




引言
在大语言模型(Large Language Models, LLMs)的应用中,生成文本的质量与多样性是核心挑战之一。为了在“确定性输出”与“创造性生成”之间实现平衡,研究者提出了多种解码策略参数,其中温度(Temperature)、Top-K和Top-P(核采样)是最关键的调控工具。本文将从技术原理、数学定义、参数调控策略及实际应用场景等方面,系统解析这三类参数的作用机制,并通过代码示例与案例分析,提供实践指导。
一、温度(Temperature):概率分布的平滑控制器
1.1 技术原理
温度参数通过调整模型输出的概率分布形态,控制生成结果的随机性。其核心数学原理是对模型输出的原始logits进行缩放,再通过softmax函数生成最终概率分布。公式如下:其中:
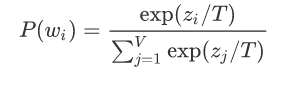
( zi ):模型对词( wi )的原始logit值
( T ):温度值
( V ):词表大小
当( T > 1 )时,概率分布趋于平缓,低概率词被提升;当( T < 1 )时,概率分布趋于尖锐,高概率词被强化。
1.2 参数影响
低温度(T=0.1~0.5):输出高度集中于头部高概率词,适合事实性问答。例如:
input_text = "水的化学式是"
model.generate(input_text, temperature=0.3)
# 输出:"H₂O"中等温度(T=0.7~1.0):平衡多样性与合理性,适用于对话生成。
高温度(T=1.2~2.0):长尾词概率显著提升,可能产生出人意料的创意输出,但需警惕逻辑错误。例如:
input_text = "时间旅行者的背包里装着"
model.generate(input_text, temperature=1.5)
# 输出:"一罐凝固的星光和祖父的怀表"
1.3 应用场景
代码生成:需严格遵循语法规则,建议:T<=0.3
诗歌创作:鼓励非常规词汇组合,可设:T>=1.2
二、Top-K:限定候选词范围的硬截断
2.1 算法逻辑
在生成每个token时,模型仅保留概率最高的前K个词构成候选集,然后在该集合内按重新归一化的概率分布进行采样。数学表达式为:
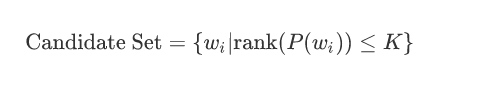
2.2 参数选择
小K值(K=10~30):生成结果稳定但可能缺乏新意,适合技术文档生成。
input_text = "深度学习的核心组件包括"
model.generate(input_text, top_k=20)
# 输出:"神经网络层、损失函数和优化器"大K值(K=100+):允许更多低频词进入候选集,适合开放式创作。例如生成科幻设定:
input_text = "外星文明的能源来自"
model.generate(input_text, top_k=150)
# 输出:"量子真空涨落与暗物质共振"
2.3 局限性
固定K值的缺陷:当模型对某一步的预测概率分布极度集中(如99%概率集中于前3个词)时,设置K=50会造成资源浪费;反之若分布平缓,K=10可能遗漏合理候选词。
三、Top-P(核采样):动态候选词筛选
3.1 算法原理
Top-P通过累积概率动态确定候选词集合:
按概率降序排列所有词
选择最小的词集,使其累积概率≥P
仅在该集合内采样
数学形式化表示为:
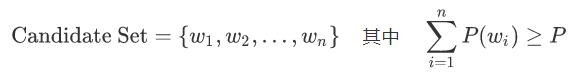
3.2 参数调控
低P值(P=0.5~0.7):候选集窄,输出确定性高。适合事实性陈述:
input_text = "珠穆朗玛峰高度为"
model.generate(input_text, top_p=0.6)
# 输出:"8848米"高P值(P=0.9~0.95):允许更多低概率词参与,适合生成隐喻性表达:
input_text = "她的眼神像"
model.generate(input_text, top_p=0.95)
# 输出:"冬夜里的最后一盏路灯,孤独但温暖"
3.4 与Top-K的对比
| 特性 | Top-K | Top-P |
|---|---|---|
| 筛选方式 | 固定数量 | 动态概率阈值 |
| 适用场景 | 分布均匀时 | 分布陡峭/长尾时 |
| 计算效率 | 稳定 | 需排序,稍高开销 |
四、参数组合策略与调优实践
4.1 联合使用原则
温度与Top-K/P的协同:温度调整整体分布的陡峭程度,而Top-K/P控制采样范围。二者结合可实现细粒度调控。示例:创作悬疑小说开头
model.generate(
"教堂钟声敲响第十二下时,",
temperature=1.2,
top_k=100,
top_p=0.85
)
# 输出:"地下室传来铁链拖动的声响,却找不到任何人的踪迹。"
4.2 推荐配置模板
| 任务类型 | 参数组合 | 说明 |
|---|---|---|
| 学术论文摘要 | T=0.4, K=40, P=0.6 | 抑制发散,保持术语准确性 |
| 社交媒体文案 | T=0.9, P=0.8 | 适当活泼,避免过于正式 |
| 多轮对话 | T=0.6~0.8动态调整 | 根据对话历史调节创造性 |
4.3 调优方法论
基准测试:固定其他参数,单变量调整观察影响
领域适配:法律文本需更低温度(T≤0.3),广告文案可升高至T=1.0
异常检测:监控重复生成(温度过低)或逻辑断裂(温度过高)
五、实际应用案例深度解析
5.1 案例1:智能客服系统
需求:精确回答用户问题,避免自由发挥
参数配置:
response = model.generate(
user_query,
temperature=0.3,
top_p=0.5,
max_length=100
)效果:输出严格基于知识库,如询问“退货政策”时,仅返回条款细节。
5.2 案例2:AI辅助编剧
需求:生成多个剧情走向提案
参数配置:
plot_ideas = model.generate(
"主人公发现了一本神秘日记,",
temperature=1.5,
top_k=200,
num_return_sequences=5
)输出样例:
"日记的每一页都在自动书写未来的事件。"
"原来这是反派故意留下的陷阱,字迹会逐渐消失。"
5.3 案例3:教育问答引擎
需求:平衡准确性与教学启发性
动态调整策略:
ifquestion_type == "factual":
params = {"temperature": 0.2, "top_p": 0.4}
else: # 开放性思考题
params = {"temperature": 0.7, "top_k": 50}
六、高级技巧与前沿进展
6.1 温度退火(Temperature Annealing)
在生成长文本时逐步调整温度:
初始段落用较高温度(T=1.0)激发创意
后续段落降低至T=0.6维持连贯性
6.2 基于强化学习的参数优化
将温度、Top-P作为可学习参数,通过用户反馈信号(如点赞/修改次数)自动优化。
6.3 硬件级优化
Top-P的快速实现:使用前缀和+二分查找降低排序时间复杂度
GPU并行采样:同时对多个候选序列应用不同参数组合
七、常见问题解答
Q1:温度设为0会发生什么?
模型将始终选择概率最高的词(贪婪解码),导致重复且缺乏多样性的输出。对于技术类或理工科,答案需要唯一的这种,例如Text2Sql领域中,建议温度值为0.
Q2:Top-K与Top-P是否需要同时使用?
通常二选一即可。若同时设置,实际候选集为两者的交集。
Q3:如何避免生成有害内容?
组合使用低温度(T=0.2)+ 内容过滤器,限制高风险词进入候选集。
结语
温度、Top-K和Top-P的灵活组合,为LLM生成结果的可控性提供了多层次解决方案。开发者需深入理解各参数的数学本质,结合实际场景需求,通过系统化实验找到最佳配置。随着自适应参数调整技术的发展,未来或将实现更智能的上下文感知生成策略。
往期精彩
晋升答辩提问:既然业务需求已经很明确了,你数仓建模的价值体现在哪?
