导读 Impala是一个高性能的MPP查询引擎,纯计算无状态的特性使其天然就适合数据湖的场景。本次分享将介绍Impala中的性能优化,包括Iceberg和Codegen相关的优化等。
01
Impala与数据湖
首先来看一下Cloudera的数据湖概览。在每个层面都有多种系统供选择,比如数据导入的系统,可以是Hive、Spark、Flink等;数据的存储可以是HDFS、Ozone,以及各种云存储等。数据的文件格式也是多种多样的,比如Parquet、ORC、Avro等。在数据组织方面,我们期望以Iceberg的table format来做统一的数据层,支撑数据湖分析的多种场景,如Hive负责的ETL、Impala负责的交互式分析等。要对接如此多的系统和格式,保持开放性(Openness)是至关重要的一点。
Impala是一个SQL查询引擎,提供交互式的查询。它天然就适合数据湖场景,因为其数据和元数据都保存在外部存储上,本身无状态,而且只有计算节点,很容易做到存算分离。另外,Impala也是一个高性能的查询引擎,它使用MPP架构设计,基于内存计算,内核是用C++编写的。最值得一提的是Impala对Openness的支持,作为数据湖上的查询引擎,它支持Open Storage,如HDFS、Ozone等。数据存储在这些Open Storage中,Impala没有自管存储。它支持Open File Format,如Parquet、ORC等开放、标准的文件格式。Impala没有自定义的文件格式。另外,它也支持Open Table Format,如Iceberg、Hudi等。在安全的集成上也较为成熟,比如授权、鉴权、血缘追踪、审计、脱敏等。
Impala架构如下图所示,橙色为外部系统。Impala有两个master节点,一个是Statestore,主要负责集群的心跳监测、新节点的发现和元数据的广播等;另一个是Catalog Server,主要负责跟外部系统的元数据打交道,同时也会缓存这些元数据。中间是执行层,有两种角色,一种是coordinator,一种是executor。Coordinator负责跟客户端打交道,接收查询请求并调度到集群中执行,最后返回结果给客户端。Impala中的Coordinator可以有多个,原生就是HA的。Executor负责查询的分布式执行,是集群的worker节点。下面一层是外部的存储,如HDFS、Kudu等。从图中也可以看出,如果往Impala集群里写数据,实际上是写到底层的外部存储,Impala自己是不保存任何数据或元数据的。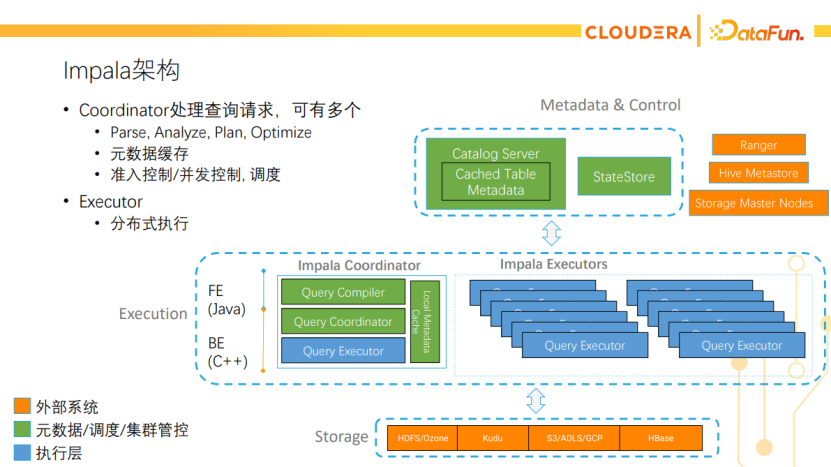
值得一提的是,Impala的开源免费版就有丰富的WebUI。这里展示了查询页面的截图,所有查询包括正在运行的、失败的都可以在页面上看到。
点击链接可以看到profile,里面有非常详细的执行细节。另外也有可视化的Query Plan,可以很直观的看到查询的瓶颈在哪里。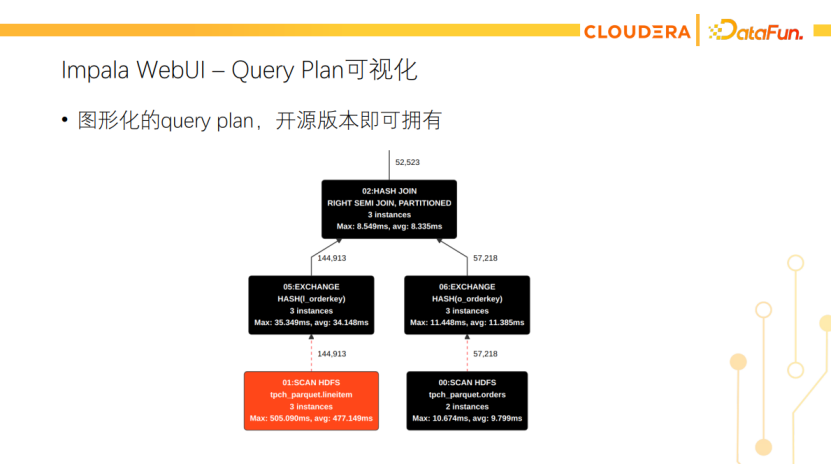
最近我们又增加了Timeline展示的页面,可以更直观地看到整个查询的执行进程。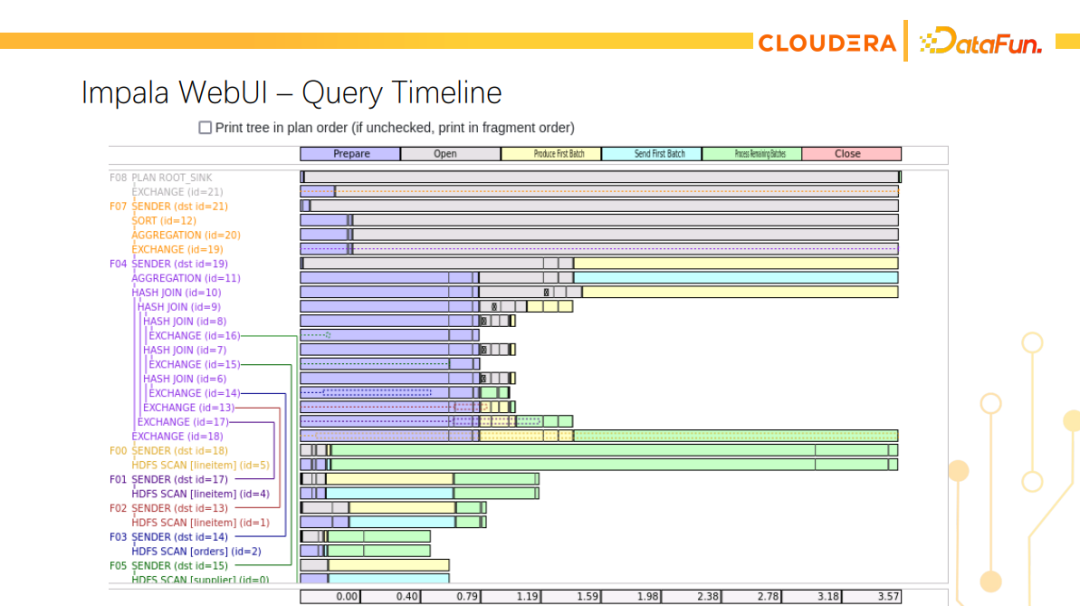
再看一下Impala的发布历史。Impala开发的比较早,在十年前就已经开始开发了,去年底发布了4.2版本。下一个版本是4.3,还在规划中。网上有一些做Benchmark对比的文章,使用的Impala都是CDH5或CDH6的版本,这些版本都是四五年前的版本了。Impala在这四五年间做了很多优化,所以大家如果测试的话,建议使用4.2或即将发布的4.3版本。
数据湖查询引擎的性能优化
Impala是一个数据湖的查询引擎,数据湖查询引擎的优化相比于传统数仓的优化,有很多局限性,其中一个挑战就是源于对开放性即Openness的支持。为了支持Open File Format和Open Storage,很多层面都已经解耦了,所以很难做一些高耦合的优化。比如数据预排序,这个在湖仓需要生产者支持,在数仓都是自管的,就可以做这类的优化。如果能保证数据有序的话,那简单的一些min/max查询都有可能只读首行末行就能结束这个查询。对排序列做join或聚合时,也可以基于有序做merge-join这类的优化。但在数据湖场景中,数据生产者不可控,我们只能做一些保守的优化,比如基于文件的min-max索引做谓词下推。当数据有序时,min-max索引更高效。当数据无序时,查询结果也不会出错。还有像全局字典、全局索引这些都不可控,只能利用文件级别的。
当然数据湖查询引擎也有很多优化点可做,可以分几层来看,如下图。比如纯查询计划层的优化,有谓词推导/下推、常量传播、子查询改写等。也有一些要结合执行层一起做的优化,像预聚合、Runtime Filter等。还有一些纯执行层的优化,像运行时的代码生成、向量化执行、使用SIMD来加速等。IO层的本地短路读、异步IO等。缓存层也可以做很多优化,比如元数据或原始数据、中间数据的缓存。包括物化视图,也可归为中间数据的缓存。很多优化点都可以单独拿出来做专题研究,Impala在很多方面也深耕多年。由于时间关系,本次分享主要介绍Impala在Iceberg上的优化,侧重查询计划层;以及Impala在Codegen上的优化,侧重执行层。
Iceberg的诞生主要是为了替代传统的Hive表格式。Iceberg也是一种table format,传统的Hive表是把元数据存在关系型数据库,像MySQL等,还有部分元数据是放在文件系统的目录结构里的。在大数据的场景下,元数据渐渐变成了大数据,所以Hive的扩展性也受到了很大的限制,Hive上云也遇到诸多局限性。所以后来出现了Iceberg这种表格式,它的最主要的特点是用文件来保存元数据,包括每个分区有哪些数据文件等。从Iceberg的架构图上可以看到,它除了正常的数据文件外,还有很多元数据的文件用来描述这些数据文件是怎么组织的。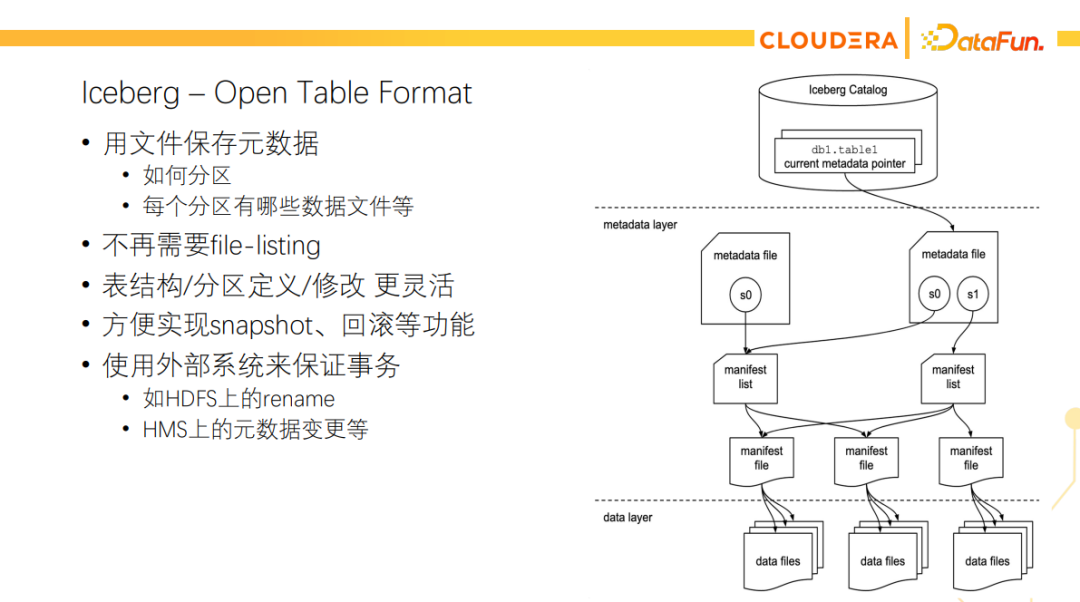
Impala对Iceberg的支持开发的比较早,所以大部分的功能都支持。支持常见的Iceberg Catalog,如HadoopTables、HadoopCatalog和HiveCatalog等。还有各种snapshot操作和历史版本查询等。更详细的功能表可以通过下面的链接去查看。https://impala.apache.org/docs/build/html/topics/impala_iceberg.html
接下来介绍Impala在Iceberg V2上的工作。Iceberg V2是一种merge-on-read的设计,加入了delete files的概念。它会标记哪些数据是失效的,读的时候需要把它们和数据文件合并,才能展示真实的数据。Delete file有两种,一种是position delete file,主要是基于位置的delete,它会记录删除哪个数据文件里哪一行的数据;另一种是equality delete file,主要记录已删除行的某些列的值,实际应用不多。Impala目前只支持读包含position delete file的Iceberg V2表。
Impala读Iceberg V2的实现当时有多种方案可选,比如Iceberg自己就提供了java library,可以用Iceberg的Java reader来读,但这会引入数据转换和C++调Java的JNI开销。还有一种方案是在Impala里实现Iceberg Scanner,类似于用C++重新实现Iceberg的Java reader。这种方式的开发成本会比较高。另外一种方案就是使用AntiJoin来实现,AntiJoin是一种join的模式,它会丢弃匹配得上的数据,这本身就是delete的语义。使用AntiJoin还能复用已有的broadcast、partitioned join的实现,跟Impala对Hive ACID表的支持方案类似,许多代码可以直接复用。它在工程实践上是难度最小、最方便的。如下图所示,AntiJoin的Build side是读delete file,构建哈希表。Probe side是读data file,Impala会增加文件名和行号这两个虚拟列,用它们来匹配delete file里记录的文件名和行号。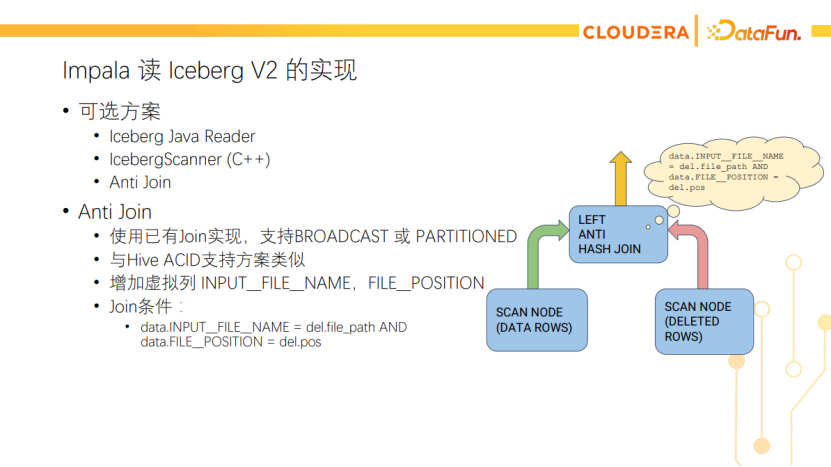
这里有个小优化,就是区分data files的情况来决定是否要AntiJoin。有些数据文件本身没有对应的delete files,可以直接读取。如下图所示,对于这类没有delete的data files,我们直接Scan。对于有delete的data files,还是用AntiJoin来做delete。最后用Union all来连接两边的结果。这样一方面降低了数据的延迟(没有delete的data files不需要等AntiJoin的Build side构建完就能生成数据了),另一方面也降低了AntiJoin的计算量。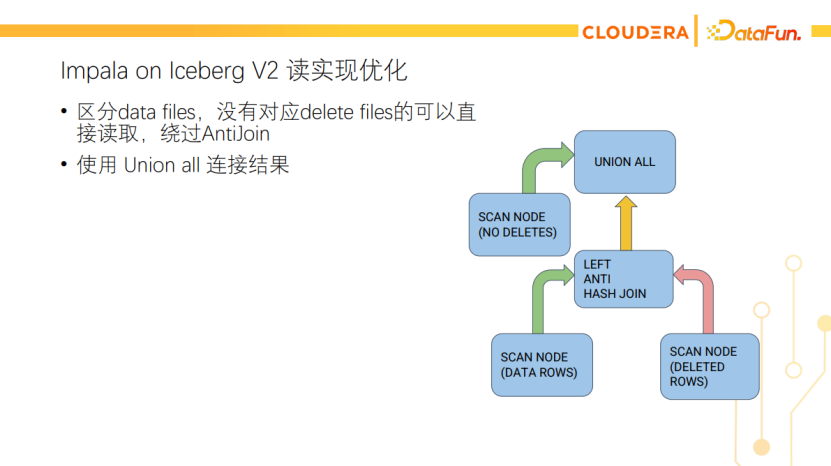
还有一个正在进行中的优化,就是将AntiJoin替换为Iceberg特定的operator,使用特定的lookup table,记录每个文件要删的行号集(有序)。这样每个RowBatch仅需一次lookup,因为ScanNode返回的RowBatch里的数据都属于同个文件,而且天然是按行号排序的。因此使用一次lookup就能知道是否有数据需要删除,有的话再和行号匹配即可。我们希望在4.3版本完成这一优化,具体可以关注IMPALA- 11619。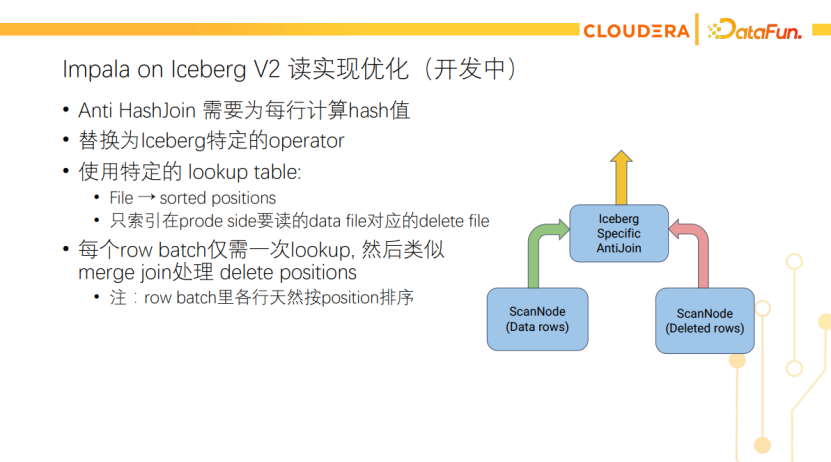
接下来介绍一个count(*)的优化。Count(*)是一个很常用的查询,Iceberg里snapshots的统计信息可以优化简单的count(*)。对于不带where条件也没有group by列的count(*)查询,我们可以把count(*)表达式替换为常量(即从统计信息得到的行数),如下图所示。但这种优化仅对v1和没有delete file的v2表有效。
对于有delete file的V2表,我们也能统计出delete file的总行数。是否能简单地用data file的总行数减去delete file的总行数,作为整个表的总行数呢?这种做法是不安全的。不同的delete file可能删除了同样的内容,比如并发修改产生的delete file就可能删除相同的内容。另外partial compaction也可能导致delete file指向的某些文件失效。所以不能用这种简单的算法。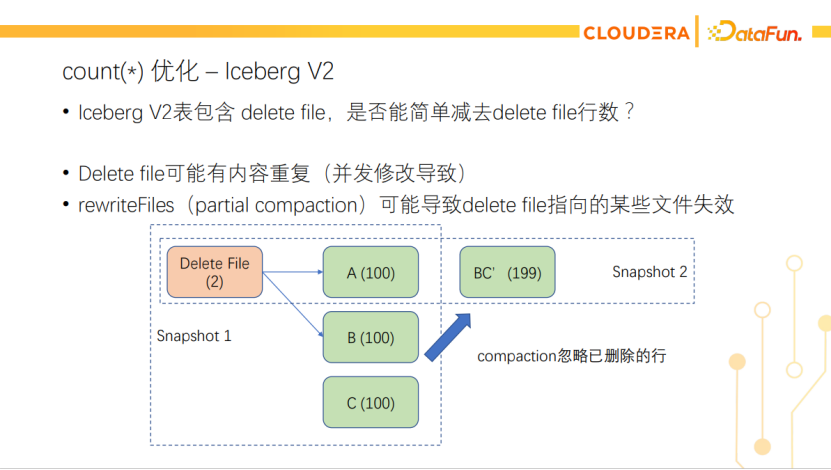
对于有delete file的Iceberg V2表,我们只能优化没有数据删除的data file上的count(*)。如下图所示,左图是未优化前的count(*)查询计划,右图把Union all转成一个加法表达式,把没有数据删除的data file上的count(*)换成了常量,另外有数据删除的data file还得通过AntiJoin读取,再求count(*)。这个优化的效果取决于有多少data file有数据要删除,如果大部分文件都没有对应的delete file,优化效果还是很明显的。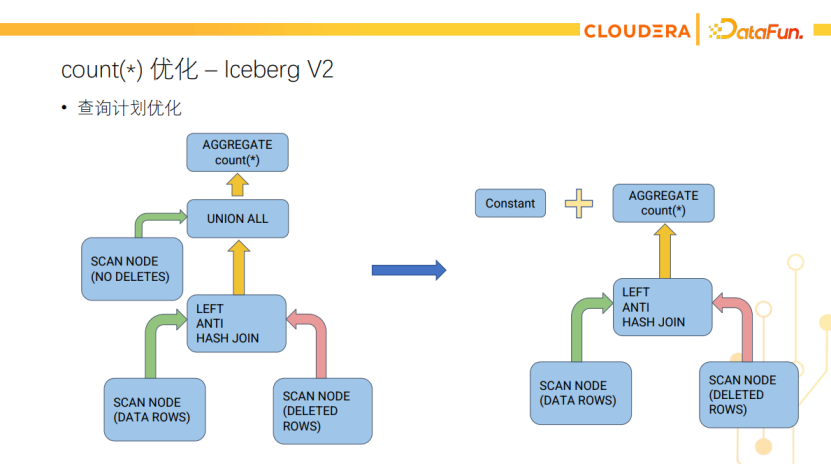
Manifest缓存优化
我们还做了一个与Manifest文件相关的优化,Iceberg提供了一个planFiles的API,这个API可以让查询引擎给定一些filter,然后Iceberg的API就会返回有哪些文件需要读。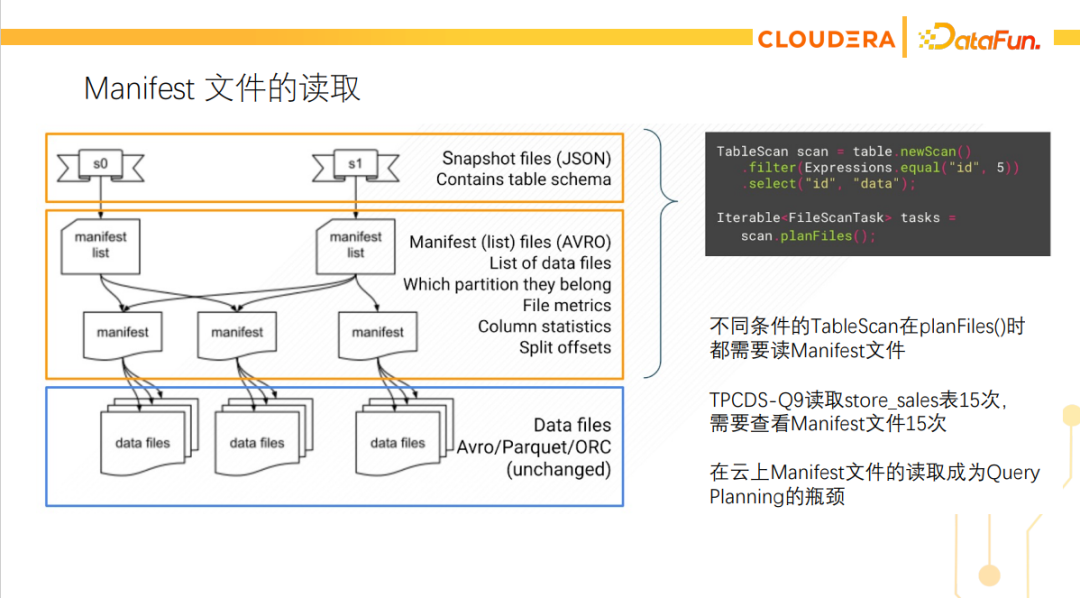
在做性能测试的时候发现query planning也有瓶颈,这个瓶颈就是在planFiles API里对manifest文件的读取。每次调用planFiles API都需要重新读取manifest文件。查询如果需要读一个表多次(使用不同的filter),则需要多次调用planFiles API,导致同一个表的manifest文件被多次读取。这在云存储上的性能问题会更严重。所以我们考虑做一个缓存的优化。这里有两种方案,一种是缓存无谓词的planFiles() 结果集,然后避免再调用这个API,对于同一个表不同filter的Scan,在Impala内部执行filter来得到要读的文件;另一种方案是在Iceberg library内部缓存manifest文件。
我们最终决定把这个缓存做在Iceberg Library内部,这样对上层引擎是透明的,而且所有引擎都能受益。另外Iceberg的Manifest文件不会被修改,只有新增和删除,因此也不用处理缓存失效的问题。如下图所示,我们使用一个两级缓存,从FileIO和文件路径映射到Manifest文件。这个功能已经贡献给了Iceberg社区,在Iceberg 1.1.0开始支持。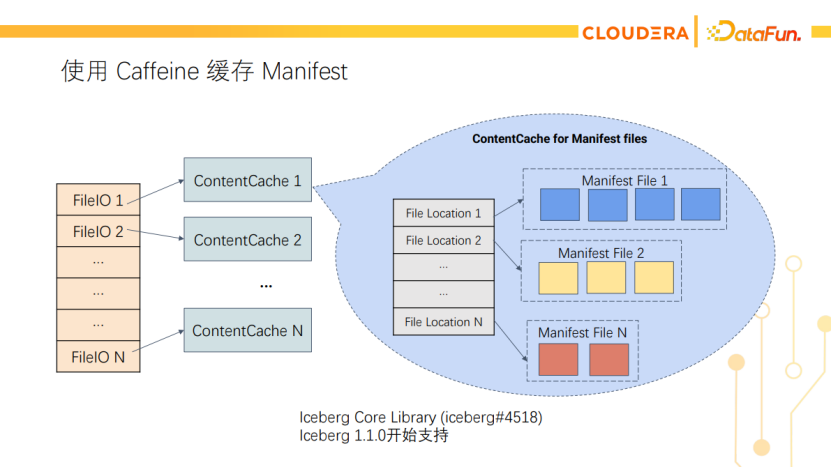
下图展示了TPC-DS 3TB测试的查询编译时间,黄线是原始的Iceberg实现,红线是加了manifest缓存的Iceberg实现,蓝线是查询Hive外表的时间。可以看到,性能优化效果还是比较明显的,优化后在Iceberg表上的planning时间与在Hive外表上的基本相同。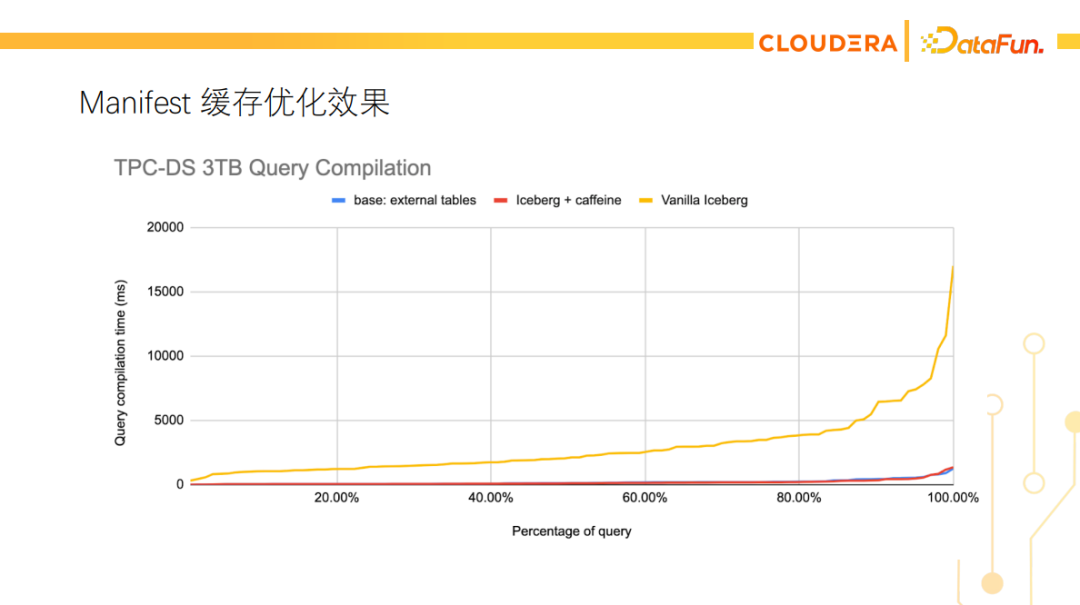
接下来介绍一下Codegen相关的优化。Codegen也是Impala的一个特色方向,主要是基于LLVM,目标是为每个查询编译出最优的执行程序。其工作原理是编译时先编译成IR代码(就是编译器的中间表示形式,相当于编译一半的状态),然后运行时根据查询给定的信息再完成编译。Impala在Codegen上的应用主要是优化Operator和表达式内部代码。
下面是Codegen的例子,左边是原始的数据库代码。其功能是物化一行数据,代码里有for循环,有各列偏移量的计算,还有switch语句根据不同列的类型调用不同的函数。在运行时查询已经给定的情况下,我们能知道总共要读哪些列,各列的偏移量就是常数了,另外也知道各列的类型,可以直接调需要的解析函数。因此codegen后代码可以像右边这样精简,而且没有了分支,执行效率会特别高。
这张图展示了有没有Codegen的对比,处理每行数据平均需要几个CPU cycle。左边是没有Codegen的原始代码的性能,右边是Codegen之后的,可以达到10倍性能的提升。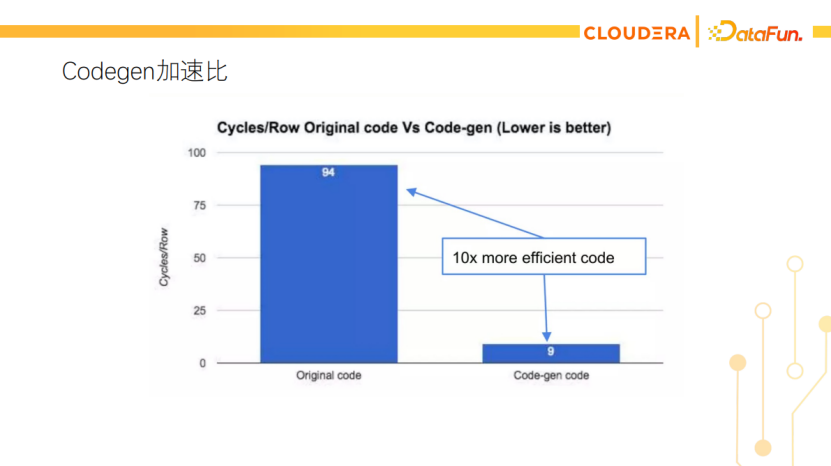
Codegen有一个天然的缺点是有延迟。另一条技术路线是向量化执行。向量化执行在小数据集上有天然的优势,它们生成执行计划后就可以直接执行了。Codegen的引擎在生成执行计划后还要做一个运行时的代码编译,所以存在延迟。学术圈里早有类似的对比,比如HyPer(查询编译数据库的代表)就在论文里说过,在小数据集上MonetDB(向量化执行数据库的代表)很容易跑赢Hyper。即使像TPC-H这样的benchmark,在scale factor为1时,Hyper的查询编译时间也高于查询执行的时间。Impala也有类似的问题,在TPC-H查询上的codegen时间可能达到900毫秒。因此建议大家在做Impala的性能测试时,要关注codegen的耗时,不要采用太小的数据集。如果发现query profile里显示的codegen时间占大头,建议调大数据集的规模,这样才能测试真正的执行耗时,更接近线上部署时的情况。
针对Codegen产生额外延迟的问题,我们也有工作在优化,其中一个工作就是异步Codegen。在查询执行时用异步的线程来做Codegen,查询先用解释型代码(即原始代码)来执行,等Codegen完成后,把对应的函数指针原子地替换为Codegen后的函数。这个优化对于小查询特别有用,它们可能在Codegen线程完成之前就执行完了,也就没有了等待Codegen带来的延迟。下面展示了TPC-H在scale factor为1时的性能测试。红色是原始的Codegen,黄色是关闭Codegen,正如前面所说,很多小查询关了Codegen跑得更快。蓝色是开启了异步Codegen的性能,很大程度上避免了Codegen带来的延迟。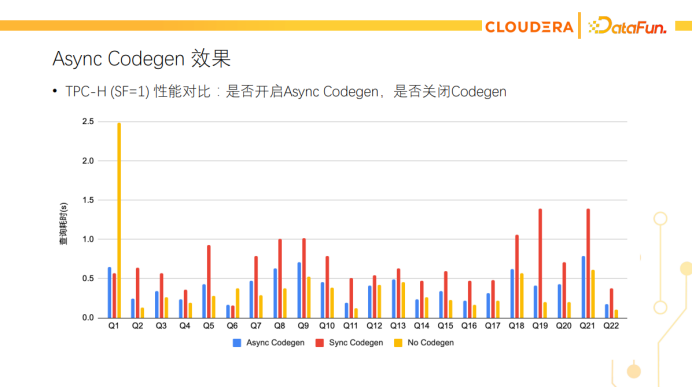
所以我们建议在生产集群上,对于数据集比较小,执行时间很短(如2秒内)的查询,可以开启异步的Codegen。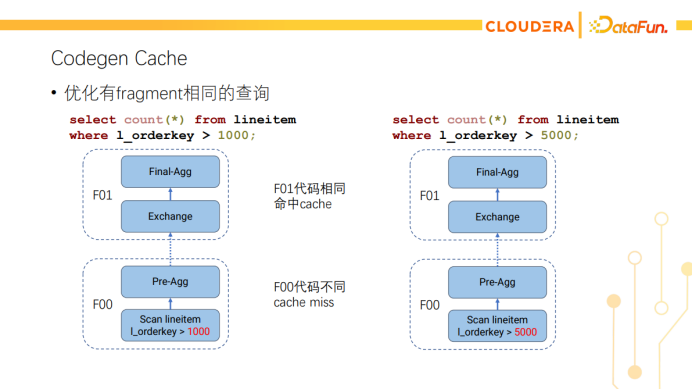
另一个解决Codegen延迟的优化是Codegen cache。Impala里的Codegen是以Fragment为单位进行的。每个Fragment codegen出来的代码会被缓存下来,后续的查询如果有相同的代码,可以直接复用codegen后的结果。如上图所示,两个count(*)查询只有filter不同,F01的fragment是完全相同的,可以命中codegen cache。如果是相同的查询重复跑,则所有fragment都能命中codegen cache。下面是Codegen cache的在小查询上的性能测试,红色是原始的实现 (即同步Codegen,以及没有Codegen cache)的性能,黄色是关闭Codegen的性能,蓝色是开启Codegen cache的性能。可以看到Codegen cache也能弥补小查询上Codegen带来的开销。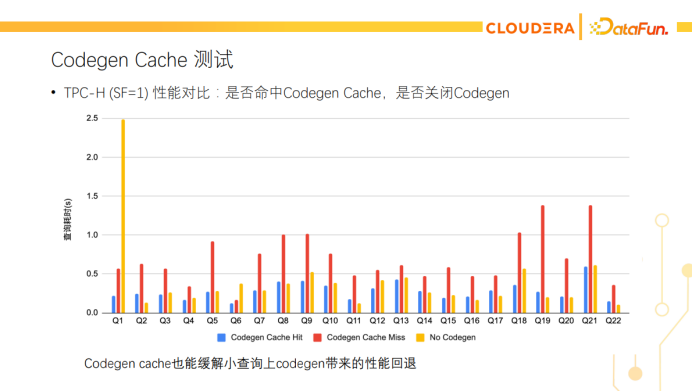

最后介绍一下Impala在Iceberg和Codegen这两个方向上的Roadmap。在Iceberg方面,还会继续优化v2表读性能,另外会支持v2表的delete和update操作,支持select查询Iceberg元数据等。在Codegen方面,会继续深耕,比如在更多地方使用Codegen,用自适应的方式去做Codegen(Adaptive Query Compilation)等。Q1:Impala社区有没有支持向量化的计划?
A:Impala更多的是走Codegen的方向,全面转成向量化执行的话,已有的很多Codegen优化就被丢弃了,会有不少性能回退。虽然向量化也能带来不少加速,但未必适用所有的场景。比如线上的查询经常带有复杂的表达式,有些谓词还会过滤大量数据,向量化执行可能产生代码膨胀,需要物化很多中间结果,以及向量稀疏后cache miss更严重的问题,转成向量化执行未必能全面优于原来的系统。另外在湖仓的场景里,数据并不是高度结构化的(比如没有全局字典),很多查询还是memory-bound,cache miss会比纯数仓场景更重,因此相比于优化CPU,可能优化内存甚至优化IO会更有效果。我们做过Impala和一个向量化执行引擎在湖仓场景的性能对比,发现Impala在不少查询上还是更优的,而且对方还有几个查询因为内存不足跑不出结果(Impala的内存使用优化地更成熟,不需要spill-to-disk就能跑出所有结果)。当然了,Impala在适合的地方也会使用向量化技术,比如在BloomFilter的计算中就使用了SIMD指令,在读Parquet的bit-unpacking中也使用了向量化的技术。我们会考虑在更多适合的地方使用向量化的技术,欢迎大家来参与!Q2:在查询多线程执行/mt_dop方向上后续有什么进一步优化计划吗?
A:社区有一些工作在调整并行度的设置,比如最近有一个工作是用ProcessingCost来调整各个Fragment的并行度,可以关注一下IMPALA-11604Q3:Impala查询iceberg表,相对于hive表来说,它们之间会存在一些明显地性能差异吗?
A:我们发现的一个性能差异是前面提到的planFiles API引起的,已经通过manifest缓存解决了。如果Iceberg表有delete file,会有额外的merge-on-read的开销。如果是只有data file的Iceberg表,跟查询Hive表的性能应该是一致的,因为底层的文件都是Parquet/ORC这类通用的格式。Q4:请问impala有支持读json表的计划吗?
A:有的,现在网易的同学正在贡献这个feature,现在正在review阶段,可以关注IMPALA-10798的进展。Q5:impala是否有计划支持物化视图?
A:Cloudera的产品是有支持物化视图的,使用的是Hive管理的物化视图,并通过HiveServer2来生成Impala的执行计划,再交给Impala执行。Impala社区目前还没有物化视图的工作,但留了External Frontend的接口,可以实现新的FE来支持物化视图。
黄权隆,Cloudera研发工程师,Apache Impala PMC 成员和 Committer,ORC Committer。毕业于北大计算机系,曾就职于Hulu大数据基础架构团队,参与大数据集群的维护、调优和二次开发。现就职于Cloudera,主要从事Impala系统的开发。








