




点击上方 蓝字 关注数据微光👆 免费获取Doris+AI知识库
在当今数据湖与数据仓库融合的趋势下,Apache Doris 打造了一套成熟的湖仓一体解决方案。
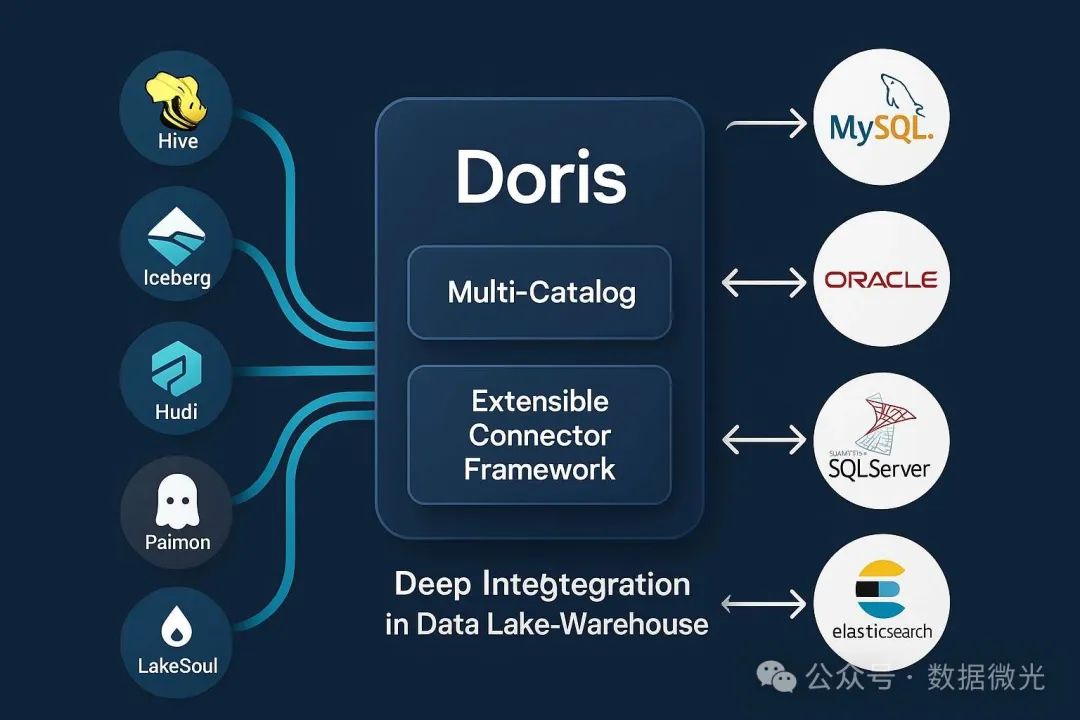
Doris 通过 Multi‑Catalog 与 可扩展的连接器框架,能够无缝对接 Hive、Iceberg、Hudi、Paimon、LakeSoul、Elasticsearch、MySQL、Oracle、SQLServer 等主流数据系统与格式。
在此基础上,Doris 提供基于 SQL 的统一分析网关与结果写回能力,让用户在不改变既有数据架构的情况下,轻松实现跨平台、零迁移的实时与离线数据查询与分析。
这一能力充分释放了湖仓一体的高性能与低成本优势。
1. 湖仓架构强化
从 2.1版本 开始,全面提升湖仓架构的整体能力,不仅增强了 Hudi、Iceberg、Paimon 等主流数据湖格式的读写性能,还引入了多种 SQL 方言兼容与 Arrow Flight 高速读取接口,实现了约 100 倍的数据传输提速。
同时,Doris 支持与现有系统的无缝联通,真正做到零改造下的全网联邦查询体验。
2. 核心技术架构
2.1 Multi‑Catalog:跨数据源统一接入
Multi‑Catalog 为 Doris 增加了一层“Catalog”,可通过 CREATE CATALOG
一次性映射整个外部数据目录,后续无须逐表创建外部表,大幅降低管理复杂度。
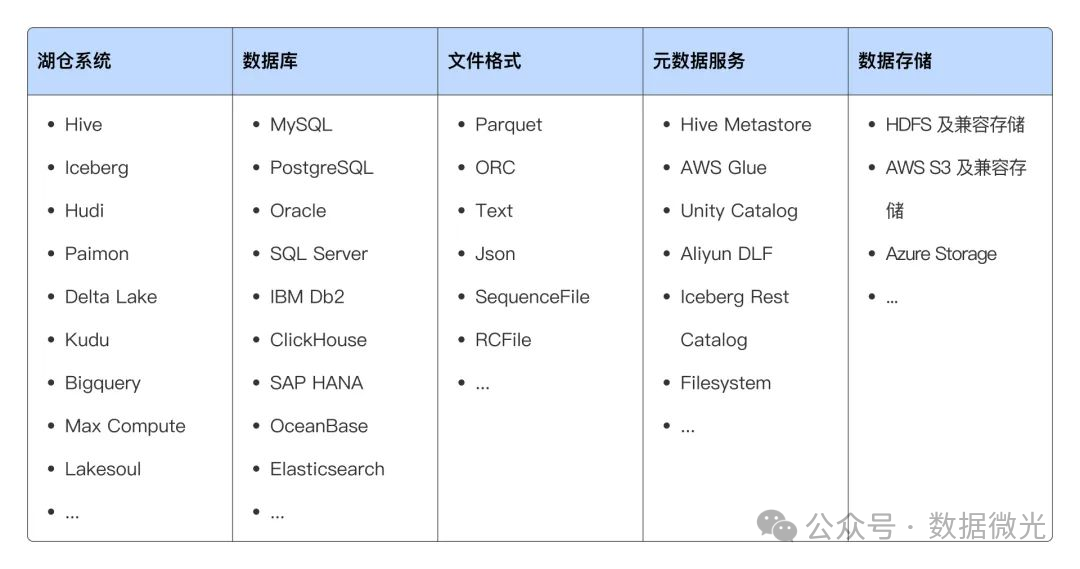
支持目录类型包括 HMS(Hive Metastore)、Iceberg、Hudi、Paimon、LakeSoul,以及基于 JDBC 的 MySQL、Oracle、SQLServer、Elasticsearch 等。
2.2 可扩展连接器框架
Doris 的连接框架分为元数据连接与数据读取两部分:
元数据连接:前端通过 MetaData Manager 获取并缓存外部目录的库、表、分区等信息,支持 JDBC 认证、Kerberos/Ranger 权限及 KMS 加密。 NativeReader:后端基于自研读写器,向 HDFS/S3 等对象存储高效拉取 Parquet、ORC、Text 等格式文件,避免格式转换开销,并支持向 Java 大数据生态的 JNI 连接。
2.3 原生数据读取与缓存优化
元数据缓存:自动、定时与订阅式三种同步策略,支持高并发元数据事件处理,秒级生成查询计划。 数据缓存:针对文件外表(如 Hive、Hudi)提供本地磁盘缓存,并利用一致性哈希分布到所有 BE 节点,显著减少网络 I/O 延迟。 查询结果与分区缓存:复用历史查询结果与热点分区数据,加速相似或自定义范围查询。
3. 统一 SQL 分析与结果写回
Doris 提供统一的 SQL 分析网关,无论是内表还是外部表,均可通过标准 SQL 语句统一访问与分析,用户无需学习额外 DSL 或复杂 API。
零迁移查询:切换至目标 Catalog 后, SHOW DATABASES
、USE db
、SELECT …
等命令与内表操作完全一致,实现跨系统透明查询。结果写回:支持将查询结果以 CSV、Parquet、ORC 等格式导出至数据湖,完成后续处理或下游系统消费,构建端到端一体化湖仓流程。
4. 最佳实践与案例
Hudi 实时湖仓:Doris 支持 Hudi 的 Copy on Write、Merge on Read、Time Travel 与 Incremental Read 功能,结合 Doris 的高性能查询与 Hudi 的实时写入,实现金融交易、广告点击流、电商用户行为等场景的低延迟分析与审计回溯。 跨源联邦查询:利用 Multi‑Catalog,可在单条 SQL 中联合查询 MySQL、Hive、Iceberg 等表,省去 ETL 和物化视图,缩短数据流转时长,提高开发效率。 大规模数据科学读取:Doris 集成 Arrow Flight 接口,在 PyArrow/Pandas 等生态中实现显著的数据读取加速,满足机器学习训练与 BI 报表的即时性需求。
5. 性能对比与提升
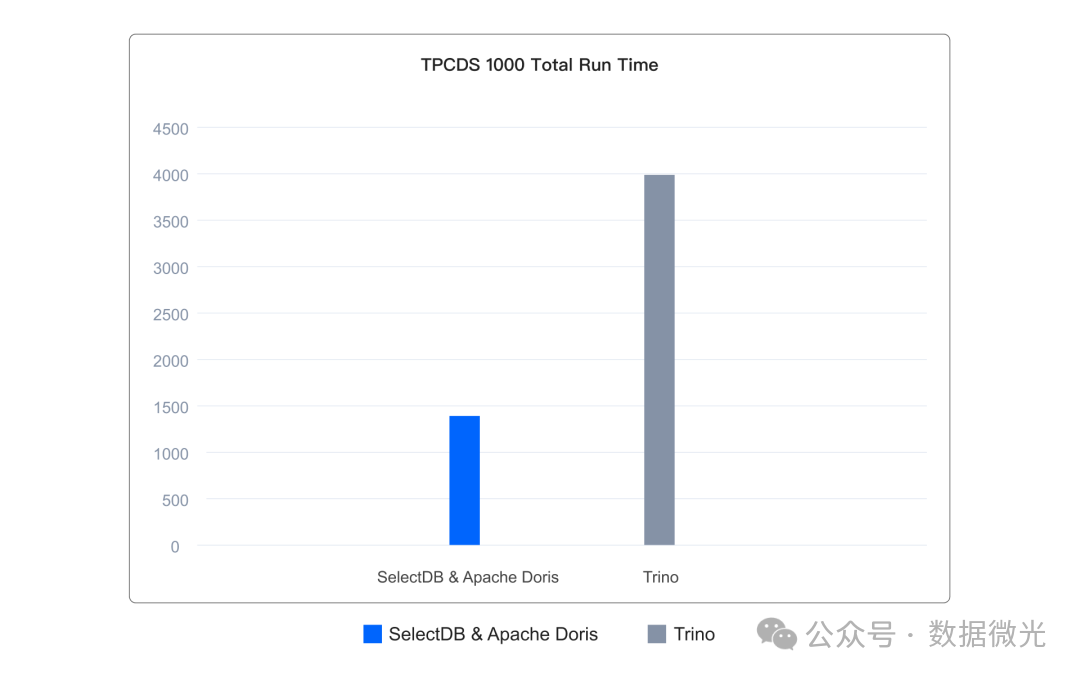
得益于上述多项极速查询技术,当使用 Doris & SelectDB 作为湖仓计算和查询引擎时,相较于 Presto、Trino、SparkSQL、Hive 等传统引擎,通常能带来数倍的性能提升。在基于 Iceberg 表格式的 1TB TPC‑DS 标准测试集上,Doris & SelectDB 执行全套 99 个查询的总体运行耗时仅为 Trino 的三分之一。
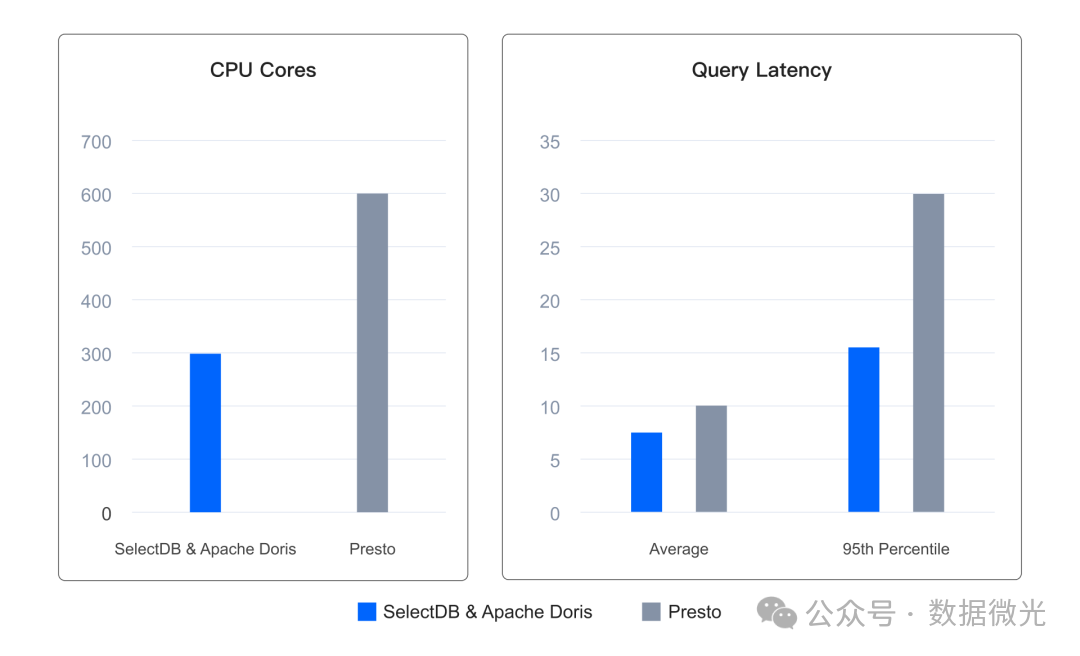
在实际用户场景中,使用同等或更少的资源配置(例如仅使用一半资源)时,与 Presto 比较,平均查询延迟可降低约 20%
,而 95 分位延迟更是降低 50%
,显著实现了降本增效的目标。
6. 小结
Apache Doris 的湖仓一体能力,凭借 Multi‑Catalog 与可扩展连接器框架,将异构数据系统和多种文件格式纳入统一 SQL 分析平台。
同时,配合 原生 Reader、智能缓存和 Arrow Flight 加速等技术,以及与 SelectDB 协同带来的卓越性能提升,帮助企业在不变架构下轻松构建高性能、低成本的湖仓解决方案。
立即动手体验,让 Doris 成为您数据湖与数据仓库融合之路上的利器!
往期推荐

数据微光 专注分享 Apache Doris 的最佳实践、问题解决技巧、学习资源和实用案例,致力于为开发者和技术爱好者提供高质量内容支持和持续学习动力。
📚 特别福利 | 数据微光知识库内含Apache Doris丰富的 学习资料、实战课程、白皮书、行业报告、技术指南,帮助快速掌握数据库核心技能!
📘 领取方式: 关注 “数据微光” 公众号 扫描下方二维码,备注【Doris】即可免费获取! 💻 让我们携手点亮技术微光,共同探索 Doris 的无限可能!


Apache Doris
Apache Doris 是一个基于 MPP 架构的高性能、实时的分析型数据库,以极易易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发发点查询场景,也能支持高吞吐的复杂分析场景。
如果您对 Apache Doris 感兴趣,可以通过以下入口访问官方网站、社区论坛、GitHub 和 dev 邮件组:
📒 官方文档: https://doris.apache.org 💬 社区论坛: https://ask.selectdb.com 📂 GitHub: https://github.com/apache/doris 📧 dev 邮件组: dev@doris.apache.org
可以加 作者微信 (hhj_0530) 直接进 Doris 官方社区群。
PowerData
PowerData 是由一群数据从业人员,因为热爱凝聚在一起,以开源精神为基础,组成的数据开源社区。
社区群内会定期组织模拟面试、线上分享、行业研讨、线下 Meetup、城市聚会、求职内推等活动。同时,在社区群内您可以进行技术讨论、问题请教,结识更多志同道合的数据朋友。
社区整理了一份每日一题汇总及社区分享 PPT,内容涵盖大数据组件、编程语言、数据结构与算法、企业真实面试题等各个领域,帮助您提升自我,成功上岸。
可以加 作者微信 (hhj_0530) 直接进 PowerData 官方社区群。


点击上方蓝字关注我们
