




导读 本文将介绍腾讯自研的大数据计算平台——天穹SuperSQL,以及在应对数据湖场景中的复杂多维分析方面的实践。
全文目录:
1.SuperSQL架构
2.自适应计算引擎
3.实时湖仓融合
4.未来展望
01
Spark负责ETL、报表类的场景 presto负责交互式查询的分析场景 Hermes是腾讯自研的用于日志检索、用户画像场景的组件 StarRocks负责数据查询的场景 PowerFL负责数据安全场景
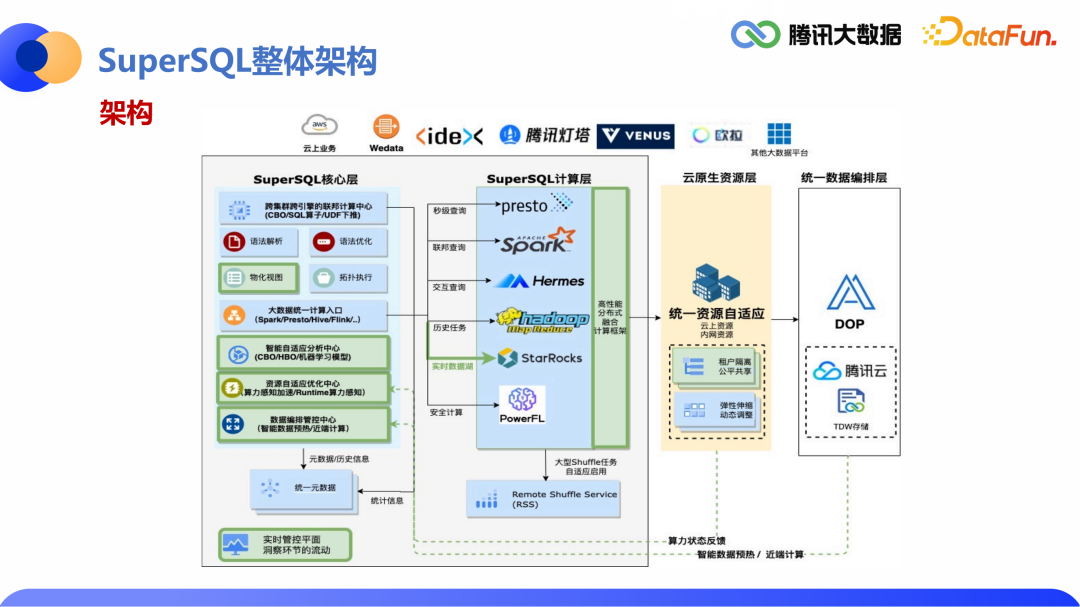
2.SuperSQL的目标
依托腾讯大数据生态,持续完善自适应能力,从而打造完整的大数据极速查询解决方案 实现三网合一的云原生化,解决大型复杂查询的等待痛点 持续探索技术先进性,构建高性能的融合分布式计算框架,实现引擎层的闭环统一管理
跨源:支持访问不同类型/版本的数据源 跨引擎:支持外接多类分布式计算引擎 跨DC:支持跨集群/地域的SQL编排
快速构建:不重复“造轮子“,复用开源计算引擎 轻量级解耦:不强依赖特定引擎,少做侵入性修改 场景自适应:根据SQL特征,智能挑选主流执行引擎
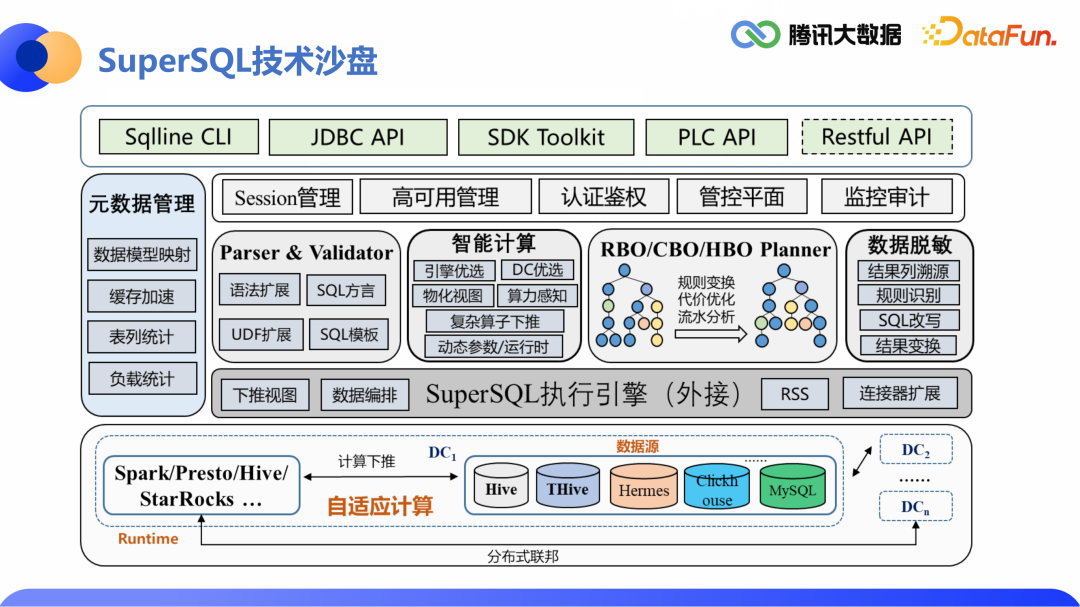
3.SuperSQL技术沙盘
自适应计算引擎
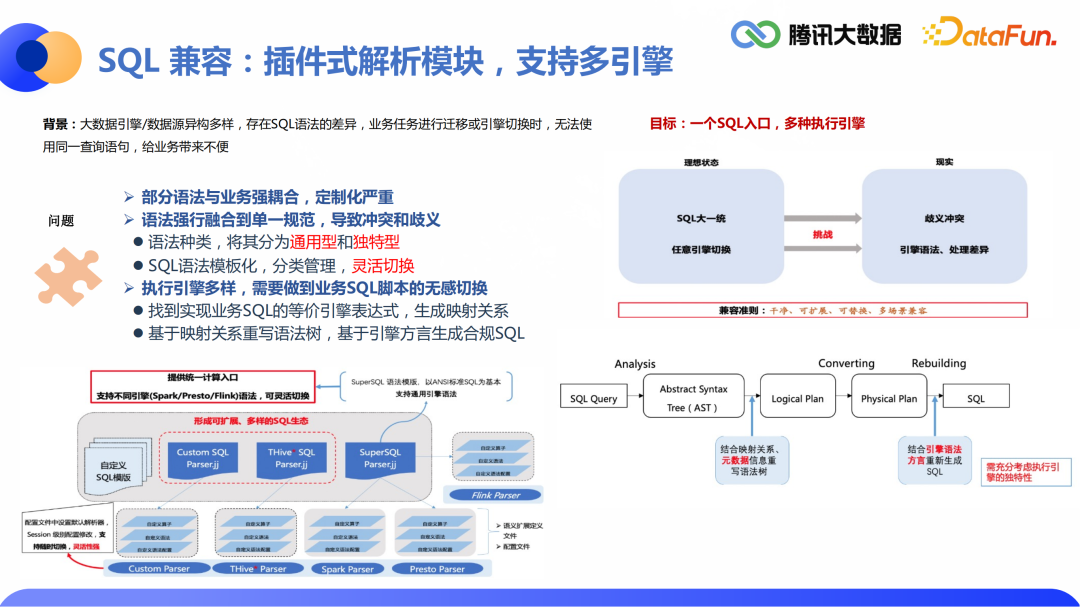
1.SQL兼容:插件式解析模块,支持多引擎
目标:SQL语法能够在常用的计算引擎之间进行无感切换 难点:不同SQL语法差异比较大
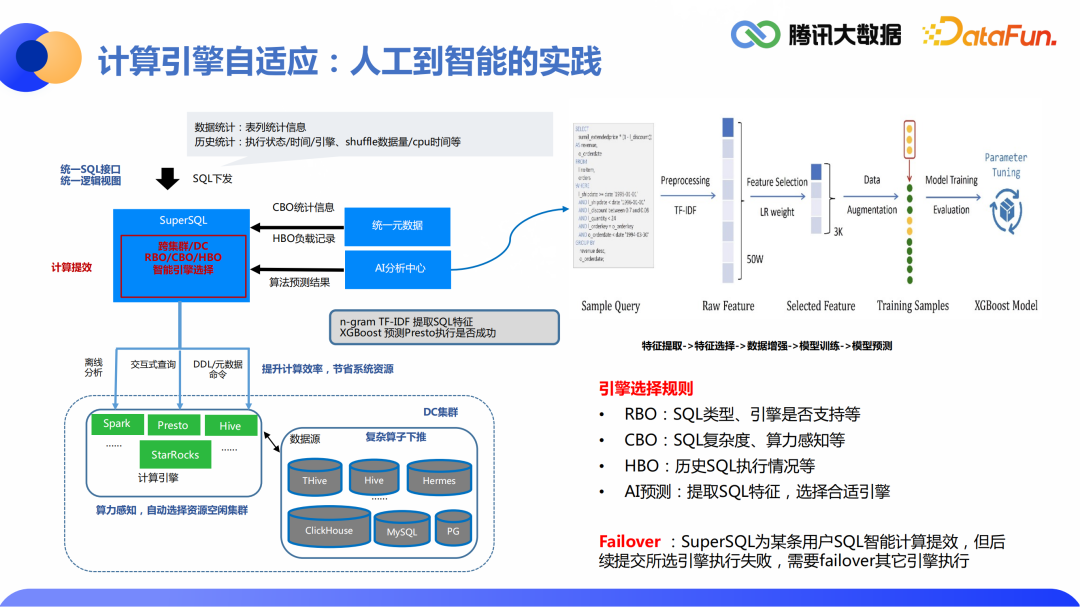
2.计算引擎自适应:人工到智能的实践
RBO:根据SQL类型以及引擎是否支持等维度判断当前SQL适合哪个引擎; CBO:基于SQL复杂度以及用户底层计算资源的感知判断适合提交至哪个引擎; HBO:基于历史SQL的执行情况进一步进行判断; AI预测:提取SQL特征,选择合适引擎。
实时湖仓融合
1.湖仓一体架构
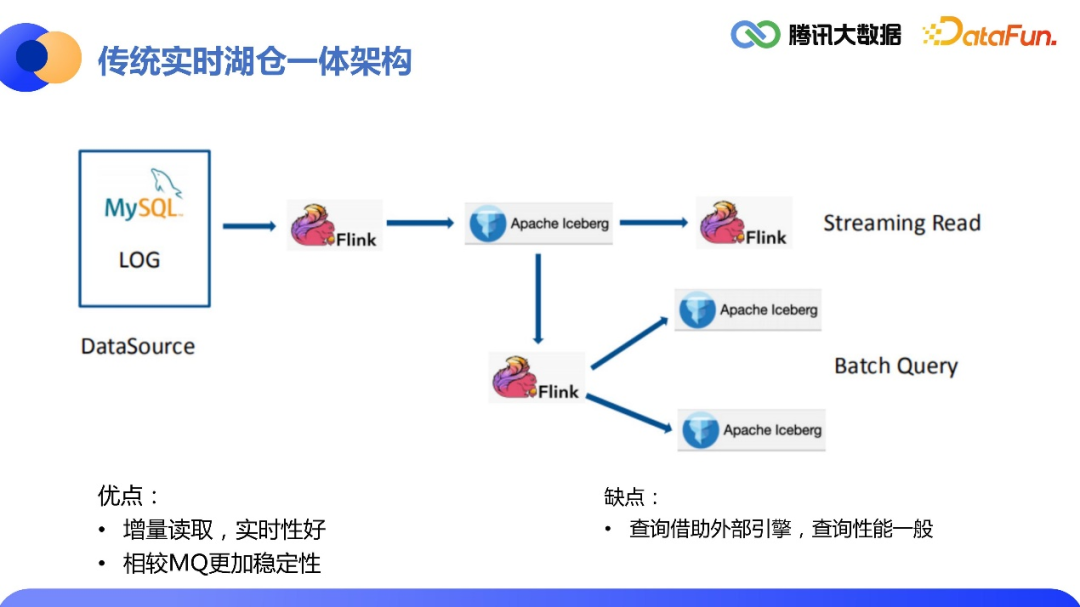

2.数据入仓
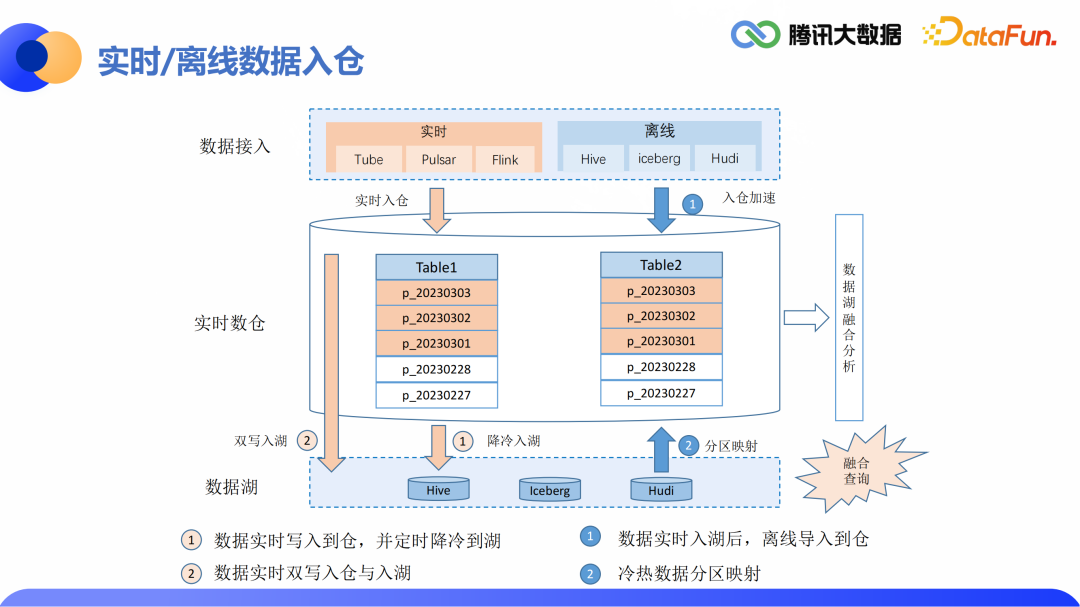

(3)实时数据入仓及降冷
3.自适应融合查询
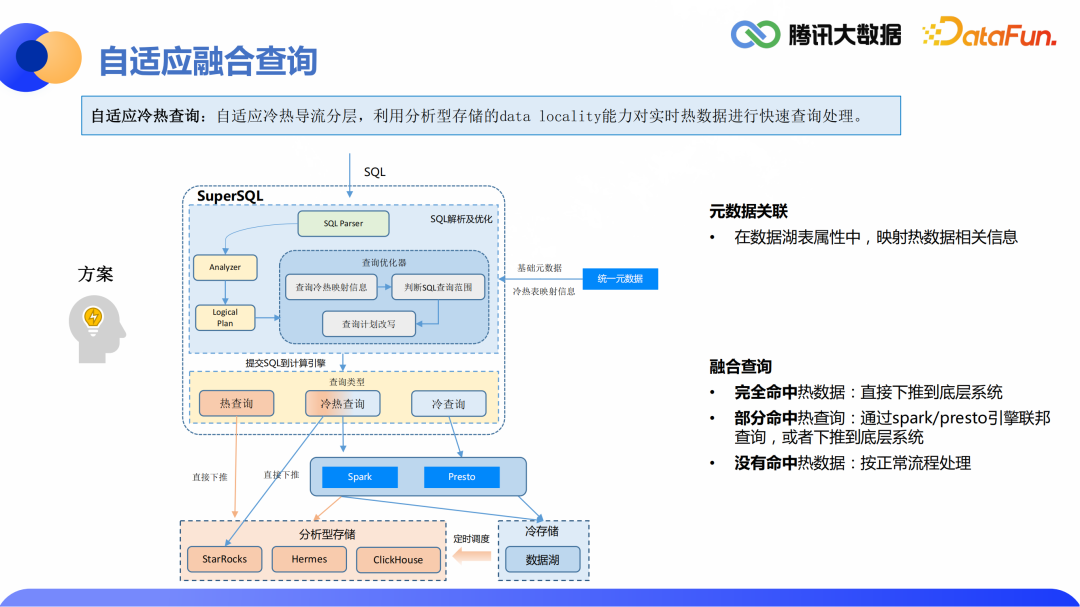
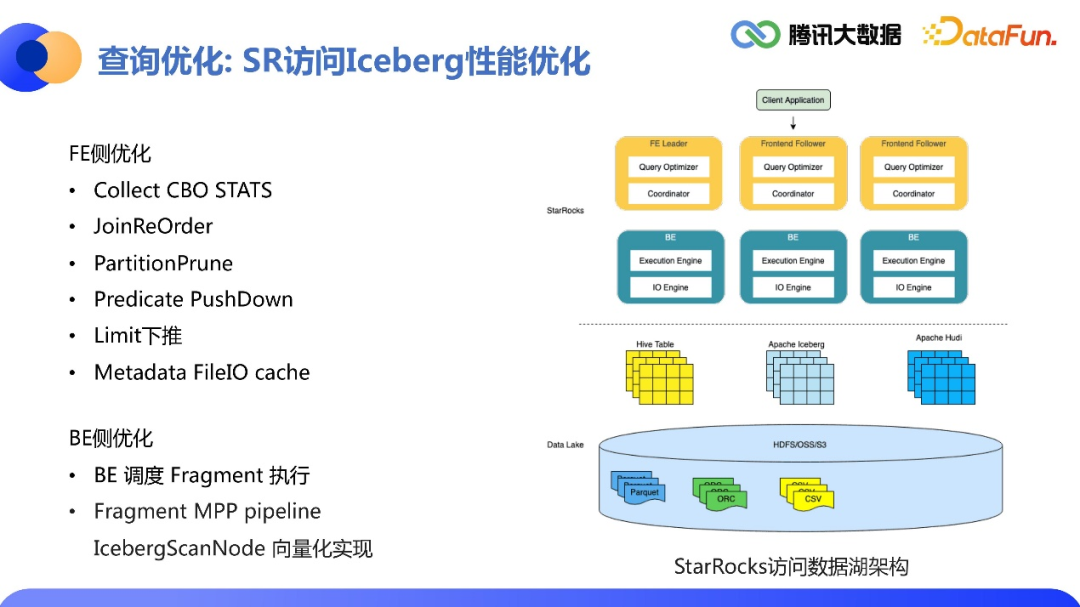
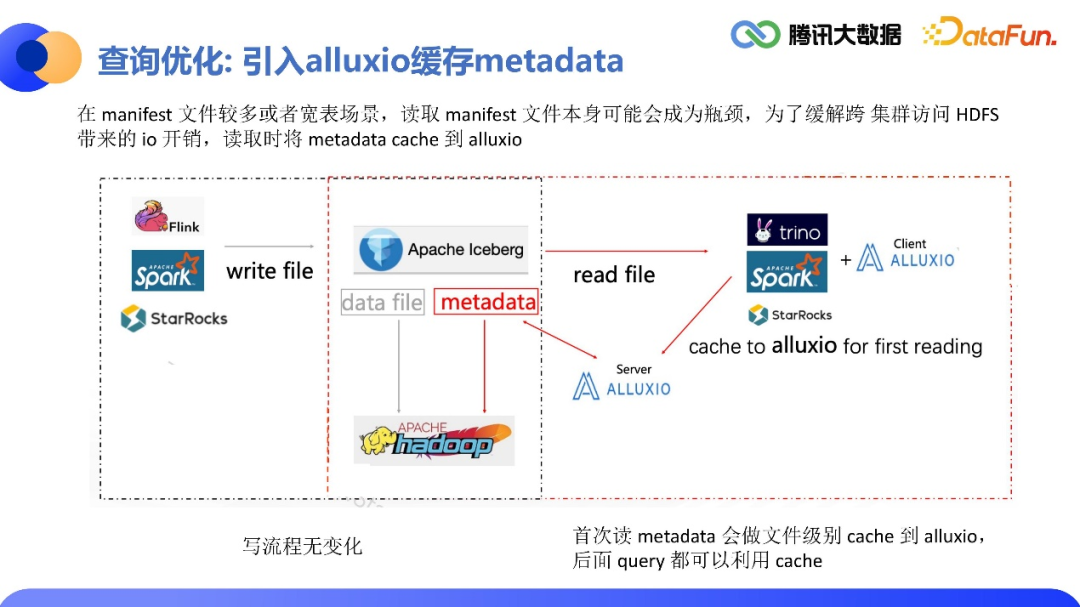

未来展望
首先,后续会继续完善SuperSQL的自适应能力,向更智能的方向迈进; 其次,会完善湖仓融合平台能力来支持更多数据湖仓能力,尽可能达到原生Iceberg的性能和能力; 另外,会优化计算平台查询数据湖的性能; 最后,会继续优化数据湖格式,比如增加更多索引等。


分享嘉宾
INTRODUCTION

程广旭
腾讯
高级工程师
腾讯大数据OLAP平台技术负责人,Apache HBase/InLong PMC 成员,有10年大数据相关工作经验,专注在KV存储及OLAP领域。
文章转载自畅谈Fintech,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
