





导读 今天的分享主题是如何以数据驱动的方式,高效地进行数据治理。
全文目录:
小米数据治理里程碑
随着数据量的不断增加,数据治理已经成为了企业管理里不可或缺的一环。数据治理可以帮助我们更好地进行数据的管理和使用,从而提升数据的质量和价值,同时也能够保证数据的安全和合规。本次分享将从数据分析的角度给大家介绍小米公司基于“资产健康度量”模型的数据治理实践方案。
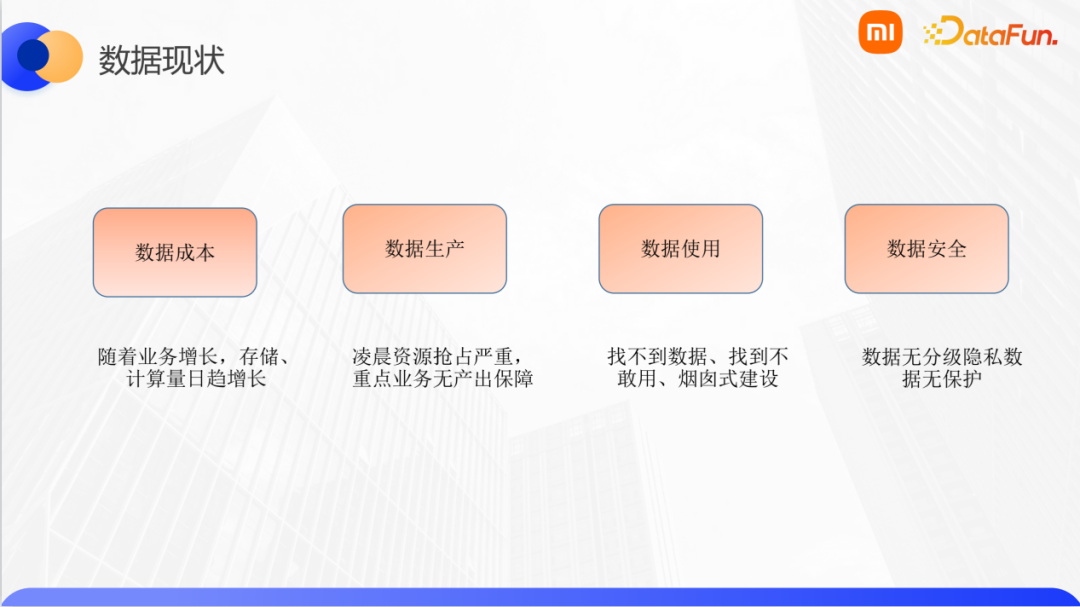
小米数据治理中主要面临的问题有:
数据成本:随着业务的不断增长,数据存储、计算成本也随之增长。数据成本的可持续性和可控性是一个亟待解决的问题。
数据生产:数据的汇聚、清洗、建模、计算等过程依赖大规模的离线计算,且时间点集中,如何对数据产出的准确性和时效性进行保障也是个重要问题。
数据使用: 找不到数据,或者找到数据不敢用,数据来源、口径、维护等没明确的owner,使用方对数据的信任度不高,造成了数据的使用率不高。
数据安全: 没有完善的流程机制以及规范等策略来进行数据管控,比如数据未分级、隐私数据没有保护等。
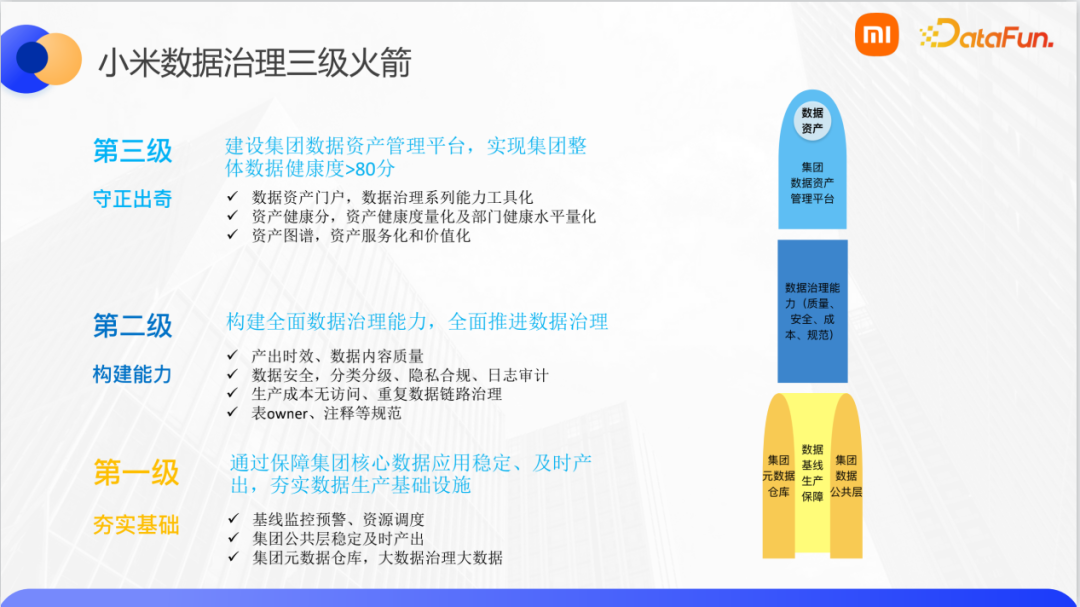
基于以上的数据现状,数据治理团队制定了一个三级火箭方案:
在第一级,一方面建设了基线能力,保障公共层核心数据的稳定及时产出。具体做法是根据数据作业的重要程度,进行分级的调度资源,此外还配置了预警监控;另一方面则建设了集团的元数据仓库,对数据存储计算系统、数据表,离线数据作业等相关的所有元数据,以及访问、操作等相关的日志数据做了整体采集建模,然后去中间层的数仓进行建设产出。这一部分为后续的以大数据治理大数据和数据健康度量化提供了基础数据保障。
第二级则重点构了数据治理方面的产品工具能力,借此更好的进行全面的数据治理。首先在数据内容质量和产出时效性上做了完整的监控,并设计和研发了数据质量管理系统。在数据安全方面,设置分类分级的规范,针对不同的分级会有相应的比较完善的权限管控、隐私合规以及日志审计相关的一些产品、策略和流程。在数据成本方面,对无访问的数据表、以及重复数据链路进行相应的治理操作,为后续进行资产健康度量积累扎实可靠的实践经验。最后在规范层面,完善了数仓整体的开发建模的规范,做到数据统一的开发和管控。
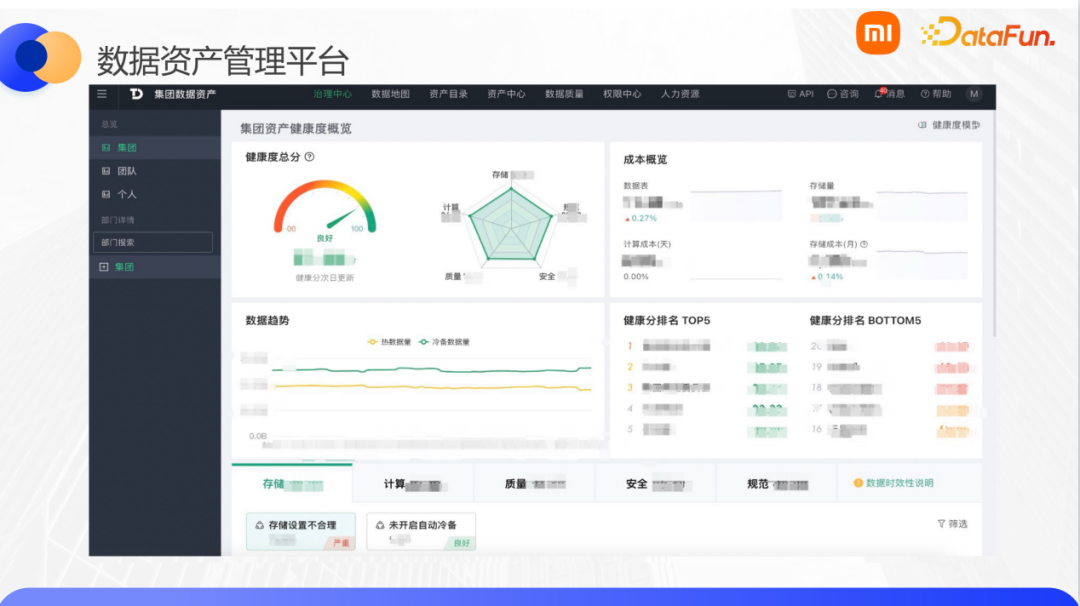
第三级则主要解决常态化运营数据治理工具的问题,比如如何可监控、成体系、闭环地展示数据治理过程中的现状、问题、以及治理效果等。因此,我们设计了一个资产健康度的量化模型。“健康分”指标作为衡量数据资产健康度的北极星指标。通过健康分去识别存储计算、安全、质量、规范等方面不合理的地方,并定位到特定的不合理特征项,最后针对每一个特征项提供相应的治理策略或建议。我们通过沉淀数据治理能力并且工具化,打造了个一站式个数据治理操作平台,帮助业务团队高效地进行数据明细的了解、治理、降本等操作。
02
资产健康度量化及产品化
资产健康度量化模型及产品化是本次分享的核心,也是三级火箭治理方案中第三级的核心。
其核心思想是用大数据来治理大数据,具体从存储、计算、规范、质量、安全五个方面着手,实现数据资产化。首先在底层,我们依托源数据仓库、调度系统等将数据表、离线\实时数据作业等数据系统的数据源、数据血缘、数据操作日志等信息进行采集,这些采集为从存储、计算、规范、质量、治理五个方面构建资产健康度量化模型打下了坚实的数据基础,我们在这五个方面分别定义了一个子项健康分,然后平衡加权得到一个总的健康分,从而相对客观地去衡量数据资产的健康程度。
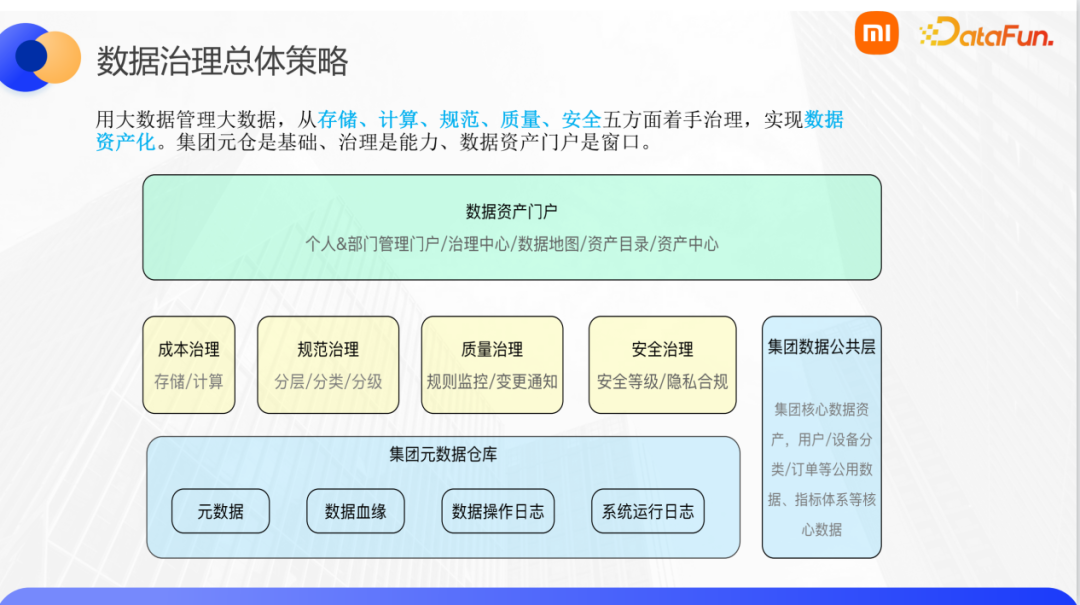
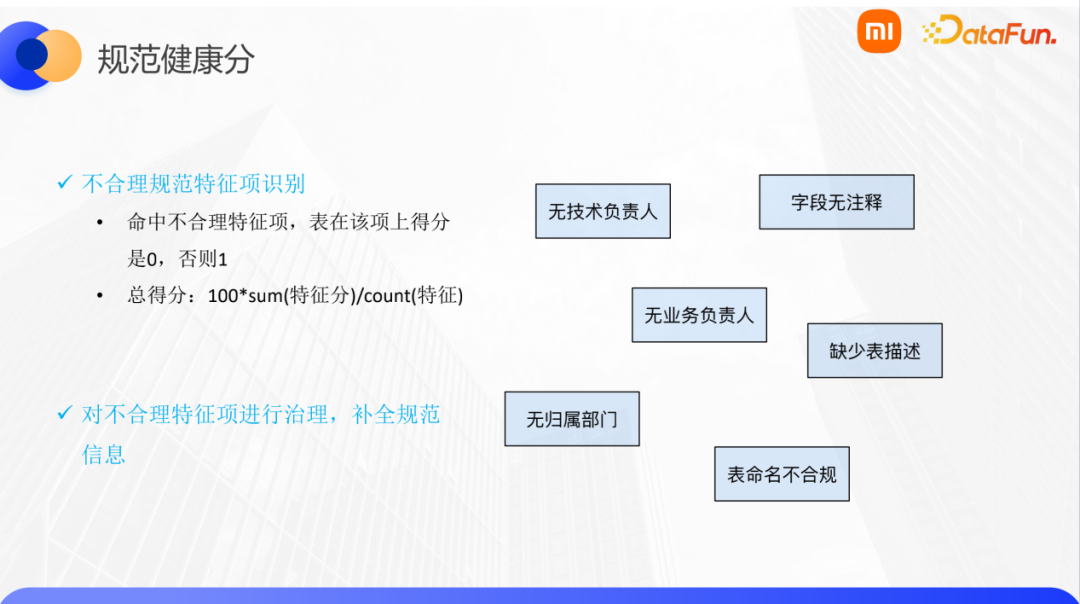
设计度量模型首先需要解决的一个问题就是可量化,也就是我们指定的“健康分”确实需要能真实度量并反应数据在存储、计算、质量、安全、规范五个方面的一个实际表现,包括表现数据的生产和使用等。第二个需要解决的问题是可解释性,我们不仅要告诉业务方健康分是多少,哪些方面的健康分低,还需要告知为什么低,也就是具体的健康分计算逻辑。此外,计算的逻辑也需要符合业务的实际情况,这样才能够让用户去信任度量模型评估出来的分数,并做相应的操作。第三个问题则是需要有操作,度量后需要有配套的一个治理方案和操作工具支持。模型想达到的最终应用效果就是能让用户快速及时的进行正确的治理操作。
接下来介绍健康分的计算逻辑。首先我们对每一个表设置一个100分制的健康分,然后以表的维度做汇聚可以得到个人、库/集群、业务板块、各级部门甚至整个集团的健康分。健康分可拆解成规范、存储、计算、质量、安全这五个方面的子健康分,最终的健康分是以每个子健康分加权得来,权重则会参考表存储量按一定的规则来进行设定,每一项子健康分也是根据每一项监控特性得来,以此做到分数可溯源可解释。

细拆每个子项健康分的计算逻辑如下:
我们对数据表设计了一个分类体系,基于每一个分类又设计了一套计分策略。对于新表(如三个月内创建的), 由于没有积累足够的访问和使用数据,我们没有足够的依据判断是否需要治理,因此新表阶段会统一打分80分,等到访问和使用数据积累到一定程度后再用数据辅助判断。对于旧表(如三个月以前创建),我们认为已经积累了足够的访问和使用数据,可以基于这个数据进行后续的治理判断,基于此我们还可以更进一步区分表是否是分区表。如果不是分区表,我们会看最近比如三个月内是否有访问,如果没有则判定为0分,建议Owner清理或者下线该表,有访问则判定为100分,暂时不用治理。如果是分区表,则判断该表是否是需要永久保存的,一般是无法根据其他数据溯源的源数据表或者大周期加工的表,如果是,则可以打标签为永久保存表或者白名单,不进行治理,打分100分;如果不是,则建议进行生命周期TTL管理, 这部分表的存储健康分是根据系统建议生命周期TTV 和用户设置的TTL进行计算的 具体计算公式是先根据历史一定时间段内访问的最大时间跨度,加上一定的系统冗余,计算出系统建议的TTV值,然后除以当前表的生命周期值,再乘以100。此策略就是希望用户将生命周期TTL调整成系统建议的TTV。
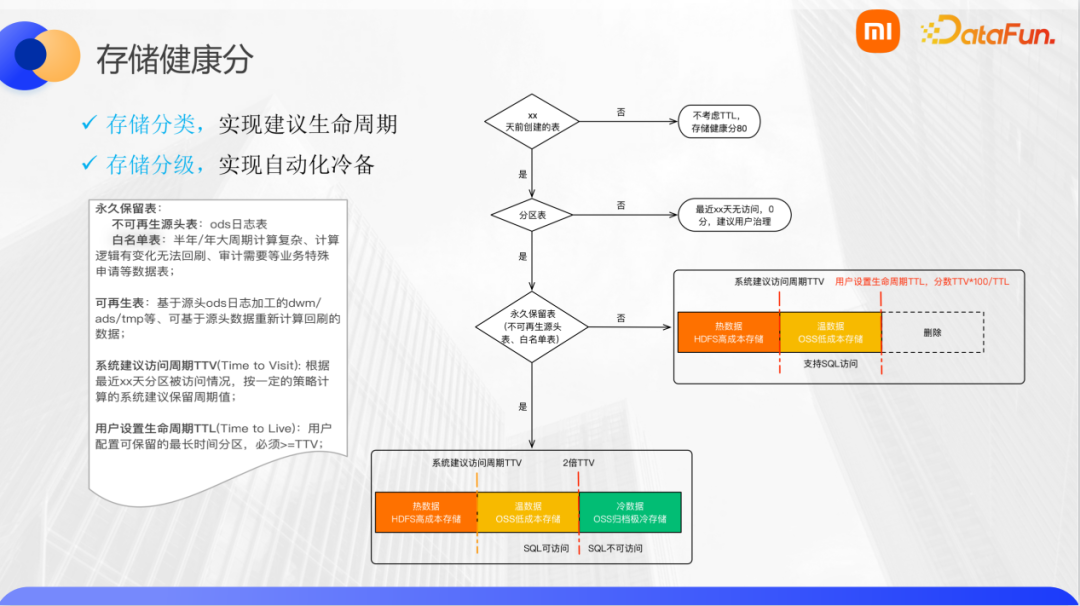
当然,如上图所示,除了分数管理,我们对存储上也做了一个热、温、冷的分级数据存储管理,来节省存储成本。
计算健康分是基于积累的数据治理经验沉淀出来的。主要是量化一些计算过程中不合理的特征进行计算,比如说数据倾斜、作业连续运行失败、数据的重复计算、相似计算。比如有些下游作业只是简单的对上游表做了select操作,然后就存储了一张下游表,这其实会造成存储的极大的浪费,或者两个业务人员用了相似的计算逻辑产出了两张相似的表也会造成存储浪费,这些我们都会进行识别和特征打分,相似度大于50%计0分,小于50%则为1分。此外,如果作业正常产出很长一段时间后都没有下游依赖作业或者访问量我们也可以判断它可以暂停调度。最终计算健康分就是这些特征的得分,除以特征的计数,再乘以100。 在计算资源上我们也做了一个量化,定义一个cu 等于1cpu=4GB 的内存运行1秒的算力,通过这个基本单位去量化每一个SQL,每一个作业运行时消耗的资源情况,同时会针对资源消耗Top的作业进行高效的治理,对得分低的计算特征也会给用户制定详细的指导策略。

质量方面分为数据内容质量和生成质量,我们设计了一整个质量管理体系,并开发了质量监控系统,主要的监控规则如下图所示:

此外,对应用场景重要且丰富的高资产等级表会进行加强管控,会强调一些表级、字段级、及时性监控。
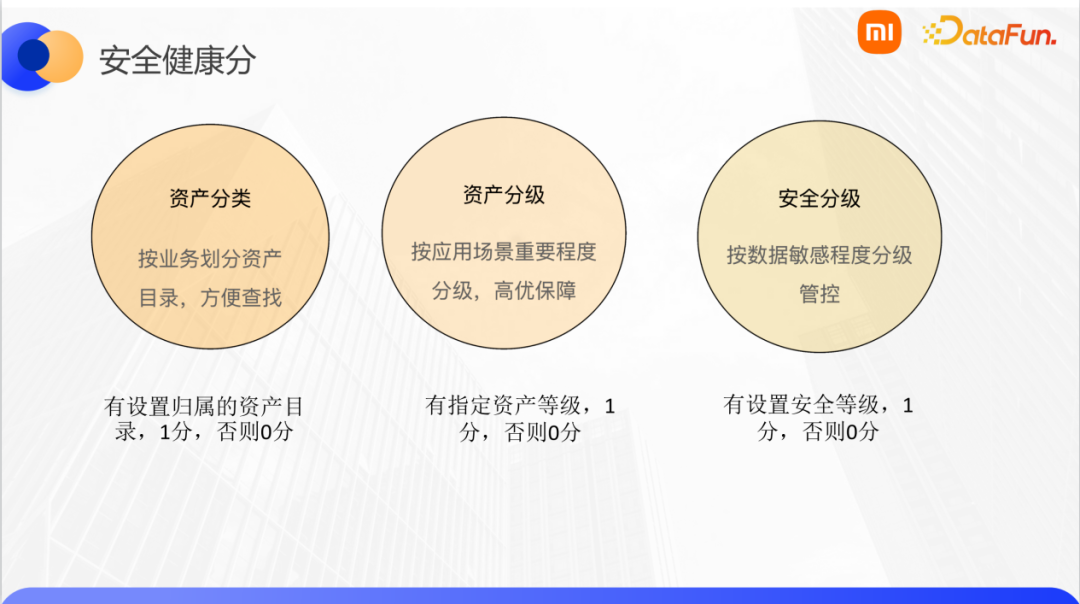
安全健康分主要分资产分类、资产分级、安全分级设置三个方面。资产分类是把表归属到某个资产目录下,方便统一管理和查找使用。资产分级是用来衡量数据应用场景的重要程度,越高资产等级的数据,会高优保证它们的资源调度,保障产出的稳定性。安全等级则设置了L1到 L4,从1到4,安全等级逐渐升高,比如用户ID、电话号码、地址以及聊天记录等个人敏感信息都是最高安全等级数据,从管控粒度上来说可以细到字段级的安全等级。安全分数计算规则跟计算健康分一样,就不再赘述。
03
未来规划
以上介绍了资产健康度量化及产品化方案,未来将在当前基础扩展以下几点:
① 丰富健康度量特征项:当前的健康度量化模型还远远不够,后续将不断完善扩充不合理的特征,提高能识别的场景覆盖率。
② 丰富数据场景:当前主要包括离线的存储与计算,后续考虑将实时数据和实时作业调度系统纳入进来,实现全方位的在线化的治理管控。
③ 多元化资产价值:当前资产价值主要几种在生产和使用环节,后续考虑构建资产图谱,进一步分析资产的访问和依赖情况,并生成衡量资产价值的价值分模型,从而根据价值分更严格的或者更个性化的去进行管控。
④ 事前管控:当前的治理更多的是事后管控,但更高效的是事前管控。现整个数仓的建模、开发等规范相关的还是人工维护和实施的状态,后续会考虑以onedata这样的方式建模线上工具化能力。
⑤ 数据应用治理:现有的数据资产应用场景非常多样,包括OLAP查询和产品数据服务等。当前不同的场景的数据链路以及技术选型都不一样,因此还没有做到应用层的统一管控。后续会规划在数据应用层做统一的数据服务。
05
A:一种是主动的方式,比如说每周发治理周报,把用户当前他所在数据层面有的不合理项,以及每一项下面的数量等,通过消息的形式主动触达用户。不会每个治理项都发送一个消息,我们以整体的周报方式每周推送一次消息给用户,并且如果长时间没有做治理的话,就会将健康分等推送到你的主管或者更上级等,通过这样一个机制来做到一个相应的管控。
A:因为我们有元仓的建设,我们会把每个表的访问日志做数据采集,包括访问时间,访问的数据量等,依此可以统计访问频次和访问量。判断开始是否符合规范也是基于元仓数据,通过表的元数据判断是否有注释、owner等,通过表名拆解判断是否符合命名规范。
A:数据应用治理这一块目前主要是在建设产品工具能力的层面。不知道大家是否听过类似 one service,就是统一数据服务。先是在底层把数据资产做业务语义建模,业务语义建模的定义就是在拿到物理表后我们对它做维度和指标以及衍生指标的定义,定义完成后我们会在数据商城做统一的数据服务层。建设后,上层通过我们中间这层数据服务层进行服务,比如OLAP场景,我们可以把它作为BI产品的一个数据源,然后以它来配置相关的一些数据看板等,另外也可以配置HBASE或者KV查询等数据服务场景,所有的应用场景下用户都可以通过这个语义模型层去配置和使用数据源,这样可以减少重复开发工作,提高用户的数据使用效率。同时也方便我们收集统一的数据,然后对数据应用做统一的管控,也能够达到数据口径的统一。

分享嘉宾
INTRODUCTION

孟熠
小米
数据解决方案架构师、数据分析师
中山大学信息科学与技术硕士,9年工作经验,曾任职阿里巴巴达摩院数据技术专家负责智能客服数据相关工作,现任职小米担任数据分析工作,负责数据驱动产品业务、数据系统高效降本提效,以大数据治理大数据,沉淀方法论、工具平台实现常态化数据治理。

