔打印一次属正常,可调参数。meta_delay_toleration_second 默认值 300(5 分钟),元数据延迟间隔时间。
★启动时打印少数几次 meta out of date,随后不再打印,也为正常现象。
时钟不同步:
如出现 “Clock delta: xxxx ms.between Feeder” 类似的日志
this Replica exceeds max permissible delta: 5000 ms. HANDSHAKE_ERROR: Error during the handshake between two nodes. Some validity or compatibility check failed, preventing further communication between the nodes
这是节点间时钟不同步,需要校正时钟。
doris fe 代码 bug(序列化 反序列化问题 NullPointerException)等。
已经修复了,修复pr(推荐升级):
https://github.com/apache/doris/pull/26563
https://github.com/apache/doris/pull/30337
https://github.com/apache/doris/pull/30441
doris fe 非主节点写 editlog 导致
类似下图这种,已经修复(推荐升级):https://github.com/apache/doris/pull/29395

运维操作不当
做了降级操作,高版本的 doris - meta 元数据用低版本的 jar 包启动。比如报错这种(仅供参考):
Unknown meta module: workloadSchedPolicy
升级操作 jar 替换不全或未清理旧版本 jar 包。比如报错(仅供参考):
“java.lang.NoSuchMethodError: 'com.google.gson.GsonBuilder com.google.gson.GsonBuilder.addReflectionAccessFilter”
长时间 checkpoint 失败导致重新启动慢
可通过ls doris-meta/image -l
查看最近 checkpoint 成功的时间,正常情况下 10 分钟会有一次成功的 checkpoint。
(四)doris - meta/bdb 目录大(几十 GB)
需先检查所有节点状态是否正常,master 近期是否做 checkpoint,内存使用超过 jvm heap 70% 不做 checkpoint(可通过grep -i "checkpoint' fe.log.xxx
排查),master 做完 checkpoint 是否 push image 到其他节点成功,是否因 image 过大导致 push image timeout。fe.log里面会有类似日志:
[Checkpoint.doCheckpoint():210] Failed when pushing image file.
(五)doris - meta/image/image.xxx 文件大(几十 GB)
导入 label 比较多,没有及时删除,可以参考前面的参数进行调整
ccr bin log 占的多:旧版本的ccr默认的 disable binlog 不会清空已经记录的 binlog , 主要还是 ttl_seconds 没有设置,disable 的时候仍然需要依靠 ttl_seconds 来回收。
解决方法: 旧版本把之前开过 binlog 的表都设置一下 "binlog.enable" = "true",再设置 "binlog.ttl_seconds" 为一个合理的值。或者直接升级到最新稳定版本
(六)FE 卡住死锁(jmap dump fe 内存镜像)
1. 高并发点查把 cpu 打满后,连带导致内存高占用:在监控中会呈现 CPU 和内存先后升高的趋势。
2. 内存本身高占用,故障时间点做 checkpoint 需要近 1 倍内存:在fe.log
搜索checkpoint
关键词,类似下面的日志:
the memory used percent 73 exceed the checkpoint memory threshold: 70, exceeded count: 1”“2024 - 09 - 06 23:16:14,959 INFO (leader Checkpointer (99) [Checkpoint do Checkpoint () :124] begin to generate new image: image.8745633
3. 大查询解析过程把 fe 打满:表现为 CPU 升高。
(七)FE show frontends慢
show frontends 返回耗时很长
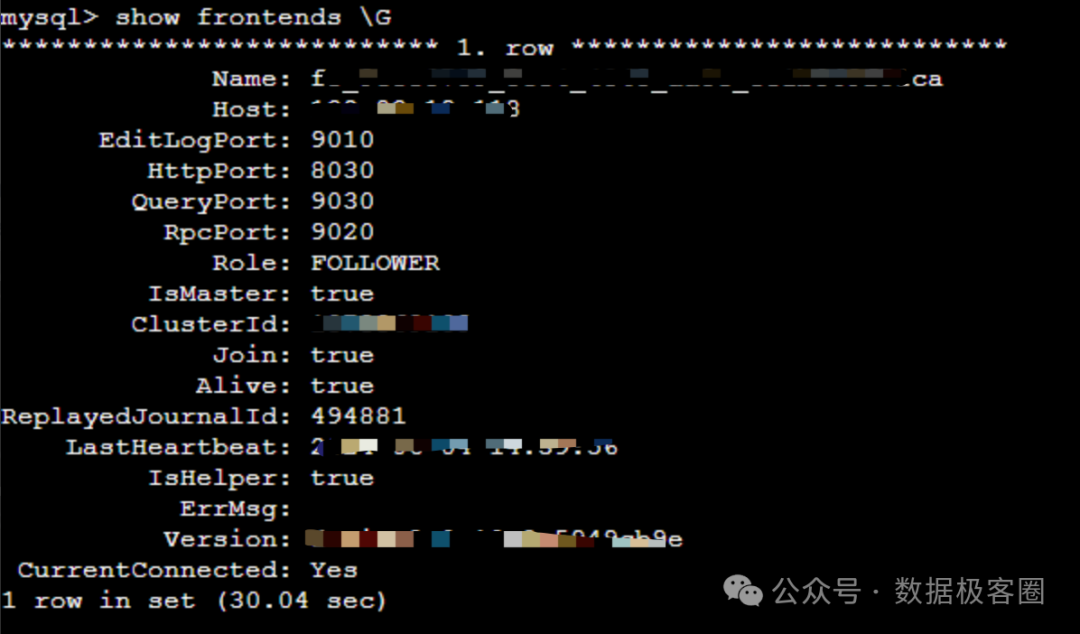
已知的域名解析问题,每个机器hosts文件都加上所有fe节点的域名和ip对应关系就可以了。 注意/etc/resolv.conf文件内容,里面是否有云平台厂商预置了个DNS设置。
在使用 Doris FE 过程中,遇到问题不要怕,关键是要掌握正确的定位与解决方法。通过对各类常见问题的深入分析,结合上述详细的处理指南,相信大家能够更高效地保障 Doris 系统的稳定运行,充分发挥其在数据处理与分析中的强大效能,如果还有其他相关问题欢迎补充讨论。
往期推荐
完
Apache Doris社区是目前国内最活跃的开源社区(之一)。Apache Doris(Apache 顶级项目) 聚集了世界全国各地的用户与开发人员,致力于打造一个内容完整、持续成长的互联网开发者学习生态圈!
如果您对Apache Doris感兴趣,可以通过以下入口访问官方网站、社区论坛、GitHub和dev邮件组:
PowerData是由一群数据从业人员,因为热爱凝聚在一起,以开源精神为基础,组成的数据开源社区。
社区群内会定期组织模拟面试、线上分享、行业研讨、线下Meetup、城市聚会、求职内推等活动,同时在社区群内你可以进行技术讨论、问题请教,结识更多志同道合的数据朋友。
社区整理了一份每日一题汇总及社区分享PPT,内容涵盖大数据组件、编程语言、数据结构与算法、企业真实面试题等各个领域,帮助您提升自我,成功上岸。
可以加作者微信(Faith_xzc)直接进PowrData官方社区群
叮咚✨ “数据极客圈” 向你敞开大门,走对圈子跟对人,行业大咖 “唠” 数据,实用锦囊天天有,就缺你咯!快快关注数据极客圈,共同成长!

点击上方公众号关注我们
