




在金融行业,有很多需要准实时完成的数据同步场景,比如上游的交易数据,需要第一时间进入到交易监控系统,用于反洗钱或可疑交易,客户的持仓或者账户盈亏,要第一时间计算后推送到客户端,这些都需要数据尽可能保证低延时并且还要保证数据的一致性,实际上对于工具的要求是比较高的。
过往我在生产使用过的工具,主要是Oracle Goldengate,作为一款Oracle原厂工具,在异构数据库之间的CDC和数据转换功能非常强大。然而商用授权的价格也是让人咋舌,所以寻找一款国产开源的CDC工具,能够支持多种源头以及多种目标端,成为了我今年工作的重要议程之一。
经过调研,最终找到了一款国产流式数据库;RisingWave。
RisingWave简介
首先,简单介绍一下RisingWave,目前(25年4月)墨天轮国产数据库榜单排名第26,而且处在上升趋势中,分类是关系型数据库。实际是基于PostgreSQL内核开发的流式数据库。
在调研、测试的过程中,我个人对RisingWave有这么几个特点:
1.使用门槛。基于PG内核开发,就意味着过往PG的使用经验可以带到RisingWave中,直接使用PG客户端作为交互方式,DDL和语法都可以直接迁移过来(部分数据类型可能需要调整),比重新掌握一个CDC工具要方便很多。
2.支持类型。能够支持相当丰富的主流数据库或者数据引擎,PostgreSQL无疑是适配最好的,除此之外MySQL、Doris、ES、Kafka、Iceberg都是可以支持的。异构数据库之间的数据CDC配置,无论作为源还是目标,都可以已较方便的方式支持(除了Oracle只能用Kafka)。
3.实时计算。RisingWave提供的物化视图,可以做到毫秒级别刷新的数据计算,上游数据库更新之后,最短几十毫秒内即可通过物化视图获得计算结果,无需考虑刷新频率和效率问题。
4.可选架构。无论是用于测试的all-in-one,还是用于生产的多节点分布式,可以满足不同场景不同配置不同目的的需求,并且根据具体的数据量来进行扩缩容,这是过往其他CDC工具可能没有给我的体验。
结合这四个我认为很吸引我特性,我也大致总结了如下两个情况,可以作为金融行业的典型场景:
1.流式 ETL:在数据输入时,在不同系统间连续持续提取、转换和移动数据。RisingWave支持从各种数据源摄取数据,如消息队列、日志文件或数据库的CDC流。
2.实时分析:在数据生成或接收时对其进行分析,而不是事后分析。RisingWave 通过从各种数据源实时摄取和转换数据来支持实时分析,始终保存新鲜的结果,可以直接从数据看板提供查询服务。
接下来,本文即以如下两个场景来做一个测试。
场景介绍
目前Oracle是大多数金融行业核心交易系统最常用的数据库。业务部门和客户那边反馈,需要2+1个场景,数据要求尽可能实时:
1.交易监控,将交易数据实时写入到监控交易系统的数据库,用于反洗钱、可疑交易、风控等其他场景。
2.实时计算,客户需要在手机app端,实时获取到自己的持仓、损益等数据。
3.除此之外,IT部门还有一个额外需求,就是将这些数据再写入Iceberg数据湖一份,作为备用副本以后用于其他用途。
实际上1和3都是ETL需求,只不过用于不同的下游,2是实时计算分析,实际数据源不仅仅是交易系统的Oracle,还有着其他的业务数据库,和前两个有着不一样的要求。
整个系统的架构图如下:
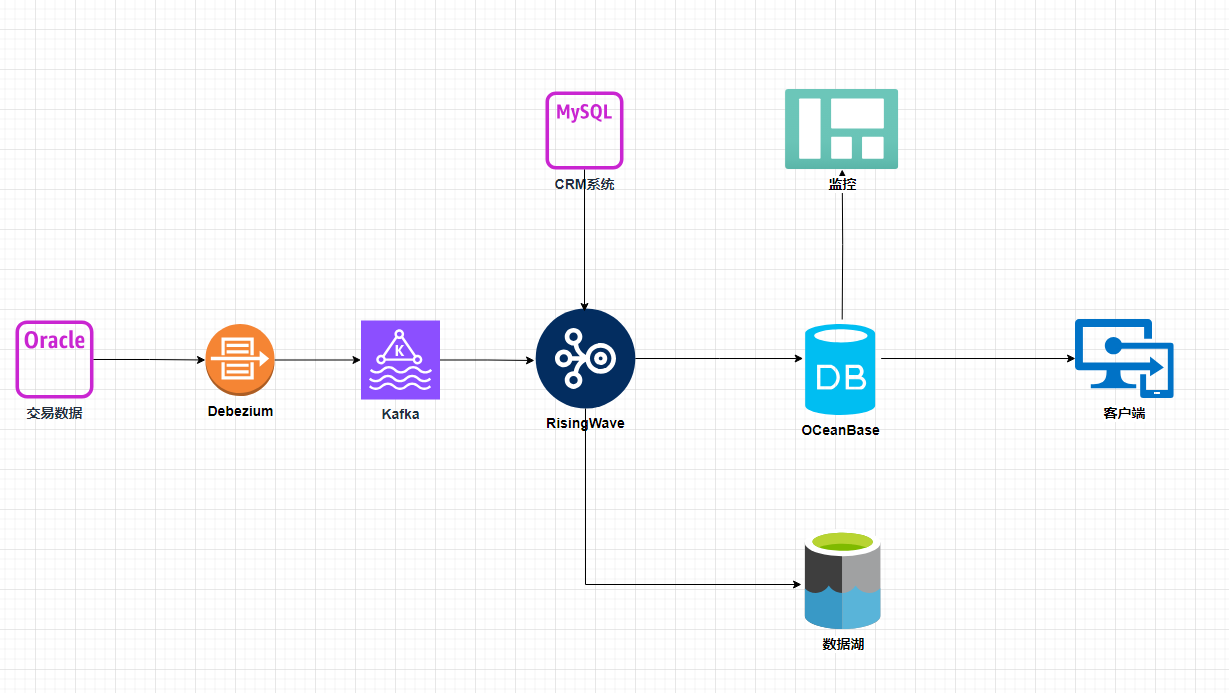
交易系统库,使用Oracle数据库,也是数据库的源头,储存了客户的交易信息、账面资金以及持仓情况。通过debezium与kafka推送至RisingWave。
客户管理系统库,使用MySQL,储存客户的各类权限、配置、个人信息等等。
OceanBase,作为Risingwave的下游,配置两个租户,一个用于交易监控或风控监控,另一个用于客户的电脑或者app客户端,了解自己的账户情况。
数据湖,用于存放额外的数据副本,使用对象存储与Iceberg来实现。
RisingWave,用于接收不同源头的数据库,一部分用于ETL,一部分用于实时计算。本次只部署了一个all-in-one版本用于测试。
准备工作
首先我们有6台服务器:192.168.1.1,用于配置kafka+debezium+iceberg connector
192.168.1.2,RisingWave服务器,版本2.3
192.168.1.3,Oracle交易库所在服务器,版本11g
192.168.1.4,CRM数据库服务器,版本8.0
192.168.1.5,OceanBase服务器,版本4.3.3
192.168.1.6,Iceberg Catalog服务所在服务器
第一步先配置debezium+kafka,在192.168.1.1的kafka目录下创建plugin目录,将debezium-connector与iceberg-connector目录都放到下面
# pwd
/opt/app/kafka/plugin
# ls
debezium-connector-oracle iceberg-kafka-connect-runtime-0.6.19在kafka的config目录下,编辑server.properties文件,如下内容,其中log.retention.bytes根据自己实际需要来调整:
listeners=PLAINTEXT://192.168.1.1:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.dirs=/tmp/kafka-logs
log.retention.bytes=10737418240
log.retention.check.interval.ms=300000
zookeeper.connect=localhost:2181编辑connect-standalone.properties文件,如下内容:
bootstrap.servers=192.168.1.1:9092
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.file.filename=/tmp/connect.offsets
offset.flush.interval.ms=10000
plugin.path=/opt/app/kafka/plugin新增oracle-source.json,配置oracle数据源,其中我们要采集的表包括TEST.TRADING,TEST.ACCOUNT
{
"name": "oratest-cdc-connector",
"config": {
"connector.class": "io.debezium.connector.oracle.OracleConnector",
"topic.prefix": "oracle-server",
"tasks.max": "1",
"database.hostname": "192.168.1.3",
"database.port": "1521",
"database.user": "debezium_user",
"database.password": "password",
"database.dbname": "TEST",
"database.server.name": "oracle-server",
"table.include.list": "TEST.TRADING,TEST.ACCOUNT",
"log.mining.strategy": "online_catalog",
"log.mining.archive.log.only.mode": "false",
"snapshot.mode": "initial",
"schema.history.internal.kafka.topic": "oracle_schema_history_internal",
"schema.history.internal.kafka.bootstrap.servers": "192.168.1.1:9092"
}
}创建CDC对象
在RisingWave里,我们会用到4种数据对象源source,配置上游数据源
表table,用于CDC同步数据到RisingWave
物化视图materialized view,用于实时计算
目标sink,实时写入目标端
我们在RisingWave创建三张表,分别是Oracle端的TEST.TRADING和TEST.ACCOUNT,以及CRM MySQL端的customer,表结构要和Oracle/MySQL原表结构一致,其中数据类型会有不同的映射,可以参考官方文档(表结构略)
CREATE TABLE TRADING(
...
)
WITH (
connector='kafka',
topic='oracle-server.TEST.TRADING',
properties.bootstrap.server='192.168.1.1:9092'
) FORMAT DEBEZIUM ENCODE JSON;
CREATE TABLE ACCOUNT(
...
)
WITH (
connector='kafka',
topic='oracle-server.TEST.ACCOUNT',
properties.bootstrap.server='192.168.1.1:9092'
) FORMAT DEBEZIUM ENCODE JSON;
CREATE TABLE customer(
...
)
WITH
CREATE SOURCE mysql_crm WITH (
connector = 'mysql-cdc',
hostname = '192.168.1.4',
port = '3306',
username = 'crm',
password = '123456',
database.name = 'crm',
server.id = 5888
);
CREATE TABLE customer (
...
) FROM mysql_mydb TABLE 'mysql_crm.customer';创建成功之后,可以通过select count(*)来确认条数是否对上
创建下游对象
在OceanBase,在交易监控租户创建同名表TRADING,注意表结构也要一致(表结构略)CREATE TABLE TRADING(
...
);CREATE TABLE CUSTOMER_POSITION(
...
);然后在RisingWave创建物化视图CUSTOMER_POSITION,源表是同步过来的TRADING、ACCOUNT、CUSTOMER
CREATE MATERIALIZED VIEW CUSTOMER_POSITION AS
select_query;接下来创建SINK,将物化视图和交易表同步给OceanBase两个租户
CREATE SINK CUSTOMER_POSITION_OB from CUSTOMER_POSITION
WITH (
connector='jdbc',
jdbc.url='jdbc:mysql://192.168.1.5:2881/test',
user='test@tenant1',
password='123456',
table.name='CUSTOMER_POSITION',
type = 'upsert',
primary_key = 'CUSTOMER_ID'
);
CREATE SINK TRADING_OB from TRADING
WITH (
connector='jdbc',
jdbc.url='jdbc:mysql://192.168.1.5:2881/test',
user='test@tenant2',
password='123456',
table.name='TRADING',
type = 'upsert',
primary_key = 'TRADING_ID'
);创建SINK,将3张同步过来的表写入Iceberg(同样需要提前在数据湖中建好三张表)
CREATE SINK TABLENAME_iceberg FROM TABLENAME
WITH (
connector = 'iceberg',
type = 'append-only',
force_append_only = true,
s3.endpoint = 'http://s3-service',
s3.region = 'ap-southeast-2',
s3.access.key = 'access.key',
s3.secret.key = 'secret.key',
s3.path.style.access = 'true',
catalog.type = 'rest',
catalog.uri = 'http://196.168.1.6:19120/iceberg',
warehouse.path = 's3a://iceberg',
database.name = 'test',
table.name = 'TABLENAME'
);同样通过select count(*)或者其他方式验证数据
小结
通过一个星期左右的测试,实际对RisingWave做一下如下总结反馈,优点是:1. 上手简单,基于Pg带来的优势
2. 实时性,无论是CDC还是物化视图,在内网实时性都非常好
3. 数据源丰富,无论关系型数据库,还是kafka或者数据湖
4. 成本,开源替代OGG带来的成本优势
当然也有期待提高:
1.支持原生Oracle connector
2.支持更多类型数据源,例如mongodb
最后修改时间:2025-04-23 09:40:22
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
