




本文对谷歌公司发布的2024 SIGMOD论文《BigLake:BigQuery's Evolution toward a Multi-Cloud Lakehouse》进行解读,全文共5654字,预计阅读需要25至35分钟。
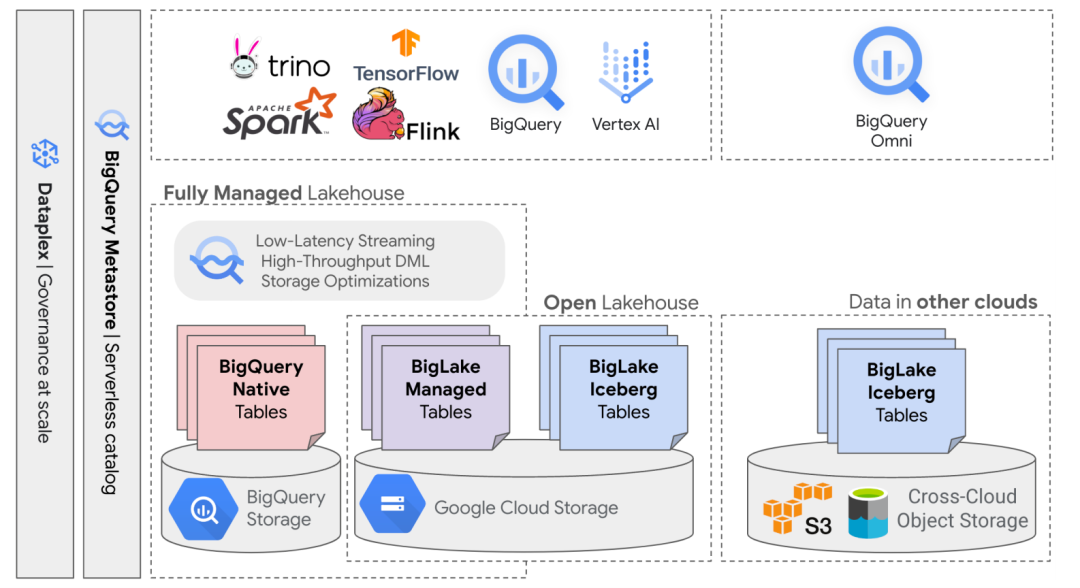
本文介绍了BigLake,BigQuery向多云湖仓演进的成果,以新颖的方式满足这些客户需求。BigQuery的云原生解耦架构使谷歌云能够不断演进系统,以满足分析和AI/ML工作负载领域的多种客户需求。客户对BigQuery的一个关键需求集中在数据湖和企业数据仓库工作负载的统一上。
BigLake湖仓框架
1.1研究背景
2010年,谷歌云推出了BigQuery,这是市场上第一个完全托管的无服务器多租户云数据仓库。BigQuery的架构将计算、存储和混洗分离,使每个系统组件能够相对独立地演进。自成立以来,这种架构使BigQuery能够在多个维度上演进,以大规模解决核心客户问题,包括嵌入式ML(BQML)和高吞吐量流摄入等行业首创功能,这也使BigQuery成为谷歌云平台(GCP)上增长最快的服务之一。
1.2研究介绍
1.2.1概述
大规模分析生态系统融合到 “湖仓” 架构范式,该范式将传统数据仓库(通常是针对结构化关系数据的OLAP/BI仪表盘和业务报告)与数据湖相结合,带来了新的工作负载类型,如针对非结构化数据的AI/ML与大规模分析的结合,以及基于Apache Iceberg 等开源格式表的企业级工作负载。
1.2.2创新性
(1)企业数据仓库提供的核心数据管理需求,如安全性、治理、通用运行时元数据、性能加速、ACID事务;
(2)有效利用开源格式分析生态系统的灵活性。云客户默认选择多云架构,支持BigQuery作为多云产品的需求。
1.2.3研究主要对象
主要问题在于如何演进BigQuery以解决现代湖仓现存的问题。BigQuery Omni 在谷歌云和非GCP云上支持通用湖仓平台,并提供多种通用数据管理自然语言,弥合数据仓库与开放数据湖和分析引擎之间的差距。
1.3研究目标
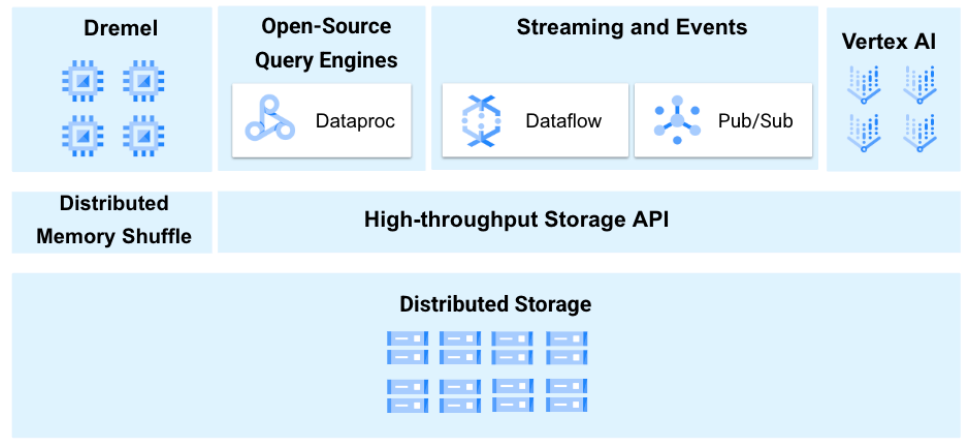
一般来说,现代云分析架构将计算与存储分离等关键功能分开。BigQuery的解耦架构具有一定创新性。查询处理引擎Dremel能够在本地处理数据,托管存储层,保持计算和存储分离,同时提供读写API,允许第三方分析引擎直接写入。
2.1BigQuery概述
BigQuery是一个完全托管的无服务器数据仓库,支持对PB级数据进行可扩展分析。BigQuery架构基于存储与计算分离原则。使用一个可靠的分布式存储系统保存数据,利用弹性分布式计算节点处理数据。
高水平BigQuery框架
2.1.1解耦架构
解耦架构提供了相对独立的组件保证灵活性,该架构演进的灵活性允许在谷歌云实现存储、分析和AI/ML等其他操作,形成现代数据和AI平台结合。
2.1.2实现AI任务
在分析方面,BigQuery湖仓允许在Dataproc中托管Spark,Presto等开源引擎集成,这些引擎可以直接读写BigQuery存储。同样,与GCP的AI/ML平台Vertex AI 的紧密集成,使我们能够利用自然语言来执行AI任务,如对BigQuery管理的多模态数据进行推理。
2.2 Dremel和In-Situ分析
2.2.1 Dremel
Dremel是BigQuery的大规模可扩展并行查询处理引擎。2006年Dremel最初发布时,存储与计算紧密耦合,但最终将计算和存储分开,以支持原地数据分析。为了支持完整的企业数据仓库功能,BigQuery构建了对托管存储的支持。
2.2.2 In-situ分析能力
随着BigQuery的发布,Dremel的分析能力通过外部表扩展到查询谷歌云存储(GCS)上的Parquet、Avro和ORC等开源存储格式。在这种模式下,BigQuery云对象存储上的文件仅支持只读访问,不支持基本查询优化、数据修改,也不支持安全和治理等核心企业功能
2.3存储API
BigQuery的存储和计算组件尽管它们在技术上不同且架构上分离,但是在用户角度来看是封闭的。数据必须先加载到BigQuery托管存储中才能进行查询,然后导出到GCS才能通过其他分析引擎访问。
2.3.1读取API
BigQuery提供了一种高性能、可扩展的方式读取API,用于访问BigQuery托管存储和BigLake表。读取API是基于gRPC的协议,通过高效的二进制序列化格式,使其具有可扩展性功能。
2.3.2读取API两种方法
读取API有两个主要方法:
CreateReadSession:允许用户指定将要执行的表,对于给定的读取会话提供一致的时间点,允许对所需数据以及用户进行各种修改。
ReadRows:使用 CreateReadSession 提供的流调用对象,其中每个流包含一部分数据。可用多个客户端同步进行数据读取。
2.3.3写入API
写入API提供了一种可扩展、高速和高容量的流数据摄入机制到BigQuery,支持多流的交付语义、跨流处理事务等。提供高效的gRPC有线协议。与读取API类似,用户创建一个会话,然后使用单个或多个写入流向目标表追加行。不同的写入模式可提供所需的处理语义(实时流或批量提交)和提交保证。
3.1委托访问模型
访问外部存储的查询引擎会将查询用户的凭据转发到对象存储,对象存储后再执行数据访问授权检查。这种模型对BigLake表不起作用,原因有两个:
凭据转发意味着用户可以直接访问原始数据文件,这将允许用户绕过细粒度访问控制,如数据掩码或行级安全;
BigLake表需要在查询上下文之外访问存储以执行维护操作。
BigLake表依赖委托访问模型,用户将连接对象与每个表关联。连接对象包含只读访问权限的账户凭据。
3.2细粒度安全
BigLake表提供统一的细粒度(行和列级)访问控制,独立于存储(数据湖或数据仓库)或分析引擎(BigQuery或Spark等开源查询引擎)。
3.2.1开源分析问题
开源分析的现状是将执行细粒度访问控制的责任交给查询引擎。这导致两个缺点:
数据掩码和行级过滤等安全策略与SQL绑定,需要在多个查询引擎之间复制策略;
委托查询引擎执行模型在工作进程中,直接运行的效果一般。
3.2.2BigLake安全保障
BigLake表提供更强的安全模型,其中读取API建立安全信任边界,并在数据返回给查询引擎之前应用相同的细粒度访问控制集,这对查询引擎本身不提供任何信任。因此,BigLake表能够提供统一的安全模型,扩展到外部查询引擎,而无需外部查询引擎。
3.3性能加速
不支持现代托管表格式(如Apache Iceberg、Apache Hudi、Delta Lake)的开源表采用有限的物理元数据。通常,元数据中仅存储表或分区的文件系统前缀。查询引擎需要将对象存储执行列表操作以获取要操作的数据文件列表。
3.3.1加速查询性能
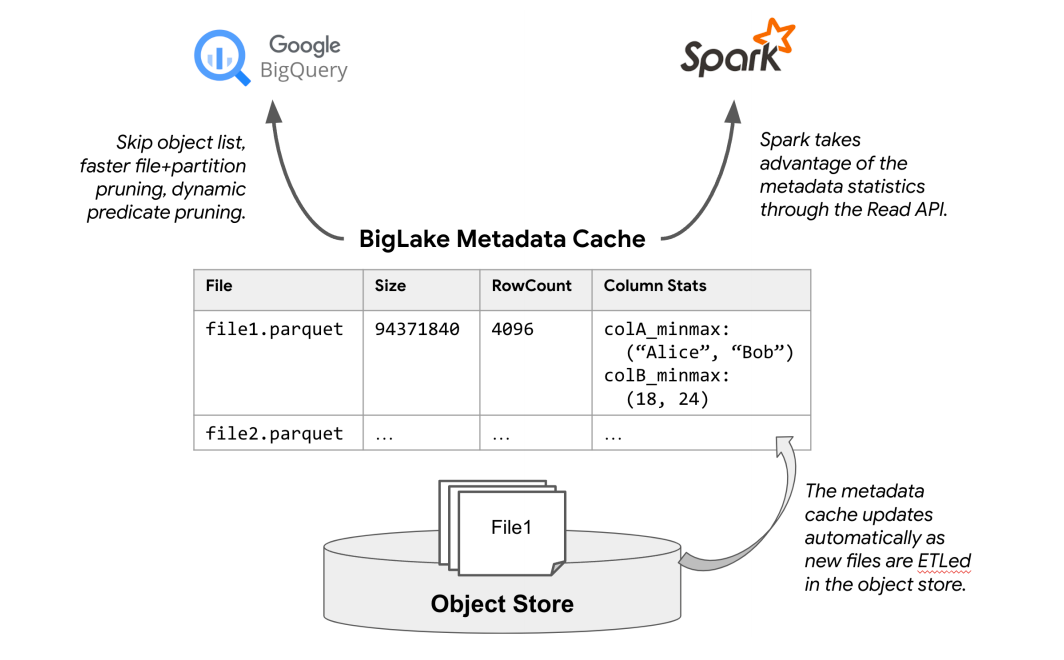
BigLake表支持元数据缓存等功能。BigLake自动收集并维护对象存储中的物理元数据。BigLake表使用与BigQuery原生表相同的可扩展物理元数据管理系统,称为Big Metadata。Big Metadata 使用与管理数据相同的分布式查询处理和数据管理技术来处理元数据。
BigLake自动收集,维护对象存储中文件的过程
3.3.2高性能分区
使用Big Metadata,BigLake表在列缓存中缓存文件名、分区信息和数据文件的物理元数据,如物理大小、行数和每文件列级统计信息。该缓存比Hive Metastore 等系统具有更细的粒度跟踪元数据,使BigQuery和存储API能够避免从对象存储中列出文件,从而实现高性能的分区和文件修剪。
3.3.2BigLake安全保障
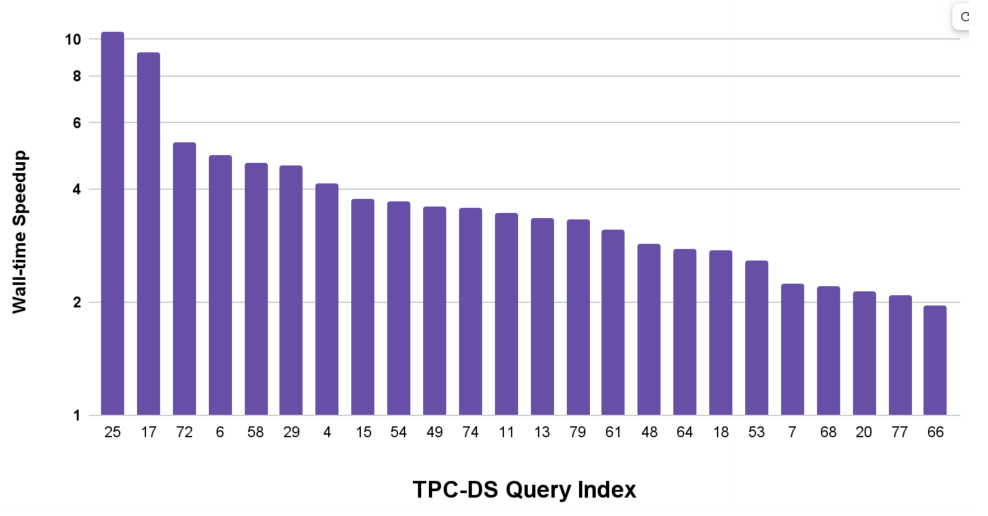
物理元数据管理层收集的统计信息使BigQuery和Apache Spark 查询引擎可以构建优化的高性能查询计划。为了衡量性能提升,在具有2000个槽的BigQuery预留上对TPC-DS 10T 基准进行了功率运行,按顺序执行每个查询。
TPC-DS查询加速
通过BigLake元数据层收集的统计信息有效改善BigQuery查询执行时间,执行时间因元数据缓存减少了接近四倍。
3.4存储API加速Spark
Spark执行器并行读取流。读取API以Apache Arrow 列格式返回行,Spark对Apache Arrow 的原生支持最小化了内存复制。在TPC-H基准测试中,针对BigLake表的Spark性能现在达到或超过Spark直接读取GCS的基准。该领域的未来工作将包括:
ReadRows 有效载荷的效率。客户端通常在 ReadRows 有效载荷的 TLS 解密上花费大量 CPU 周期。
读取重要的会话。动态分区修剪可以在运行时生成新的谓词,这导致重新创建读取 API 会话。。
DataSourceV2 支持下推部分聚合,如 MIN/MAX/SUM。读取 API 可以扩展为使用 Superluminal 计算部分聚合,向 Spark 返回更小的有效载荷。
3.5BigLake托管表
3.5.1 BLMTs
BigLake托管表(BLMTs)提供BigQuery托管表的完全托管体验,同时使用开放文件格式将数据放到在云存储中。
数据主要以Parquet格式存储,元数据使用Big Metadata 存储和管理。用户可以将Iceberg快照的元数据导出到云存储,允许任何能够理解Iceberg的引擎直接查询数据。Iceberg快照目前使用SQL语句触发。
3.5.2 Big Metadata与Iceberg区别
LMT在几个方面与Iceberg和Delta Lake 等开放表格式不同:
BLMTs 不受将元数据提交的需求限制:对象存储每秒只能更新 / 替换几个对象,因此对纯对象存储表来说,每秒可执行的数量被设置了限制。
开放表格式将事务日志与数据一起存储,恶意写入者可能篡改事务日志并重写表历史。
3.5.3 Big Metadata优势
写入吞吐量。Big Metadata 有状态服务支持,该服务在内存中缓存事务日志的尾部。Big Metadata 定期将事务日志转换为列基线以提高读取效率。在查询期间,Dremel 读取列基线与尾部协调。内存状态和列基线的结合加速读取。
多表事务。Big Metadata 使 BLMT 能够支持开放表格式。
强大的安全模型。由于写入者不能直接修改事务日志,表元数据是防篡改的,具有可靠的审计历史。
4.1对象表
对象表是系统维护的表,其中每一行代表一个对象,列包含对象属性,如URI、对象大小、MIME类型、创建时间。对于普通结构化表,元数据缓存用于列出和修剪数据文件。
4.2推理与AI/ML集成
为了处理非结构化数据,BigQuery ML 支持查询引擎内的推理并依赖外部计算的引擎外推理。因此,引擎内推理作业受益于Dremel快速透明地自动扩展以应对突发工作负载的能力。缺点是最大模型大小受Dremel工作内存限制;无法加载大于2GB的模型。然而,外部AI服务在自动扩展敏捷性方面往往更有限,并且来回传输数据存在额外的通信成本。
4.2.1引擎内推理
BigQuery ML 能够直接在Dremel工作器中加载和运行TensorFlow、TensorFlow Lite 和ONNX模型。内存是一个挑战。非结构化数据的 “单元” 往往比典型的关系行更大,因此消耗更多内存。更复杂的是,模型执行和复杂非结构化数据格式(如JPEG)的解析都必须要保证整体数据库的安全。

Dremel分布式推理
4.2.2外部推理
BigQuery支持两种形式的外部推理:
(1)使用托管在Vertex AI(谷歌云模型服务平台)上的客户自有模型;
(2)使用谷歌的第一方模型进行推理。第一方模型通过专用服务和API访问。
在Dremel中,使用客户自有模型的外部推理依赖于远程执行UDF的基础设施。Dremel从对象存储中读取非结构化数据文件,将其预处理为匹配模型,触发对模型REST端点的推理。然后进行模型输出(预测)作为原始JSON blob 返回,从而实现SQL解析。
5.1OMNI概述
BigLake的进步提供了技术基础,使BigQuery Omni 成为可能:一种跨云数据分析的新颖方法。通过Omni,客户可以使用 “单一玻璃面板” 范式,原地分析驻留在 BigQuery托管存储、谷歌云存储(GCS)、Amazon S3 和Azure Blob Storage 中的数据。Omni通过将Dremel带到数据所在的位置,而不是要求客户在云中移动或复制数据到GCP以将数据带到Dremel,使BigQuery的计算引擎能够在所有主要云平台(AWS、Azure、GCP)上运行。

OMNI框架
5.2OMNI架构与部署
Omni使用混合跨云架构,通过Stubby连接的20多个微服务组成,Stubby是谷歌内部支持基于策略授权的RPC框架。每个微服务都有自己的授权规则集,可以定义其他服务并与其通信。Omni所有数据和元数据都存储在一个完整隔离区域内。
5.3VPN/网络
Omni的控制平面和数据平面在GCP和外部云之间分离,两个平面之间的安全通信至关重要。下图提供了我们如何确保这种安全通道的概述。Omni使用基于QUIC的零信任VPN。
VPN提供多层安全保障。它执行IP访问控制,丢弃不在允许列表范围内的任何数据包。它既是前向网络代理又是反向网络代理。策略引擎根据身份验证的用户信息接受或拒绝服务的入站/出站请求。
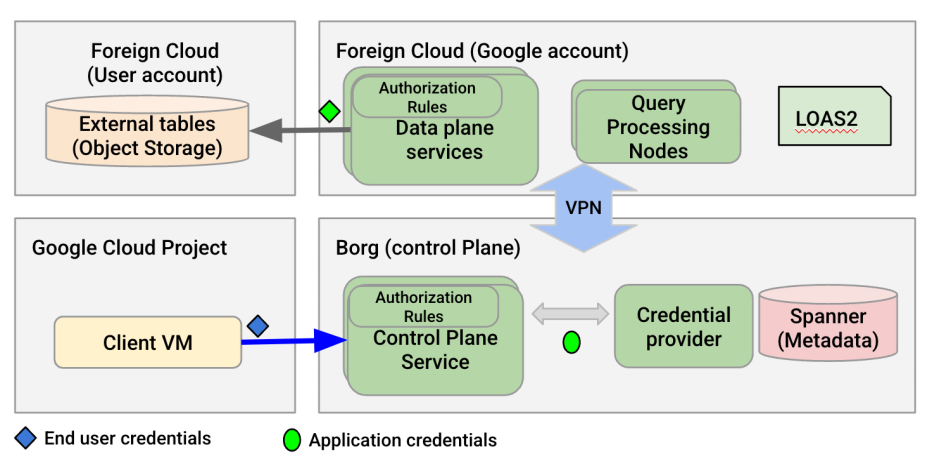
VPN/网络工作架构
5.4安全
Omni是一个多租户系统,旨在提供与单租户架构相同级别的安全优势。通常,单租户系统在安全性和隐私性方面提供更高级别的隔离。通过严格的安全实践,实现两者的最佳结合。采取的安全包括:对象访问凭证范围,不可信代理的基于LOAS的额外认证,安全领域相关人员认证,二进制授权。
5.5非GCP云上的Dremel
Dremel在谷歌内部的Borg基础设施上原生运行。将Dremel迁移到外部云的一个主要挑战是将足够的依赖项带到外部云,以确保完整的功能和性能保证。为了实现这一点,我们在AWS中构建了一个最小的类Borg环境,其中包括Dremel使用的关键服务。
5.6多云与跨云
5.6.1多云操作
多云操作涉及在谷歌的发布系统、监控、日志记录、崩溃分析、分布式跟踪、内部DNS和服务发现系统中构建集成或适配器。在构建多云系统时,实现云无关性没有固定的答案,设计应尽可能符合共享,同时明确区分云特定配置和功能。
5.6.2跨云分析
Omni通过跨云查询和跨云物化视图方法将相同的查询引擎与数据共置,并对原地的主数据副本进行操作,实现减少出口成本、提高性能和效率的优化。
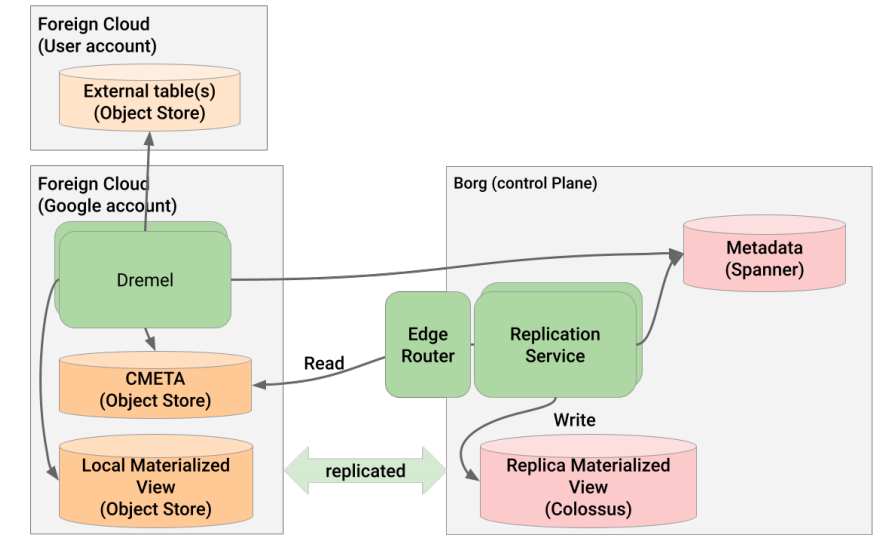
跨云物化视图
跨云物化视图(CCMV)通过维护复制状态,提供从Omni区域到GCP区域的数据增量复制。CCMV支持各种ETL和仪表板用例,以及将客户的外部云数据与基于GCP的服务(如Vertex AI)无缝集成。
BigQuery向多云湖仓的演进为数据管理开辟了新的可能性,使我们的客户能够处理以前具有挑战性或不可能的任务。以下概述了我们在生产中看到的几个值得注意且可重复的客户使用模式:
6.1单一数据副本的无缝分析
在BigQuery转变为多云湖仓之前,客户数据在数据湖和仓库之间保持隔离。这一突破使客户能够在云存储或BigQuery中存储单一数据副本,同时仍然使用BigQuery和Spark等开源引擎运行高性能和安全的分析。开源引擎可以使用BigQuery存储API访问BigLake表,利用细粒度访问控制和通过元数据缓存的查询加速。
6.2跨云查询和分析
在BigQuery演进为多云湖仓之前,执行跨云分析需要物理移动云间数据。BigQuery Omni 现在使客户能够使用跨云连接无缝查询跨云数据,跨云物化视图提供了增强的控制和灵活性,促进了高效的数据查询。
具有SQL简单性的机器学习多模态数据分析:BigQuery最初的数据格式支持仅限于结构化和半结构化数据。随着BigLake对象表的引入,客户现在可以在BigQuery中使用与结构化数据相同的治理框架分析非结构化数据。
6.3托管功能
客户可以导入视觉模型或调用Vertex AI 中远程托管的模型,来使用SQL的强大和简单性执行文档、语音和视觉分析。客户在各种应用中利用这些功能,突出示例包括:
元数据提取:利用机器学习模型从非结构化数据源中提取有价值的元数据,使其能够与结构化数据无缝集成以进行全面分析。
训练语料库定义:过滤敏感数据或实施采样技术,确保了敏感信息的保护,同时保持训练数据集的完整性。
细粒度安全执行:实施细粒度安全控制,以管理对云中存储的非结构化数据的访问和共享。这在促进授权协作的同时保护敏感信息。
BigLake对核心BigQuery存储和元数据基础设施部分功能进行演进,涉及多种技术和功能,具体可归纳为以下三点:
统一数据管理与安全治理:BigLake表采用委托访问模型,借助连接对象关联服务账户凭据访问对象存储,避免用户直接接触原始数据,保障数据安全。
性能加速创新:一方面,利用Big Metadata系统进行物理元数据缓存,减少对对象存储的文件列表操作,大幅提升查询性能。另一方面,开发向量化Parquet读取器,直接生成Superluminal列批数据,避免格式转换开销,将服务器端CPU效率提高一个数量级,提升数据传输效率 。
增强托管与互操作性:BigLake托管表(BLMTs)支持ACID事务,在客户对象存储上以Apache Iceberg格式提供完全托管功能,包括自动的存储优化操作,且元数据由Big Metadata管理,安全性高。这些创新最终为客户启用了新的工作负载,我们希望这将在大规模数据分析领域带来更多创新。
论文解读联系人:
刘思源
13691032906(微信同号)
liusiyuan@caict.ac.cn





