




PolarDB PostgreSQL 版分区表管理
关于 PolarDB PostgreSQL 版
PolarDB PostgreSQL 版是一款阿里云自主研发的云原生关系型数据库产品,100% 兼容 PostgreSQL,高度兼容Oracle语法;采用基于 Shared-Storage 的存储计算分离架构,具有极致弹性、毫秒级延迟、HTAP 、Ganos全空间数据处理能力和高可靠、高可用、弹性扩展等企业级数据库特性。同时,PolarDB PostgreSQL 版具有大规模并行计算能力,可以应对 OLTP 与 OLAP 混合负载。
分区表的管理
分区表的管理贯穿了它的整个生命周期,方便的管理语法更有利于用户的使用。下面我们将出分区表的创建,运维,删除,清理等过程介绍如何管理分区表。
创建分区表
PolarDB-PG 创建分区表的语法完全兼容PG。下面分别介绍其语法树,和各种类型分区表的例子。
CREATE TABLE [ IF NOT EXISTS ] table_name ( [
{ column_name data_type [ COMPRESSION compression_method ] [ COLLATE collation ] [ column_constraint [ ... ] ]
| table_constraint
| LIKE source_table [ like_option ... ] }
[, ... ]
] )
PARTITION BY { RANGE | LIST | HASH } ( { column_name | ( expression ) }
[ WITH ( storage_parameter [= value] [, ... ] ) | WITHOUT OIDS ]
[ TABLESPACE tablespace_name ]
PG的详细语法您可参考PostgreSQL文档,PolarDB-PG 对PG是百分百兼容的。
上面两个语法图介绍了PolarDB-PG 中如何创建分区表。下面分别介绍几个例子。
1. range partitioning
CREATE TABLE tab_range(id int, value int)PARTITION BY RANGE (id);
2. list partitioning
CREATE TABLE tab_list(id int, value int)PARTITION BY list (id);
3. hash partitioning
CREATE TABLE tab_hash(id int, value int)PARTITION BY hash (id);
注意PolarDB-PG中创建分区表时,默认时没有任何分区的,这时候如何数据插入都会出错, 因为它不能被定位到某个分区,需要再执行下面的新建分区语法创建分区,,虽然在PG中没有限制,但是我们不建议您建立分区超过三级。
新建分区
新建分区是指在已有的分区表上新增一个分区,同样的PolaDB-PG/O 提供了两套不同的语法来供您使用。
CREATE TABLE [ IF NOT EXISTS ] table_name
PARTITION OF parent_table [ (
{ column_name [ WITH OPTIONS ] [ column_constraint [ ... ] ]
| table_constraint }
[, ... ]
) ] { FOR VALUES partition_bound_spec | DEFAULT }
[ PARTITION BY { RANGE | LIST | HASH } ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [, ... ] ) ]
[ WITH ( storage_parameter [= value] [, ... ] ) | WITHOUT OIDS ]
[ TABLESPACE tablespace_name ]
PG的详细语法您可参考PostgreSQL文档,PolarDB-PG 对PG是百分百兼容的。
ALTER TABLE <table_name> ADD PARTITION <partition_definition>;
Where partition_definition is:
{<list_partition> | <range_partition>}
and list_partition is:
PARTITION [<partition_name>]
VALUES (<value>[, <value>]...)
[TABLESPACE <tablespace_name>]
[(<subpartition>, ...)]
and range_partition is:
PARTITION [<partition_name>]
VALUES LESS THAN (<value>[, <value>]...)
[TABLESPACE <tablespace_name>]
[(<subpartition>, ...)]
Where subpartition is:
{<list_subpartition> | <range_subpartition> | <hash_subpartition>}
and list_subpartition is:
SUBPARTITION [<subpartition_name>]
VALUES (<value>[, <value>]...)
[TABLESPACE <tablespace_name>]
and range_subpartition is:
SUBPARTITION [<subpartition_name>]
VALUES LESS THAN (<value>[, <value>]...)
[TABLESPACE <tablespace_name>]
下面分别介绍两种语法的案例:
1. range partition
CREATE TABLE tab_range_p1 PARTITION OF tab_range FOR VALUES FROM (minvalue) TO (100);
2. list partition
CREATE TABLE tab_list_p1 PARTITION OF tab_list FOR VALUES IN (10, 20, 30);
3. hash partitioning
CREATE TABLE tab_hash_0 PARTITION OF tab_hash FOR VALUES WITH (modulus 2, remainder 1);
PolarDB-PG在创建分区时,也可以将分区作为分区表再一次进行分区,不同的分区策略可以自由组合。
1. range partition
CREATE TABLE tab_range_p1 PARTITION OF tab_range FOR VALUES FROM (minvalue) TO (100) PARTITION BY List (value);
2. list partition
CREATE TABLE tab_list_p1 PARTITION OF tab_list FOR VALUES IN (10, 20, 30) PARTITION BY hash (value);
3. hash partitioning
CREATE TABLE tab_hash_0 PARTITION OF tab_hash FOR VALUES WITH (modulus 2, remainder 1) PARTITION BY range (value);
删除分区
删除分区是指在已有的分区表上删除一个分区,同样的,PolaDB-PG/O 提供了两套不同的语法来供您使用。
DROP TABLE [ IF EXISTS ] name [, ...] [ CASCADE | RESTRICT ]
PolarDB-PG 中删除分区和删除一个普通表的语法并无区别。在分区被删除后,数据也会丢失。删除一个分区时,它下面的所有子分区也会被删除。
附加/分离 分区(Detach/Attach)
Attach/Detach 是PolarDB-PG 兼容Postgres的语法。
Attach 用于将一个普通表附加到分区表中,成为分区表的一个分区。
Detach 用于将一个分区表的分区分离出来,成为一个普通表,它避免了将分区表中的数据直接删除,而分离出来移至别处。
ALTER TABLE [ IF EXISTS ] name
ATTACH PARTITION partition_name { FOR VALUES partition_bound_spec | DEFAULT }
ALTER TABLE [ IF EXISTS ] name
DETACH PARTITION partition_name [ CONCURRENTLY | FINALIZE ]
此形式Attach一个现有表(该表本身可能已分区)作为目标表的分区。 可以使用 FOR VALUES 将表附加为特定值的分区,或者使用 DEFAULT 将表附加为默认分区。 对于目标表中的每一个索引,都会在附属表中创建一个对应的索引; 或者,如果等效索引已存在,它将附加到目标表的索引,就像已执行 ALTER INDEX ATTACH PARTITION 一样。 请注意,如果现有表是外部表,并且目标表上有 UNIQUE 索引,则当前不允许将该表附加为目标表的分区。
这种形式Detach目标表的指定分区。 分离的分区继续作为独立表存在,但不再与其分离的表有任何联系。 附加到目标表索引的任何索引都将被分离。 任何作为目标表中触发器的克隆而创建的触发器都将被删除。 在外键约束中引用此分区表的任何表上都会获得共享锁。
如果指定 CONCURRENTLY,则它会使用降低的锁定级别运行,以避免阻塞可能正在访问分区表的其他会话。 在这种模式下,内部使用两个事务。 在第一个事务期间,对父表和分区都采用 SHARE UPDATE EXCLUSIVE 锁,并将分区标记为正在进行分离; 此时,事务已提交,并且使用分区表的所有其他事务都将等待。 所有这些事务完成后,第二个事务将获取分区表上的 SHARE UPDATE EXCLUSIVE 和分区上的 ACCESS EXCLUSIVE,并且分离过程完成。 与分区约束重复的 CHECK 约束将添加到分区中。 CONCURRENTLY 不能在事务块中运行,并且如果分区表包含默认分区,则不允许使用 CONCURRENTLY。
如果指定了 FINALIZE,则等待先前取消或中断的 DETACH CONCURRENTLY 调用将完成。 分区表中一次最多可以有一个分区挂起分离。
ALTER TABLE cities
ATTACH PARTITION cities_partdef DEFAULT;
ALTER TABLE measurement
DETACH PARTITION measurement_y2015m12;
重命名分区
每个分区都有自己的名称,像一个表一样,PolarDB-PG可以重名分区名称。
语法ALTER TABLE [ IF EXISTS ] name RENAME TO new_name
截断分区(Truncate)
就像截断表一样,PolarDB-PG可以指定一个分区被截断。TRUNCATE 快速删除一组表中的所有行。 它与每个表上的非限定 DELETE 具有相同的效果,但由于它实际上并不扫描表,因此速度更快。 此外,它会立即回收磁盘空间,而不需要后续的 VACUUM 操作。
TRUNCATE [ TABLE ] name [ CASCADE | RESTRICT ]
删除分区表
删除分区表则是将整体分区表和它的分区全部删除,在语法上普通表是一样的。
DROP [ TABLE ] name [ CASCADE | RESTRICT ]
DROP TABLE 从数据库中删除表。 只有表所有者、架构所有者和超级用户可以删除表。 要清空表中的行而不破坏表,请使用 DELETE 或 TRUNCATE。
DROP TABLE 始终删除目标表中存在的任何索引、规则、触发器和约束。 但是,要删除由另一个表的视图或外键约束引用的表,必须指定 CASCADE。 (CASCADE 将完全删除依赖视图,但在外键情况下,它只会删除外键约束,而不是完全删除另一个表。)
分区表的索引
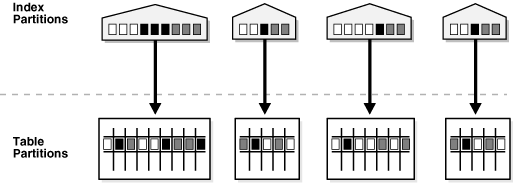
分区表通常有巨大的数据量,为了加快查询速度,索引是常见的选择。PolarDB-PG 支持分区上的两种类型索引:
本地索引 Local Index。 在本地分区索引中,本地索引是和分区表的分区一一对应的,具有与其表相同的分区数和相同的分区范围。每个索引分区都与基础表的一个分区相关联,因此索引分区中的所有键仅引用单个表分区中存储的行。 这样,数据库会自动将索引分区与其关联的表分区同步,从而使每个表索引对相互独立。本地索引是通过指定 LOCAL 属性创建的。 PolarDB-PG 构建本地索引,使其与基础表进行均分区。 PolarDB-PG 在与基础表相同的列上对索引进行分区,创建相同数量的分区或子分区,并为它们提供与基础表的相应分区相同的分区范围。当基础表中的分区被添加、删除、合并或拆分时,或者当散列分区或子分区被添加或合并时, PolarDB-PG 还会自动维护索引分区。 这可确保索引与表保持均匀分区。如果分区列构成索引列的子集,则可以创建 UNIQUE 本地索引。 此限制保证具有相同索引键的行始终映射到同一分区,在该分区中可以检测到唯一性违规。
全局索引 Global Index。全局索引是一种 B 树索引,它也可以被分区,其分区独立于创建它的基础表。 整个索引分区可以指向所有表分区,而在本地分区索引中,索引分区和表分区之间存在一一对应。全局索引也可以被分区,它的分区键必须是索引键的前缀。 Global Index是分区表所特有的,在后面的章节中,我们会单独进一步的介绍它。
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ [ IF NOT EXISTS ] name ] ON table_name [ USING method ]
( { column_name | ( expression ) } [ COLLATE collation ] [ opclass [ ( opclass_parameter = value [, ... ] ) ] ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [, ...] )
[ INCLUDE ( column_name [, ...] ) ]
[ WITH ( storage_parameter [= value] [, ... ] ) ]
[ TABLESPACE tablespace_name ]
[ WHERE predicate ]
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ [ IF NOT EXISTS ] name ] ON table_name
( { column_name | ( expression ) } [ COLLATE collation ] [ opclass [ ( opclass_parameter = value [, ... ] ) ] ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [, ...] ) GLOBAL
[ WITH ( storage_parameter [= value] [, ... ] ) ]
[ TABLESPACE tablespace_name ]
-- create unique local index
CREATE UNIQUE INDEX title_idx ON films (title);
-- create unique global index
CREATE UNIQUE INDEX title_idx ON films (title) global;
分区表的视图
PolarDB-PG 提供了系统视图,您可以使用它们来查看有关分区表结构的信息。
PolarDB-PG 提供了以下几个系统视图和系统函数来提供您查看数据库中分区表的相关信息。
pg_partitioned_table
pg_partitioned_table 系统表的字段描述见下表:
partrelid``partrelid | pg_class项的OID这个分区表的 pg_class项的OID |
partstrat``partstrat | h= 哈希分区表, l= 列表分区表, r= 范围分区表分区策略; h= 哈希分区表, l= 列表分区表, r= 范围分区表 |
partnattspartnatts | |
partdefid``partdefid | pg_class项的OID,如果这个分区表没有默认分区则为零。这个分区表的默认分区的 pg_class项的OID,如果这个分区表没有默认分区则为零。 |
partattrs``partattrs | partnatts值的数组,它指示哪些表列是分区键的组成部分。例如,值 1 3表示第一个和第三个表列组成了分区键。这个数组中的零表示对应的分区键列是一个表达式而不是简单的列引用。这是一个长度为 partnatts值的数组,它指示哪些表列是分区键的组成部分。例如,值 1 3表示第一个和第三个表列组成了分区键。这个数组中的零表示对应的分区键列是一个表达式而不是简单的列引用。 |
partclass``partclass | pg_opclass``pg_opclass |
partcollation``partcollation | |
partexprs``partexprs | nodeToString()的表达方式)。这是一个列表, partattrs中每一个零项都有一个元素。如果所有分区键列都是简单列引用,则这个域为空。非简单列引用的分区键列的表达式树(以 nodeToString()的表达方式)。这是一个列表, partattrs中每一个零项都有一个元素。如果所有分区键列都是简单列引用,则这个域为空。 |
select * from pg_partitioned_table;
partrelid | partstrat | partnatts | partdefid | partattrs | partclass | partcollation | partexprs | partnullorder
-----------+-----------+-----------+-----------+-----------+-----------+---------------+-----------+---------------
17124 | h | 1 | 0 | 1 | 10028 | 0 | | 0
(1 row)
pg_partition_tree
pg_partition_tree (PolarDB-PG 2.0版本支持)函数的返回字段描述见下表:
输入人参数 tablename.
select * from pg_partition_tree('idxpart');
relid | parentrelid | isleaf | level
----------+-------------+--------+-------
idxpart | | f | 0
idxpart0 | idxpart | t | 1
idxpart1 | idxpart | t | 1
(3 rows)
pg_class
pg_class 存放了PolarDB-PG中所有的表和索引的对象,其中有一部分信息和分区表有关,下面介绍和分区表有关的字段。
relkind | pI= 分区索引 p= 分区表, I= 分区索引 |
relhassubclass | |
relispartition | |
relpartbound | relispartition),分区边界的内部表达如果表示一个分区(见 relispartition),分区边界的内部表达 |
select relkind , relhassubclass, relispartition, pg_catalog.pg_get_expr(relpartbound ,oid) as relpartbound, relpartname from pg_class where relname = 'sales_q1_2012';
relkind | relhassubclass | relispartition | relpartbound | relpartname
---------+----------------+----------------+------------------------------------------------------+-------------
r | f | t | FOR VALUES FROM (MINVALUE) TO ('01-APR-12 00:00:00') | q1_2012
(1 row)
pg_inherits
inhrelid | |
inhparent | |
inhseqno | |
inhdetachpending | truefalse。 PolarDB-PG 2.0以上支持 true用于正在脱离进程中的分区;否则为 false。 PolarDB-PG 2.0以上支持 |
select * from pg_inherits where inhrelid = 17136;
inhrelid | inhparent | inhseqno
----------+-----------+----------
17136 | 17133 | 1
(1 row)
