




导读
前两天遇到一个mysql坏块恢复场景, 简单记录一下.
恢复报错&分析
数据文件是5.7环境的, 现在ibd2sql不再需要转换到8.0环境即可解析. 于是我们使用如下命令解析:
python3 main.py xxxxxxxx.ibd --sql > /tmp/t20250422.sql
报错
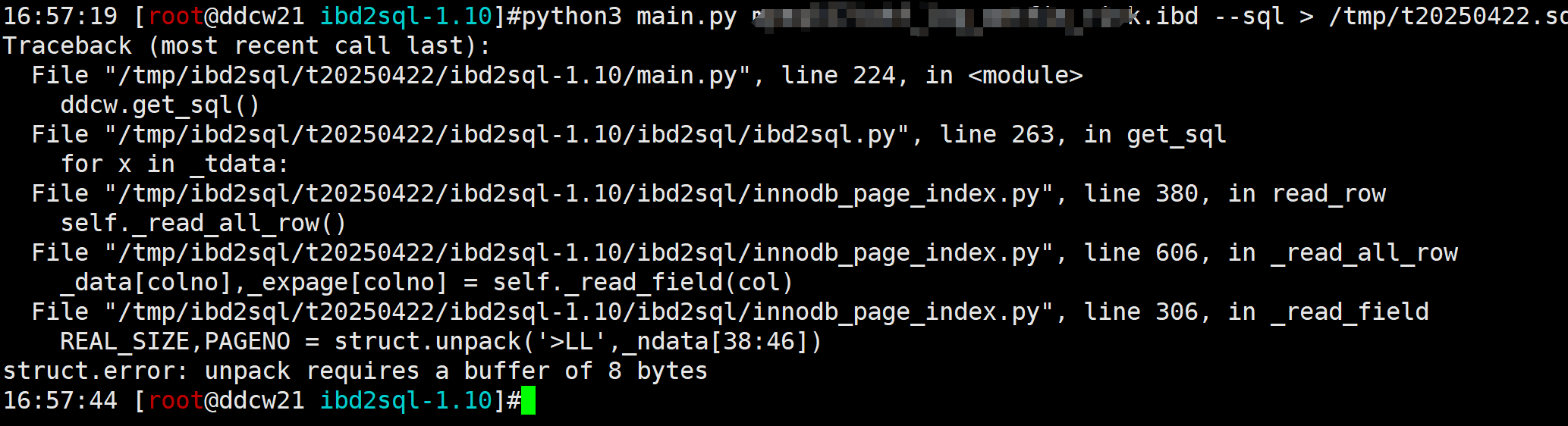
但是我们解析一部分数据之后报错了, 不是一开始就报错, 而是解析了一部分之后才报错的
分析
这个报错是解析溢出页的时候,无法获取到REAL_SIZE,PAGENO, 因为_ndata[38:46]并没有8字节, 也就是读取溢出页的时候就已经有问题了, 也就是说溢出页的PAGENO解析就已经出错了. 相关代码逻辑如下:
if size + self.offset > 16384:
SPACE_ID,PAGENO,BLOB_HEADER,REAL_SIZE = struct.unpack('>3LQ',self.read(20))
self.debug(f"VARCHAR: SPACE_ID:{SPACE_ID} PAGENO:{PAGENO} BLOB_HEADER:{BLOB_HEADER} REAL_SIZE:{REAL_SIZE}")
if self.table.mysqld_version_id > 50744:
_tdata = first_blob(self.f,PAGENO)
else:
_tdata = b''
while True:
self.f.seek(16384*PAGENO)
_ndata = self.f.read(16384)
REAL_SIZE,PAGENO = struct.unpack('>LL',_ndata[38:46])
_tdata += _ndata[46:46+REAL_SIZE]
if PAGENO == 4294967295:
break
注: first_blob只针对于8.0环境的溢出页, else部分才是5.7的溢出页结构, 之前有讲过具体结构, 有兴趣的可以往前翻翻
由于是解析到中途才报错的, 表结构信息有问题的概率很低, 那更可能的就是存在坏块. 我们可以使用之前的坏块校验脚本来验证下: (坏块校验之前也讲过, 有兴趣的可以再往前翻翻…)
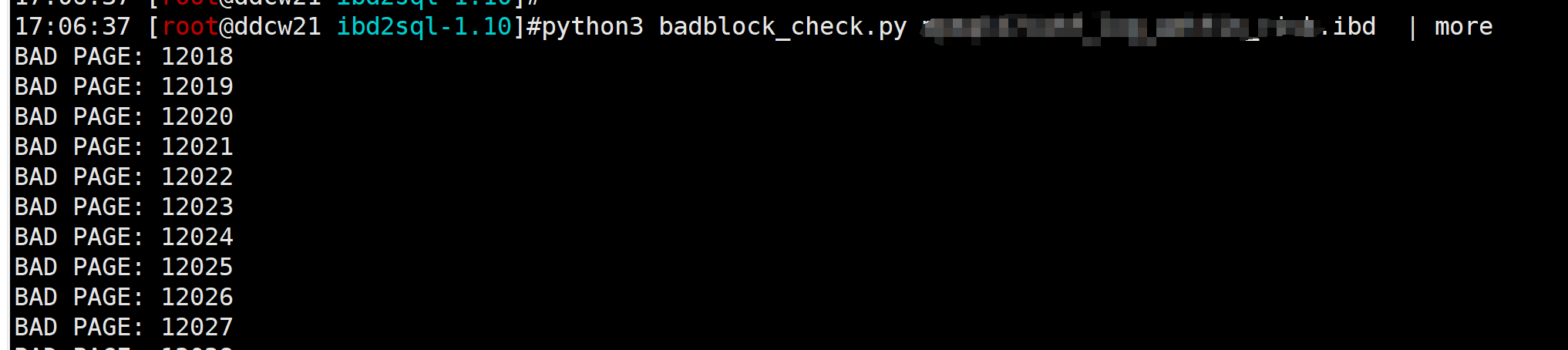
发现确实存在很多坏块…
当然也可以使用官方的innochecksum来验证

由于我们解析数据只需要访问主键, 但是还是报错了, 就说明坏块是坏在主键的(这太坏了)
解决方法
既然确定了问题是坏块, 那么解决方法就比较多了. 我们这里只讨论ibd2sql相关的方法.
方法1
1页1页强制解析, shell就能实现(ibd2sql支持指定起始页和页数量), 缺点就是得多次打开文件进行读取操作, 效率不行(以前某个案例的时候使用的方法, 当时数据量不大, 就提供的这种方法.)
方法2
鉴于方法1效率不行, 使用还贼麻烦, 我们可以稍微换下思路, 即读取数据文件的时候先判断是否满足如下条件:
- 是否为索引页
- 索引id是否为主键
- 索引页为叶子节点(pagelevel=0)
- crc32c校验通过(排除坏块)
满足之后我们再做解析. 怎么修改呢? 可以参考如下代码(已经提交到最新版本了,直接下载最新版即可)
rootpageno = int(self.table.index[self.table.cluster_index_id]['options']['root'])
self.PAGE_ID = rootpageno
indexpagedata = self.read()
B_PAGE_INDEX_ID = indexpagedata[38:38+56][28:28+8]
import os
from ibd2sql import CRC32C
total_pages = os.path.getsize(sys.argv[1])//16384
NEXT_PAGE_ID = 3
sql = self.SQL_PREFIX
while NEXT_PAGE_ID < total_pages:
self.PAGE_ID = NEXT_PAGE_ID
try:
indexdata = self.read() # 读取页的时候可能就是坏块了
except:
NEXT_PAGE_ID += 1
continue
NEXT_PAGE_ID += 1
if indexdata[24:26] == b'E\xbf' and indexdata[66:74] == B_PAGE_INDEX_ID and indexdata[64:66] == b'\x00\x00':
checksum_field1 = struct.unpack('>L',indexdata[:4])[0]
checksum_field2 = struct.unpack('>L',indexdata[-8:-4])[0]
c1 = CRC32C.crc32c(indexdata[4:26])
c2 = CRC32C.crc32c(indexdata[38:16384-8])
if checksum_field1 == checksum_field2 == (c1^c2)&(2**32-1): # 坏块就不解析了
aa = index(indexdata,table=self.table, idx=self.table.cluster_index_id, debug=self.debug,f=self.f)
aa.pageno = self.PAGE_ID
aa.DELETED = True if self.DELETE else False
_tdata = aa.read_row()
for x in _tdata:
_sql = f"{sql}{self._tosql(x['row'])};"
if self.LIMIT == 0:
return None
else:
print(_sql)
self.LIMIT -= 1
sys.exit(0)
大概逻辑是: 获取root page id, 读取root_page中的index_id(即为主键的index id), 从头开始读取数据文件PAGE(读取的时候会判断页类型(这种做法并不好),但是有坏块的话, 页数据类型可能就有问题,导致一些意料之外的错误,所以也得做异常处理), 然后判断是否满足要求, 满足要求则解析.
那么什么时候走到这个逻辑呢? 之前不是有个--force还没完整实现么, 你说巧不巧. 于是我们修改--force的功能为: 跳过坏块一页页解析主键索引上的数据.
然后我们再次测试验证下(加上--force):
python3 main.py xxxxxxx.ibd --sql --force > /tmp/t20250422.sql

到此,这张表恢复成功!
其它
可能有的小伙伴会问为啥不使用备份或者innodb_force_recovery之类的恢复, 当然是优先建议的啦,
但是 那些方法只能针对比较简单的损坏情况, 实际情况可能连数据文件名字都没得, 也可能是残缺的数据文件…
思考: 对于这张文件名已经被修改了的ibd和frm文件, 怎么使其对应上呢? (当然一个个的试也是可行的)
参考:
https://github.com/ddcw/ibd2sql
https://github.com/ddcw/ibd2sql/commit/1c71b023df65ccff7669ec52cb1f6ae323c5d453
