




本文对北京理工大学袁野教授团队、华为公司、中国移动信息技术中心陶涛、酷克数据简丽荣、清华大学李国良教授等联合编写的2024ICDE论文《Separation Is for Better Reunion: Data Lake Storage at Huawei》进行解读,全文共9508字,预计阅读需要15至25分钟。
华为和国内的大型企业往往将运营数据存储在数据湖中,以向客户提供各种业务,如存储、处理大量日志消息数据,实时和决策应用。为了满足这些需求,作者团队设计了一个数据湖存储系统StreamLake,该系统在分布式存储环境下提供日志消息流和批量数据处理的服务,通过引入流(存储)对象和分层存储,对表格数据实现Lakehouse功能和设计LakeBrain优化器,实现了高扩展性、高效率、高可靠性和低成本的存储分解架构。
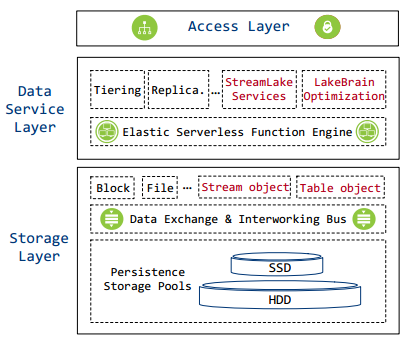
StreamLake存储系统概述
1.1大数据时代孕育而生的数据湖存储
随着物联网和5G技术的蓬勃发展,大数据的收集、存储和分析对传统的数据基础设施架构发出了极大的挑战。以华为Oceanfront Pacific和AWS S3为代表的数据湖存储为大量的结构化和非结构化数据提供了服务,极大提高了传统存储方式的可用性和可靠性,已被广泛用于存储海量数据和大规模数据分析。
然而,随着大型企业特进一步开展数字化业务,需要存储和分析的数据呈现爆炸式增长。对于不同行业企业的大数据处理需求,包括但不限于:
PB级数据:大部分的企业需要处理的数据在PB数量级,部分企业需要管理的数据甚至超过了100PB。
日志数据:大多数企业需要处理的数据主要是日志消息数据。
流处理和批处理:流处理和批处理是大型企业中最常见的处理数据的方式,将近一半的企业同时采取流处理和批处理。
数据保留:根据不同行业的法规和管理,企业需要将数据存储1-10年不等,一些企业至少需要将数据存储10年。
为了满足上述不同行业大型企业对于数据存储和处理的需求,研究者们旨在设计一个更高效率、持久性、可扩展性和低总拥有成本(TCO)的数据湖存储系统,并支持流处理和批处理的功能。
1.2现有数据湖的局限性
1.2.1高弹性和高处理效率难以共存
由于用户总是面对PB级的日志流数据,因此以低成本持久存储数据,同时保持高弹性和处理效率是一个挑战。例如,Kafka利用流数据进行实时处理,使用本地文件系统作为存储。但是由于计算和存储是紧密耦合的,因此数据湖缺乏弹性;同时在实际应用中,用户可能会对同一数据进行不同应用的流处理或批处理,为不同过程存储两个副本会导致较高的成本。
1.2.2数据不一致的风险
如上所说,在实际的数据分析场景中,对于数据的处理更加复杂,可能会有多个数据副本来支持不同的任务。如果这些副本单独更新,数据可能会不一致。因此,支持原子性写入以获得高质量数据具有重要的意义。
1.2.3难以在数据湖中实现优化方法
在数据湖存储系统中,由于计算引擎和存储之间的依赖较小,执行一些优化手段,比如数据库中的优化器,是具有挑战的。因此应考虑如何将优化器集成到存储引擎中以优化系统的整体性能。
1.3提出StreamLake的动机
为了解决现有数据湖的局限性,StreamLake存储系统应运而生,以服务于企业级流处理和批处理数据。StreamLake的核心思想是通过引入流对象来提供读写服务,并利用Lakehouse功能支持框架的ACID,同时构建智能数据湖优化器LakeBrain来提高资源利用率和查询性能。
具体来说,StreamLake具有以下特性:
高存储可扩展性:StreamLake利用流对象和表对象,采用计算和存储分离的架构,允许根据流和批数据的动态负载,弹性化地调整计算和存储资源。即使在储存PB级的数据时,也可以进行扩展。
高处理效率:StreamLake中的流对象提供了高效的读写API,支持实时流处理。流对象提供了负载均衡的流存储,也有助于提高效率。此外,查询计算下推的应用减少了存储和查询引擎之间的数据传输。同时LakeBrain优化器通过优化数据布局来提高查询性能。
高可靠性:StreamLake基于华为Oceanlaw Pacific 构建,保证内置数据的可靠性和安全性,为数据提供全面保护。
低总拥有成本TCO:StreamLake可以为用户节省大量成本。成本主要包括存储和计算服务器的成本。一方面,StreamLake存储的数据副本比其他系统(如HDFS)少,并采用内置的分层存储和压缩技术来节省存储成本,只存储一个副本来服务于流和批处理数据,这进一步节省了成本。另一方面,LakeBrain优化器和下推应用也通过提高查询效率来节省计算资源。此外,分散的架构使用户可以根据需要要求他们的计算或存储资源。
1.3.1 StreamLake的实际应用
文章在中国移动的数据湖中部署了StreamLake,并将其与生产数据结合,极大地优化了资源利用率和性能。中国移动作为管理者全国最大数据分析平台之一,每天都有PB级的数据从多个省份的业务分支机构流向多个集中的数据中心。新数据首先到达负责数据交换的收集和交换平台,之后将其加载到分析平台中。传统的Kafka和HDFS服务会随着平台发展到EB级导致资源利用率的不平衡,给执行任务带来昂贵的成本和易错性。通过部署StreamLake,可以提高服务器的资源利用率并且节省约37%成本。此外,更多的查询可以实现较高的性能改进。
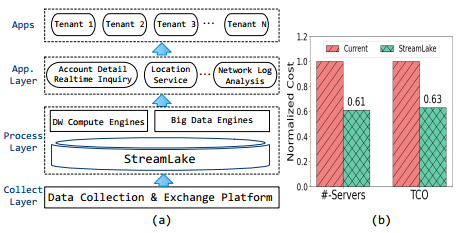
StreamLake的在中国移动中的实际应用场景
2.1框架概述
StreamLake是一个用于满足大型企业大数据存储和处理需求的存储系统,旨在优化大数据管道中海量日志消息的处理效率和资源利用率。StreamLake框架主要由三层组成:存储层,数据服务层和数据访问层。该架构还包括两层路由:一个在数据服务层,具有跨节点分配处理能力;另一个在存储层,用于平衡存储空间,促进快速数据复制和重建。这种对称架构确保系统能够提供高性能、容错和高可扩展性。
StreamLake存储系统框架总览
2.2存储
存储层负责数据持久化,由SSD和HDD数据存储池、高速数据交换和互通总线以及多种类型的存储语义抽象(包括块、文件、流、表等)组成。
2.2.1 SSD和HDD数据存储池
由SSD和HDD组成的数据存储池提供了对存储数据的可靠管理。存储集群中磁盘上的物理存储空间被划分为切片,然后将切片组织为跨各个服务器磁盘的逻辑单元,以确保数据冗余和负载均衡。
存储池还实现存储空间功能,例如垃圾收集、数据重建、快照、克隆、一次写入多次读取机制、精简配置等。
2.2.2高速数据交换和互通总线
数据交换和互通总线提供高速数据传输和不同存储抽象的互通。,包括支持远程直接内存访问(RDMA),绕过CPU和L1缓存以加快数据传输速度。此外,总线利用智能条带聚合,I/O优先级调度等来优化数据传输和处理。所有节点通过数据总线互连,实现高效低延迟的数据交换,支持不同存储抽象的互通,允许不同接口共享和访问同一数据块,无需数据迁移,大大节省存储空间。
2.2.3多种类型的语义抽象
块和文件等存储抽象以不同的语义实现了对底层存储的访问接口。同时,StreamLake引入了两种新的抽象:流对象和表对象,以有效地管理消息流和表数据。
2.2.3.1流对象
流对象是存储层中的一个存储抽象,它有效地支持大规模的键值消息流。它存储消息流的键值对分区,这些分区将组成数据切片的集合。每个数据切片最多包含256条记录。
在将消息写入StreamLake的过程中,首先根据主题、键和偏移量将消息分配给流对象切片,然后,利用分布式哈希表来确保负载平衡存储的均匀数据分布。数据切片将均匀分布到4096个逻辑分片中,而每个逻辑分片都有持久化日志管理的存储空间(Plog)。当收到消息时,Plog单元将其复制到多个磁盘上以实现冗余。用户可以使用键值数据库作为Plog的索引,以便快速查找记录。
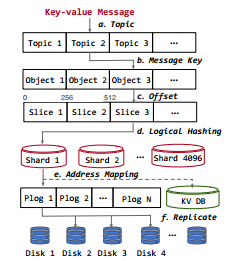
流对象进行写操作
流对象支持的关键操作有:
创建函数CreateServerStreamObject、
摧毁函数DestroyServerStreamObject
传入函数AppendServerStreamObject
读取函数ReadServerStreamObject
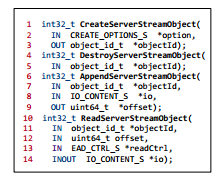
流对象支持的关键操作
2.2.3.2表对象
StreamLake还扩展了其存储对象层,以支持对表的操作,以实现更有效地数据存储和管理。表存储使用开放的Lakehouse格式,将目录放在KV存储中,以实现更快的元数据访问。表抽象由数据和元数据文件的目录逻辑定义.
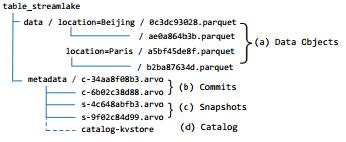
StreamLake表对象的文件组织
(1)数据目录:表对象将被存储在数据目录的Parquet文件中。数据对象通过位置列分隔到不同的子目录中。每个子目录名称表示其分区范围。每个Parquet文件中的数据对象都组织为行组,并以列格式存储,以便进行有效分析。Parquet文件中的页脚包含统计信息,以支持文件中的数据跳过。
(2)元数据目录:用于跟踪表、模式和事务提交等的文件路径,这些文件路径被组织成三个级别:提交(commit)、快照(snapshot)和目录(catalog)。
提交commit:提交是Arvo文件,包含文件级元数据和统计信息,如文件路径、记录计数和数据对象的值范围。每个数据插入、更新和删除操作都将生成一个新的提交文件,以记录数据对象文件的更改。
快照snapshot:快照是索引文件,用于索引指定时间段内的有效提交文件。这些快照将当前文件、行计数和添加/删除的文件/行等统计信息提交为数据操作日志。快照提供快照级隔离,还可以监控所有提交的到期情况。
目录catalog:目录描述表对象,包括配置文件数据,如表ID、目录路径、模式、快照描述、修改时间戳等。
2.3数据服务层
数据服务层提供丰富的功能,支持企业级数据的高效管理。特别是,为了进一步增强该层的功能,作者团队对其进行了扩展,并对专门的服务和日志消息处理操作进行优化,其中包括StreamLake服务来支持实时的消息流式服务和Lakehouse功能,和LakeBrain优化。
2.3.1 StreamLake服务
对于数据服务层中的StreamLake服务,主要包含消息流式传输和Lakehouse形式的读写能力,用于提供全面的,企业级数据湖存储解决方案,可大规模高效存储和处理日志消息。
2.3.1.1消息流式服务
StreamLake中的流式服务主要包括以下几个部分:生产者、消费者、流工作器、流对象和一个流调度器。
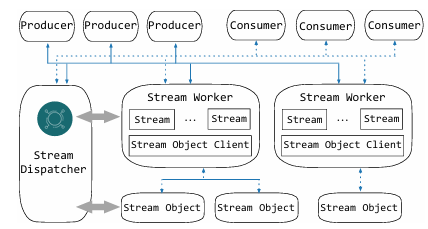
StreamLake的流式服务总体框架
(1)生产者和消费者:生产者负责将消息(msg)发布(send)到主题,这些主题被命名为用于对流消息进行分类的资源。位于下游的消费者订阅(subscribe)这些主题以接收和处理发布的消息。

使用生产者和消费者API编写和阅读消息的过程
(2)流工作器:与流对象一起进行流处理和消息存储。流工作器的数量由配置和分配给流存储的物理资源决定。每个流工作器能够处理多个流和单个流对象客户端。当创建主题时,以循环方式将流添加到流工作器,以确保跨集群的均匀分布和工作负载平衡,每个流都映射到存储层中的一个唯一流对象。
(3)流调度器:流调度器负责管理消息传递服务的元数据和配置,并将外部/内部请求定向到适当的资源以进行消息调度。主题、流、流工作程序和流对象之间的关系作为键值对存储在流调度器内。
流调度器还以主题为单位设置消息传递服务的配置,包括stream_num配置(设置主题的并行度)、quota配置(为每个流设置最大处理速率)、scm_cache配置(允许使用存储类内存(SCM)缓存)等等。
总的来说,StreamLake流式服务为企业提供了有保证的交付、高效的传输和高弹性的服务。
2.3.1.2 Lakehouse功能
在StreamLake中,还实现了从流消息到表格记录的存储转换,以及Lakehouse功能的实现。
流到表的转换过程由后台服务执行,并导致记录从流对象到表对象的转换,从而允许高效的下游处理。为了有效地利用存储,用户可以选择将关键主题中的消息作为流对象保留,以支持实时应用程序,同时将大多数流数据转换为表对象。同时StreamLake也支持表记录到流消息的反向转换,也支持数据回放。这种转换有助于降低存储成本,因为可以只存储一个副本,以实现流和批处理。
对于表格数据处理,StreamLake服务使用表对象和高性能缓存来实现Lakehouse读/写操作,以加速并发数据读写。主要的实现操作如下:
(1)CREATE TABLE创建表格:此操作首先在目录中注册表信息,如模式、路径、数据库和表名。然后在表路径下创建/data和/metadata目录。然后将表配置(模式、分区规范、目标文件大小等)写入metadata目录以进行持久化。
(2)INSERT插入:包括数据和元数据的持久性,以及元数据的缓存。
数据持久性:记录作为Parquet文件直接写入持久层,位于表根目录下相应的分区路径中。
元数据持久性:写缓存中的元数据在缓冲区满时会异步刷新到持久存储池,由元数据管理进程(MetaFresher)将提交和快照从键值对转换为文件,并将它们写入表/元数据目录。
元数据缓存:元数据更新大多是小型I/O操作。为了避免产生大量的小文件,利用写缓存来聚合元数据更新。
(3)SELECT选择:此操作首先读取目录以检索表profile,用于收集本次查询所需的快照文件列表,然后从该高速缓存和持久存储池中读取相应的快照和提交元数据,以生成最新的完整快照和提交元数据。当确认所有记录文件地址时,数据由读任务从持久性池中读取。
(4)DELECT删除:通过SELECT操作查找包含符合过滤条件的记录的文件。如果过滤条件匹配多个分区中的所有数据,则只更新元数据,并通过消除已删除分区的信息生成新的提交版本。如果过滤条件只匹配部分文件,则读取这些文件,并删除符合过滤条件的数据。
(5)UPDATE更新:与删除操作类似,更新操作也使用SELECT语句来标识符合指定条件的记录。通过优化手段(如下推)以减少文件读写过程中的数据移动进行更新操作。
(6)DROP Table删除表:有两种类型的删除表操作:(1)软删除表:从目录中注销表,但在持久层中保留表的元数据和数据,以备将来可能的恢复。(2)硬删除表:将同时删除元数据(/metadata下的文件)和数据(/data下的文件),并从目录中清除数据表。
2.3.2 LakeBrain优化
为了优化数据湖中大规模数据查询处理,StreamLake提出了一种新的数据湖存储优化器LakeBrain,旨在优化存储端的数据布局,从而提高资源利用率和查询性能。此处数据布局是存储分散设计中提高查询性能和存储资源利用率的关键。为了提高资源利用率和性能,LakeBrain采用了自动压缩小文件和谓词感知分区的操作。
2.3.2.1自动压缩
LakeBrain设计了自动压缩,以将这些小文件组合成更少更大的文件,从而提高块利用率和查询性能。通过确认某个状态下的块利用率,LakeBrain会频繁地确定是否合并每个分区中的小文件。当块利用率较低时,就不能简单地压缩文件,因为压缩和数据摄取都需要提交,这可能存在冲突,导致压缩失败,并且压缩会消耗了相对大量的计算资源。此外,许多参数,例如文件摄取速度,目标文件大小等,都会对系统产生影响。每个状态下的操作(即是否合并文件)都会改变一些参数,但它并不单纯影响当前的系统情况,还会影响未来的状态。
因此,为了实现最终高查询性能和高存储利用率,作者提出了一个强化学习框架,可以很好地捕捉每个状态的系统参数与长期收益之间的关系。主要包含以下几个元素:
(1)Agent:是一个自动压缩模型,它从存储系统中接收reward(资源利用率)和state(系统/分区参数),之后更新策略网络以指导是否对每个分区进行压缩操作,以获得最大化长期reward。
(2)State:表示存储系统的当前状态,由多个功能描述这些特征可以被分类为两个集合,一个集合用于整个存储系统,另一个集合用于各个分区。前一个集合包括全局特征,如目标文件大小、摄取速度、查询模式等;后者包括分区特征,如数据访问频率、分区的块利用率等,这两个特征将被连接起来作为策略网络的输入。
(3)Reward:反映了压缩是否有积极或消极的影响。如果压缩成功,则通过分区的块利用率的提高来计算奖励。如果压缩失败,则奖励为(1 -块利用率的预期提高)的负数,得到负回报,意味着在当前状态下估计压缩倾向于失败,并且预期的块利用率改善很小,倾向于不进行压缩。
(4)Action:表示我们是否在每个状态下对每个分区进行压缩,这是策略网络的输出。如果决定进行压缩,我们将使用binpack策略来有效地将小文件合并到目标文件大小。
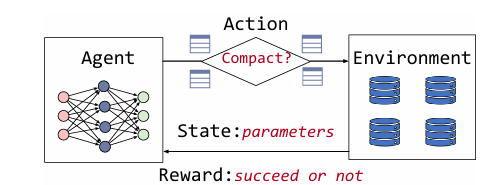
基于强化学习的自动压缩
强化学习训练过程是给定系统中的每个状态,agent通过存储一些经验三元组(state,action,reward),来训练代理的策略网络。这个训练过程重复进行,直到模型收敛。随着流数据不断出现,LakeBrain可以每隔几分钟触发一次训练好的RL模型,以确定是否压缩文件。
2.3.2.2谓词感知分区
为了防止一些分区手段(如哈希函数)导致的不平衡的数据分布,LakeBrain设计了谓词感知方法,以细粒度的方式对数据进行分区,以便给定查询,要评估的元组的数量被最小化,从而提高了效率。
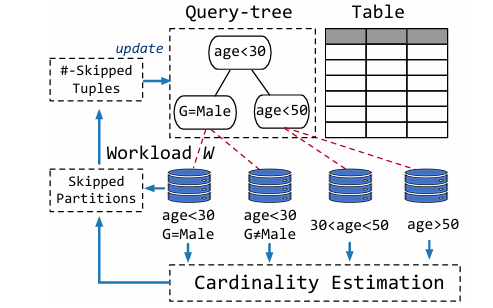
谓词感知分区
具体来说,LakeBrain的划分方法是基于查询树框架,并额外利用基于机器学习的基数估计方法来优化查询树,从而找到一个细粒度的高查询效率的数据划分。给定一个表T和一个由谓词组成的查询工作W,LakeBrain将构建一个查询树,类似于决策树,其中每个内部节点表示谓词, 每个叶子节点引用一个分区.这样当执行W时,LakeBrain可以跳过尽可能多的元组。为了计算跳过的元组的数量,LakeBrain使用AI驱动的基数估计方法(如和积网络),通过学习数据分布来准确有效地估计基数,以达到最好的查询效率。
2.4数据访问层
数据访问层实现存储访问协议来处理用户请求。它支持多种协议访问块服务。StreamLake服务利用了Oceaneclipse分布式并行客户端(DPC),这是一种通用协议-不可知客户端提供更短但超快的IO路径。访问层在管理身份验证和访问控制列表方面也起着至关重要的作用,这确保只有有效的用户请求才能转换为内部请求以进行进一步处理,从而达到安全性和完整性。
3.1实验设置
3.1.1总体性能的基准测试
实验中,StreamLake与Hadoop分布式文件系统(HDFS)和Kafka进行了比较。在实际应用中,许多企业会同时使用HDFS和Kafka来作为存储系统。
HDFS+Kafka:Kafka和HDFS分别作为独立的流存储和批存储,用于在收集、规范化、标记和查询作业之间传递数据。在实验中,存储系统被配置为托管3个HDFS存储节点和3个Kafka集群节点,同时Spark被用作数据处理的计算引擎。
StreamLake:StreamLake作为一个统一的流和批处理存储。我们用StreamLake代替Kafka和HDFS,处理消息流和数据存储。只对计算引擎做了最小的更改,因此业务逻辑保持不变。在实验中,集群由3个StreamLake节点组成,每个节点有24个2.30 GHz内核和256 GB RAM。
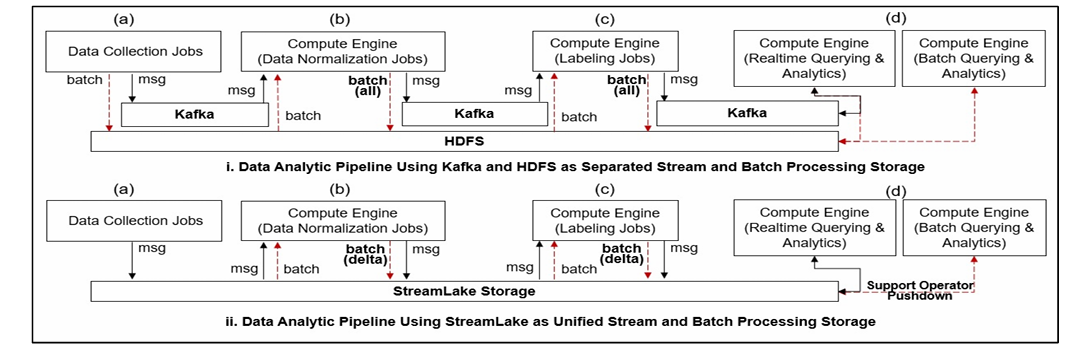
总体性能实验的两个基准:HDFS+Kafka和StreamLake
输入数据量:同时在总体性能评估中,输入数据包的数量不同,有1000万、5000万、1亿、5亿、10亿个数据包,每个数据包平均大小为1.2KB,对应的数据量分别为12GB、60GB、120GB、600GB、1.2TB。
3.1.2其它训练设置
评估消息流式服务:为了帮助更好地理解分层存储的影响,测试了两组硬件配置以评估其吞吐量。在第一组硬件(Set-1)中,每个节点具有10个CPU核心、128 GB RAM和800 GB NVMe SSD、3 PB SAS HDD,并且所有节点都与10Gb以太网连接。在第二组硬件(Set-2)中,除了每个节点都有额外的16GB持久内存作为额外的缓存外,所有配置都是相同的。其中,第二种硬件设置体现的是StreamLake的持久化内存。消息以1KB的固定大小从生产者发送到消费者,数据量分别为100TB、500TB和1PB。
评估Lakehouse元数据加速:为了,关注不同的元数据结构如何影响元数据操作和查询执行。实验中执行了100个真实的查询,使用Where子句条件来利用元数据进行数据过滤。实验中首先使用真实的生产环境的数据,以小时为单位对数据进行分区,即每小时生成的文件放在同一个文件中。实验中的设置一般如下:X轴表示489 000个文件/960个分区(40小时),865,000个文件/1920个分区(80小时),2,1204,000个文件/3,840个分区(160小时),3,947,000个文件/7,680个分区(320小时),4,409,000个文件/9,600个分区(400小时)。Y轴表示元数据操作时间。
评估LakeBrain:
为了准确评估自动压缩策略的有效性,作者建立了一个基于TPC-H的测试床,将消息流平台中的数据摄取到数据湖存储中,在此过程中对压缩策略进行了测试。实验中使用24GB到90GB的数据,并将StreamLake中的自动压缩与默认压缩策略进行了比较,即简单地在30秒间隔内压缩数据文件。实验中基于TPC-H的模式随机生成5,000个查询,并并行执行多轮查询,以获得其端到端性能,训练时间为3.5小时。
为了评估谓词感知分区,实验中作者首先在比例因子为2的数据集中从lineitem表中随机抽取3%的数据来训练概率模型,需要1.5小时的训练时间。随后通过LakeBrain优化了分区策略,并在比例因子为2,5,10和100的情况下对其进行了评估。实验比较了在不同分区策略下行项目表跳过的字节:(1)无分区(Full),(2)按l_shipdate的日期分区(Day),以及(3)LakeBrain的谓词感知分区方法(Ours)。
3.1.3评估指标
存储空间使用(GB):反映系统的存储成本。
流处理速度(消息/秒):代表系统每秒处理了多少消息。
批处理总时间(s):反映系统对批处理的速度。
延迟(ms):指从输入到输出最后一个 token 的时间。
吞吐量(MB/s):指单位时间内系统处理的任务数。
3.2实验结果
3.2.1总体性能
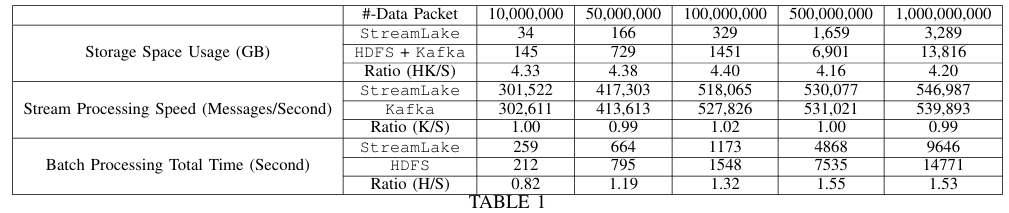
HDFS+Kafka和StreamLake的总体性能比较
在总体性能比较表中,最上面一行是输入数据包的个数,下面一行是StreamLake(S)、HDFS(H)、Kafka(K)的存储使用量和处理时间,HK表示HDFS和Kafka的存储使用量之和。其中,Ratio表示HDFS/Kafka和StreamLake在存储使用量或处理时间上的比值。
实验表明,StreamLake显著改善了总存储成本和批处理时间。首先,HDFS和Kafka的存储成本是StreamLake的4倍,这是源于HDFS和Kafka在每个ETL作业完成时都会将全部数据写入存储;而对于treamLake,通过流到表转换和Lakehouse功能,对每个ETL作业只需保存一份完整数据和更新,节省了75%的存储成本。
在批处理速度上,StreamLake中在工作负载为5000万条记录以上时优于HDFS,随着工作负载的增长,StreamLake在工作负载为5亿条和10亿条记录时比HDFS快50%,因为StreamLake使用了LakeBrain优化器和元数据加速来提高效率。另一方面,StreamLake可能不是小工作负载的最佳选择,当工作负载为1000万条记录时,StreamLake为20%比HDFS慢,因为它执行额外的元数据管理。
在消息流处理速度上,StreamLake中的与Kafka相当。StreamLake和Kafka当工作负载为1000万条记录时,每秒处理约30万条消息。当工作负载为1亿条或更多时,两个系统都可以扩展到每秒处理约50万条消息。
3.2.2评估消息流式服务

消息流式服务实验结果
在评估消息流式服务实验中,展现了两种硬件环境的延迟、吞吐量、扩展时间和空间消耗方面的结果。
首先,持久化内存减少了延迟,特别是当工作负载为每秒200k条消息或更少时,效果更为显著。对于吞吐量来说,当要处理的消息从每秒50000个增加到每秒150万个时,两种系统吞吐量都呈现线性增加。此外,流式服务还体现了高弹性,能够在不到10秒的时间内从1000个分区扩展到10000个分区。最后,实验比较了不同存储策略的空间消耗,结果显示,StreamLake提供的使用擦除编码和列存储的选项(EC和EC+Col-store),与复制方法相比,可以节省三到五倍的存储成本。
3.2.3评估Lakehouse元数据加速
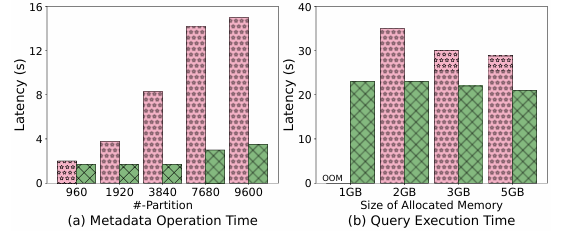
Lakehouse元数据加速实验结果
为了评估Lakehouse元数据加速,实验比较了元数据操作的延迟时间和查询运行的延迟时间。
首先,随着分区数量的增加,没有元数据加速的方法的延迟线性增加,而Lakehouse加速方法则令延迟适度增加。当分区数增加10倍时,差异变得更加显著。其次,当使用Lakehouse元数据加速时,查询执行速度更快,更稳定。比如当内存为1GB时,由于元数据加速一定程度补充了计算引擎的内存分配,令StreamLake系统更加高效和稳定。
3.2.4评估LakeBrain
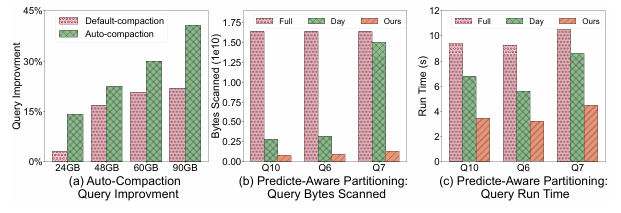
LakeBrain实验结果
对于评估LakeBrain的效果,实验分为评估自动压缩和基于谓词的分区:首先,实验结果表示,与默认压缩策略相比,自动压缩策略可以提高查询性能。对于所有数据量,自动压缩策略都优于默认压缩策略。随着数据量的增加,由于要访问的块的数量减少,因此优势变得更加明显。在块利用率方面,自动压缩也始终优于默认压缩,在系统运行期间平均实现约50%的高块利用率,同时系统采用强化学习来识别最佳压缩机会,优先考虑大量小文件和低文件摄取速度和块利用率的场景。而对于基于谓词的分区的评估,实验中显示,LakeBrain方法优于无分区(Full)和按l_shipdate进行分区(Day),在更精细的数据跳过和查询运行时改进方面尤其明显。
4.1数据湖存储系统
近年来,一些存储产品比如Dell EMC,NetApp等虽然能够通过连接器支持HDFS协议到NFS或SAS/iSCSI/FC在块/LUN设备上实施,为客户提供企业级可扩展性和高可靠性,但其对分析效率的支持主要依赖于分析引擎合作伙伴。在此情况下,AWS、Azure、Google Cloud和阿里云提供了丰富的存储服务组合,以在云中构建数据湖。这些云存储服务松散连接,以支持消息和批处理。而本文中的StreamLake将消息流、Lakehouse和持久存储紧密集成在单个系统中,效率更高,更具成本效益。
4.2消息流
Kafka、Pulsar和Pravega都是业界流行的开源流媒体平台。与StreamLake不同,StreamLake使用流对象和PLogs构建其消息服务,而这些平台是基于文件的,需要手动连接到计算引擎和外部存储,例如HDFS,用于下游处理或成本友好的归档。这增加了数据管道管理的复杂性和成本。
4.3 Lakehouse
Iceberg、Hudi等是顶级的Lakehouse数据管理框架,它们以流行的文件格式存储数据用于分析。StreamLake将Lakehouse框架构建在表对象存储和PLogs之上,提供高扩展性和可靠性。此外,元数据加速和动态数据布局优化促进了具有改进的速度和可靠性的并发Lakehouse操作。
4.4自动数据库调优
近年来,人工智能在数据库系统中被广泛使用,以提高性能。例如,OtterTune是一个经典的基于ML的框架,推荐使用高斯过程的旋钮配置。此外,CDBTune采用RL来迭代探索最佳配置,以及QD树提出了贪婪算法和基于强化学习的算法来进一步优化分区策略,但它们需要通过采样或扫描来量化分区基数,这不够准确和有效。
作者团队开发了StreamLake,通过分散式架构将流和批处理数据处理与高弹性,可靠性,可扩展性和效率相结合。该系统包含Lakehouse功能,以确保表格数据的ACID合规性,并部署LakeBrain进行查询和资源优化。
论文解读联系人:
刘思源
13691032906(微信同号)
liusiyuan@caict.ac.cn





