




本文对微软、亚马逊、AWS、Meta、Stripe公司共同编写的2024 VLDB论文《Flexible Resource Allocation for Relational Database-as-a-Service》进行解读,全文共7669字,预计阅读需要30至40分钟。
对于云数据库提供商而言,超额预订是一种至关重要的成本管理策略,而无服务器数据库这一新兴范式的出现更是凸显了其重要性。与虚拟机监控程序、操作系统和集群管理器中使用的通用超额预订技术不同,该技术旨在以低开销在节点和集群层面灵活地跨数据库租户重新分配资源。通过微基准测试、行业标准基准测试和真实资源使用轨迹进行的实验表明,即使在相对较高的超额预订程度下,也能够严格控制对数据库性能的影响。
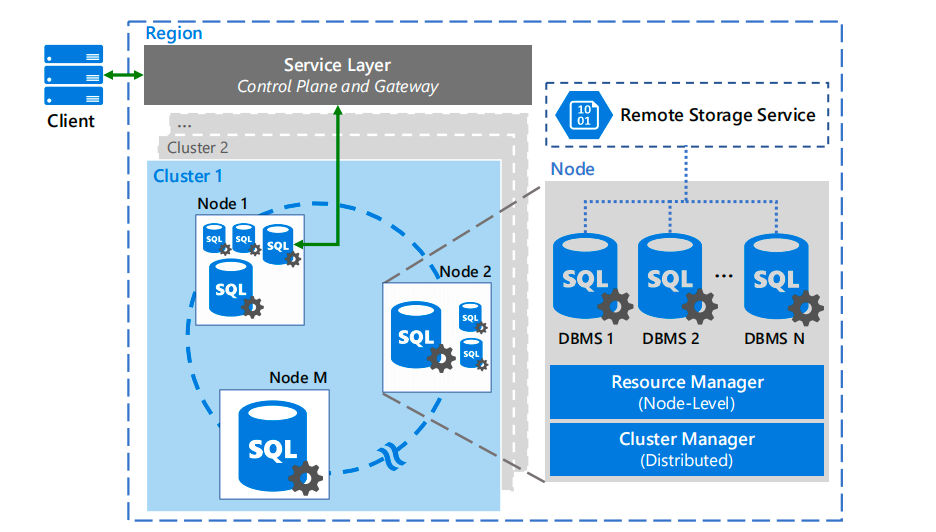
Azure SQL Database框架概述
1.1研究背景
随着企业数字化转型的深入,关系型数据库即服务(DBaaS)如Microsoft Azure SQL Database、Amazon Aurora 等已成为支撑在线事务处理和混合事务/分析处理workloads的核心基础设施。这类服务普遍采用多租户架构,通过共享物理资源提升利用率,但也面临严峻的成本管理挑战。传统预配置模式下,用户为固定资源付费,导致数据中心存在大量未充分利用的容量;而无服务器DBaaS的兴起进一步推动了按需付费模式,对资源利用率和成本控制提出了更高要求。
1.2研究介绍
Azure SQL Database 主要描述关系型云数据库服务的主要基础设施组件。Azure SQL 数据库是一种基于Microsoft SQL Server 的高可用性、多租户关系型云数据库服务,面向在线事务处理和混合事务/分析处理工作负载。作为托管服务,它自动化执行多项关键管理任务,包括资源调配、升级、备份、高可用性保障、安全管理,并提供自动调优功能。
1.2.1Azure SQL数据库
数据库租户托管在多个集群的共享节点上。每个租户可能有一个或多个副本分布在这些节点上,以实现高可用性。多个租户可以共享同一物理节点,但会被隔离到独立的容器中。节点级资源管理器控制资源在该节点上所有租户之间的共享方式。
1.2.2资源使用模式
为了说明资源超额预订的必要性并阐述由此带来的挑战,分析了Azure SQL 数据库生产集群的资源消耗情况。收集的数据记录了一个具有代表性的40节点集群一周的运行轨迹。
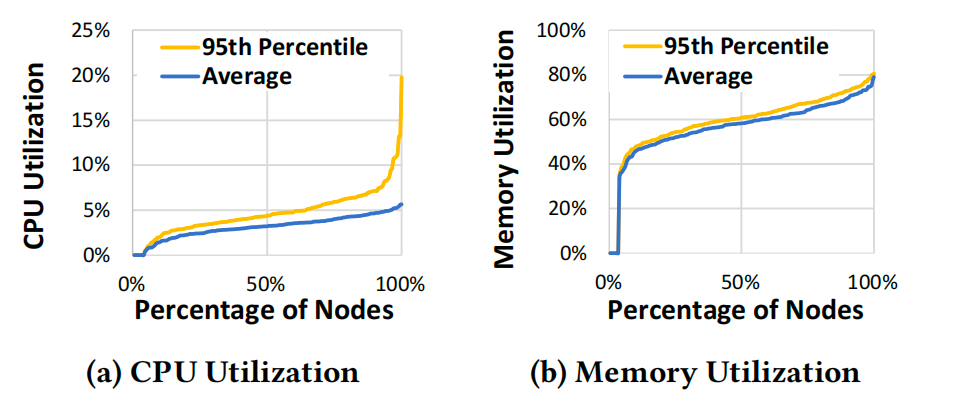
图a CDF cpu使用资源量 图b CDF内存使用资源量
CPU利用率:我们在每个节点上收集了CPU和内存利用率读数,取15秒间隔的平均值。随后,我们对这些读数进行了汇总,包括观察期内整周的平均值和第95百分位数。
内存利用率:上图b中展示了集群范围的主内存利用率,其显著高于CPU利用率。平均利用率与第95百分位数利用率之间的差异并不明显,这表明总体而言内存利用率更为稳定。
1.2.3面临问题
尽管集群的内存利用率远高于CPU利用率,但相当一部分缓存内存往往处于 “冷” 状态。为了量化这一点,我们对集群中所有数据库租户的页缓冲池中的页面最后访问时间进行了随机抽样。
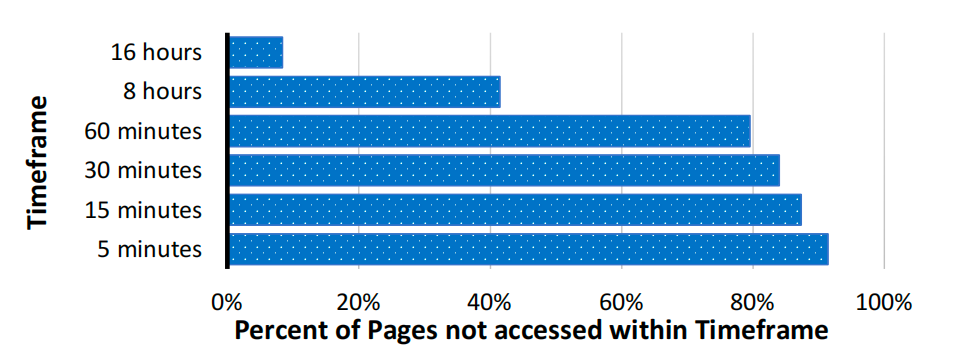
集群中缓冲池页面的访问频率
集群中缓冲池内近80%的页面超过60分钟未被访问,超过40%的页面超过8小时未被访问,这表明缓冲池内存中存在大量冷数据。数据库的这种长寿命特性为如何将数据库协同定位到集群节点上带来了额外挑战。
2.1Dbass架构
在超额预订的数据库即服务(DBaaS)集群中,租户之间的资源竞争可能导致资源短缺。为有效解决这个问题提出Dbaas架构。下图展示了该技术如何融入云数据库即服务(DBaaS)的软件架构。主要描述了一个针对每种资源按特定资源超额预订率进行超额预订的系统。某资源的超额预订率是指,承诺给节点或集群上租户的该资源总量,分别除以节点或集群上该资源的物理容量所得到的比率。

云数据库即服务中灵活资源分配机制概述
2.2 Dbaas特点分析
2.2.1 检测资源违规
为了触发本文所述的各种技术,我们需要能够检测即将发生的资源短缺。为此采用“资源违规” 这一概念,将其定义为节点的资源使用量超过预定义阈值。为捕获违规情况,节点级资源管理器会监控单个数据库和整个节点的资源使用情况,并定期向集群管理器报告。
2.2.2 缓解节点资源短缺
节点上的长期资源短缺只能通过将一个或多个数据库迁移到集群中的其他节点来缓解。多租户内存代理技术,该技术通过选择性地在租户间重新分配内存。当多个数据库管理系统(DBMS)共享CPU且被亲和到重叠的CPU集合时,即使节点整体CPU利用率较低,单个核心仍可能发生资源违规。
2.2.3租户放置
通过主动优化数据库租户在集群节点上的放置,以降低每个节点长期发生资源短缺的可能性。该技术主要目的是在将数据库放置为使资源违规的可能性最小化。租户放置决策在新数据库加入或现有数据库在集群内迁移时做出。
3.1多租户Dbaas
多租户DBaaS内存超额预订易致短缺,且数据库内存footprint随生命周期增长,即便缓存为冷。多租户内存代理技术至关重要,可按需重新分配内存,应对单或少数活跃数据库短期内存需求,最小化性能影响、避免租户迁移,与租户迁移结合降低OS级内存节流使用。
3.1.1问题公式化
任何跨租户重新分配内存的技术都必须解决几个关键挑战。首先,它必须能够建模内存对每个数据库性能的影响,同时考虑数据库管理系统(DBMS)中内存的各种用例,包括各类缓存。其次,制定跨租户通用指标衡量内存对性能的影响,并能够处理租户优先级不同的情况。最后,作为可行的生产方案,该技术必须高效 —— 即对每个 DBMS施加的开销低,且能快速响应内存压力。
3.1.2内存价值
我们设计的核心是 “内存价值(VoM)” 概念。尽管 VoM通过缓存对象定义,但其定义可扩展到数据库内存的其他用例(如工作内存)。缓存对象的VoM衡量了缓存该对象相比不缓存预计节省的系统时间。
3.1.3内存回收目标与0-1背包问题
当节点内存使用超过 “内存代理阈值” 时,触发多租户内存代理。若当前内存使用比该阈值高α单位,目标是通过从节点上一个或多个数据库回收总计。
M=α+(MemoryBrokeringThreshold−ReclamationTarget)
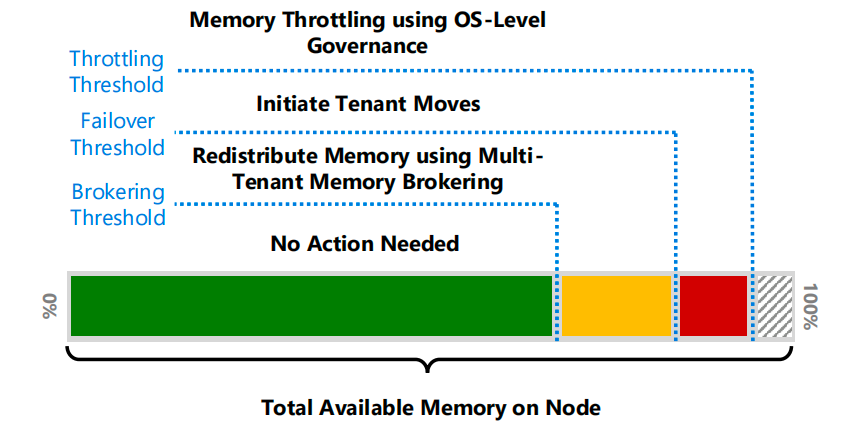
节点级内存机制与阈值
单位的内存,将所有租户的总内存消耗降至更低的回收目标,同时最小化对所有租户的总性能影响。
3.2Dbaas在Azure SQL 数据库中的实现
3.2.1架构概述与流程
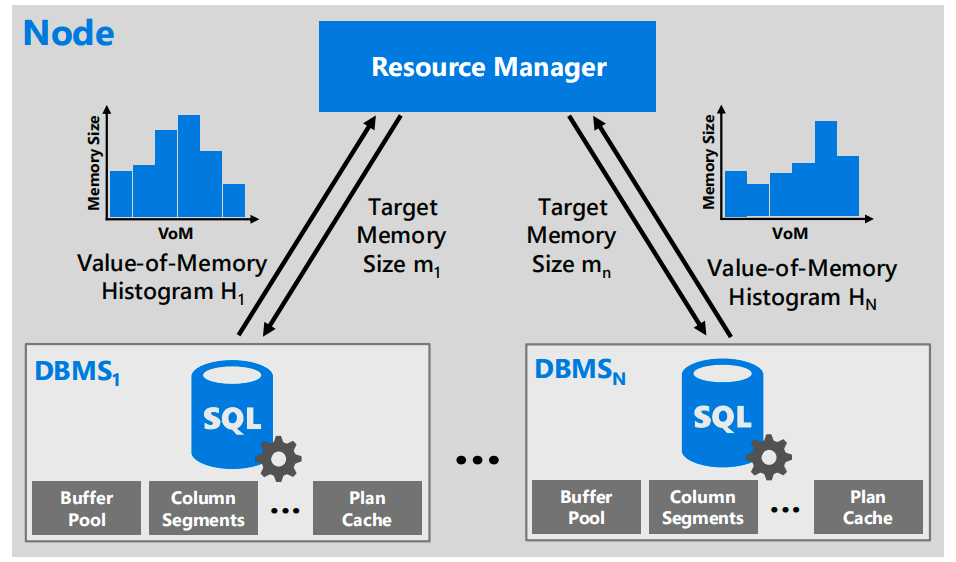
多租户内存代理架构
上图展示了多租户内存代理的高层架构:当资源管理器检测到内存利用率上升时,会向每个租户请求其内存价值。为确保DBMS内存回收生效并检测需故障转移的持续内存压力,两次内存代理调用间设置1分钟冷却期。
3.2.2基于直方图的高效优化方法
由于数据库包含大量不同大小的缓存对象,系统采用紧凑等深直方图汇总租户内存消耗者的VoM分布,每个桶代表一个VoM区间并跟踪对象数量和总大小。节点资源管理器基于直方图求解优化问题,通过贪心启发式算法选择VoM最低的桶回收内存。直方图计算仅在内存压力下触发,单租户单次直方图大小约11 KB,通信与空间开销随租户数量线性增长。
3.3VoM 直方图计算细节
3.3.1缓冲池
随机抽样少量页面,利用现有每页系统时间节省值,计算VoM,通过抽样比例反推特定VoM的对象数量。访问频率(λᵢ)基于改进的LRU-K页面淘汰机制记录的最近引用估算。
3.3.2其他系统缓存
对缓存中的较大对象(如列段、查询执行计划)进行全量扫描,利用特定类型的成本模型(如查询计划编译时间)获取STS,λᵢ基于存储的最近引用估算。
3.3.3空闲页
空闲页的VoM反映操作系统页面分配成本(通常远低于缓存对象),确保DBMS优先释放空闲页而非其他缓存对象,减少对性能的影响。
在CPU资源超额预订的多租户数据库即服务(DBaaS)中,多个数据库租户可能需要共享同一物理CPU核心。当其中两个或多个租户同时出现高CPU需求时,核心可能被过度利用,租户可能无法获得分配的CPU周期份额。
4.1约束条件
大多数现代数据库系统使用自定义线程管理来控制内部任务的并行性和优先级,以减少上下文切换开销,并保证缓存和数据局部性。此外,每个租户的服务水平目标(SLO)对应一定数量的CPU资源分配。这是一个平台抽象层,为线程调度、内存管理、异步IO和同步提供自定义功能。
4.2仿射概念与再平衡
为应对核心级CPU资源竞争,系统通过显式仿射性(Affinization)将租户绑定到特定物理核心,而非依赖操作系统的工作窃取机制。节点资源管理器每15秒监控核心利用率,当某核心利用率超过阈值时,通过贪心算法重新分配租户绑定的核心集合(如图7),以缓解单核心过载。此机制在租户平均CPU变化导致的不平衡与重新绑定开销间取得平衡。
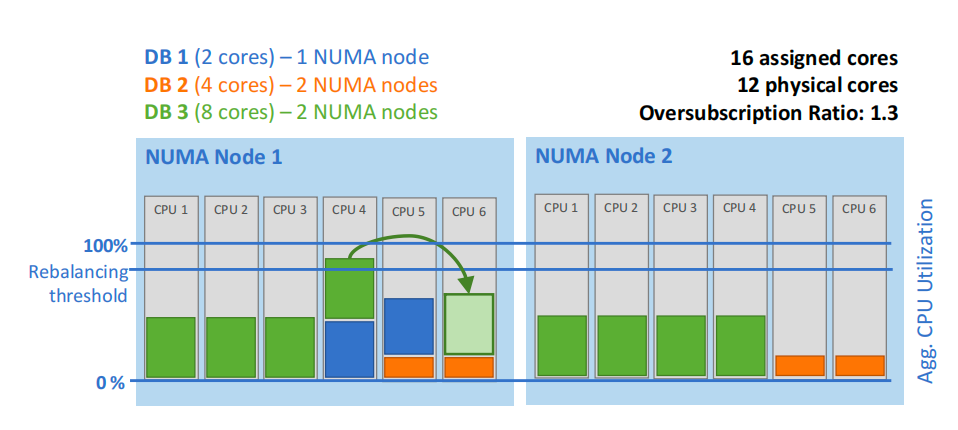
避免超额预订核心出现高CPU利用率的重新平衡操作示例
4.3CPU节流
若核心重平衡仍无法解决高利用率(如全节点平均CPU超阈值),节点标记为 “过热”,触发集群管理器迁移租户。期间通过操作系统级CPU速率限制(如Windows Job Object 或Linux cgroup)作为最后防线,确保CPU资源公平分配并防止主机过载
5.1背景与挑战
在超额预订的DBaaS中,租户到集群节点的分配对平衡资源可用性与有效利用率至关重要。数据库租户具有长生命周期(56天中位数)、状态累积和资源需求动态变化的特点,导致基于实时资源快照的传统放置策略易引发不必要的资源违规
5.2 PLb机制
PLB将租户副本在集群中的分配视为在线优化问题,需满足副本亲和性/反亲和性、资源使用约束等条件。候选配置通过 “搜索算法” 枚举,通过 “评分函数” 筛选最优解,核心组件包括:
配置枚举:为待放置/迁移的副本选择无约束冲突的目标节点,随机生成初始种子配置,再通过模拟退火算法随机迁移副本探索配置空间,直至超时。
评分函数:最小化两项乘积——节点资源标准差加权和(均衡资源分布)与预期故障转移加权和(降低迁移开销与未来违规风险),同时纳入租户活跃度、资源使用量等因素。
5.3评分函数核心组件
5.3.1预期故障转移估算
通过蒙特卡洛(MC)模拟,利用历史租户资源需求轨迹,模拟节点资源需求的可能结果,计算至少发生一次资源违规的MC迭代比例,作为违规概率。该概率作为预期故障转移的下界,计入PLB评分函数,平衡当前配置的迁移成本与未来违规风险。
5.3.2租户权重分配
为最小化故障转移的服务中断,根据租户特征分配权重:
磁盘/内存使用:采用对数变换(DiskUsage、MemUsage,单位MB)量化迁移数据量影响。活跃度(Activity):0(非活跃)或1(活跃),非活跃租户故障转移影响更低。
移动成本公式:
MoveCost=αlog2(DiskUsage)+βlog2(MemUsage)+γ⋅Activity
通过离线校准常数α、β、γ,将移动成本分为低、中、高三档,减少活跃/大状态租户的不必要迁移。
5.3.3新租户资源预留
针对新租户生命周期早期快速增长(如数小时内高活跃度)的特点,基于历史数据记录各租户类别在生命周期前24小时的90百分位资源消耗量,作为初始资源需求输入PLB。确保新租户副本仅放置在有足够空闲资源容纳其预期增长的节点,减少早期资源违规,同时避免显著降低集群容量。
故障转移租户需中止所有运行中的事务,将客户端连接转发至新节点,并将数据库文件附加到目标节点的数据库引擎进程。由于集群内网络传输远快于从云端远程存储读取,通过直接将缓冲池内容从源节点复制到目标节点,可高效重建缓冲池。缓冲池迁移机制所有权转移操作如下:
暂停所有现有写事务,迁移剩余修改页至目标节点。
目标节点同步完成后,源节点取消所有开放事务并释放数据库文件句柄。
目标节点打开数据库文件,处理迁移缓冲池中可能的不一致性(如陈旧或回滚的脏页)。
本节对本文所述的多租户资源分配技术进行实证评估。我们的实验采用标准TPC-C基准测试的变体或微软的云数据库基准测试(CDB)。实验在本地集群上进行,节点配置为双路AMD EPYC 7352 处理器(每颗24核心)和256 GB DRAM,所有数据和日志文件存储在同一集群托管的远程SSD上,其性能特征与SQL数据库的通用服务层相似。我们根据等效的Azure SQL 数据库SKU为每个数据库限制可用IOPS。
7.1多租户内存代理实验评估
多租户内存代理旨在减少内存容量违规次数,同时避免对性能造成显著影响。以下通过与三种不感知数据库的代理策略对比,评估基于VoM(内存价值)的数据库感知内存代理技术的有效性,这些策略代表了用户通过VM或OS级内存管理配置跨租户内存共享的典型方式。
7.1.1对比策略与实验设置
实验设置两个8核数据库DB1(冷,非活跃)和DB2(暖,活跃),共享26 GB 内存,运行相同TPC-C工作负载,每数据库保底3 GB 内存。当节点总内存消耗超过25 GB 时触发内存代理(每分钟最多一次),回收目标设为24 GB,每次回收1-2 GB。通过让活跃的DB2从冷态DB1回收内存,模拟典型的 “暖数据库从冷数据库获取内存” 场景。
7.1.2实验结果
性能对比:DB2在工作负载启动后的前10分钟内存需求最高,此时VoM策略的每秒事务数(TPS)显著优于其他策略。与次优的Balloon策略相比,VoM的中位数TPS提升14%,95百分位提升26%;Proportional和Equal策略的TPS表现更差。
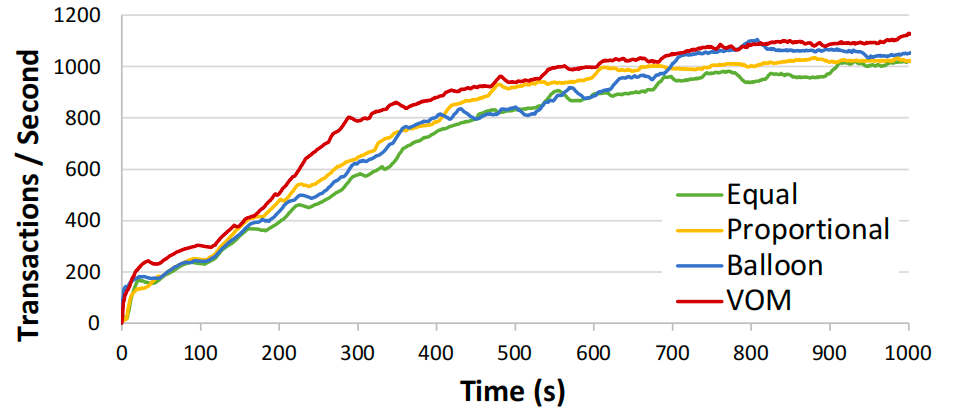
不同内存回收策略的TPC-C事务吞吐量(2分钟移动平均值)
内存分配:VoM策略优先回收DB1的冷内存(其缓冲池页面VoM远低于DB2的活跃页面),使DB2快速增长。Balloon策略因全局内存压力导致所有数据库释放内存,即使DB2的活跃页面也被回收,严重影响性能。Proportional策略在DB2较小时有效,但随其内存增长效率下降;Equal策略在DB2较大时表现稍好,但初始阶段不如VoM。
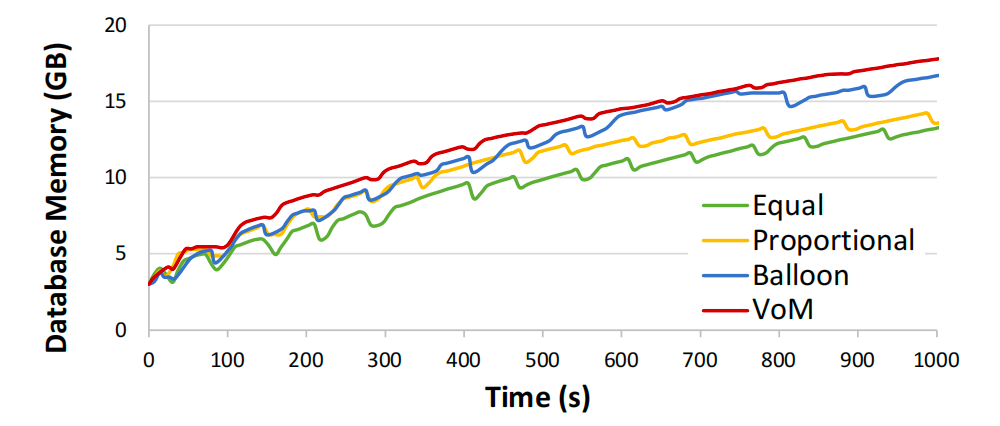
使用不同内存回收策略的主动增长数据库实例的内存消耗
7.1.3生产环境部署效果
在200节点的生产集群中,引入多租户内存代理后,内存容量不足导致的故障转移次数减少68%,且数据库吞吐量和延迟等性能指标未发生显著变化,验证了该技术在真实DBaaS环境中的有效性。
7.2基于CPU利用率的再平衡实验评估
为验证动态平衡数据库CPU核心分配的重要性,我们将第5节所述的基于利用率的动态重新平衡技术与静态核心分配方案(初始分配后不再调整)进行对比,证明重新平衡对减少 “过热超额预订核心” 的必要性,并验证不定期重新评估核心分配对工作负载性能的显著影响
7.2.1实验环境
本测试共采用,8个8核数据库共享32个物理核心(超额订阅率2×),通过CDB基准测试模拟CPU密集型工作负载,每个数据库在高CPU(48连接)和低CPU(16连接)状态间切换,形成突发负载模式(每20分钟中15分钟随机选1个数据库进入高CPU状态,其余为低CPU)。
测量指标:物理核心利用率(15秒间隔)、热核心数量(利用率≥95%且承载≥2个活跃数据库的核心)、事务吞吐量(TPS)和查询延迟。
7.2.2热核心数量对比
静态分配:平均每15秒间隔出现6.0个热核心,涉及4个共置租户,3小时内累计2642.8次热核心违规,集中在436.8个间隔中。
动态重新平衡:热核心数量骤降至平均每间隔1.1个,涉及2.1个租户,累计仅7.4次违规,分布在6.4个间隔中。
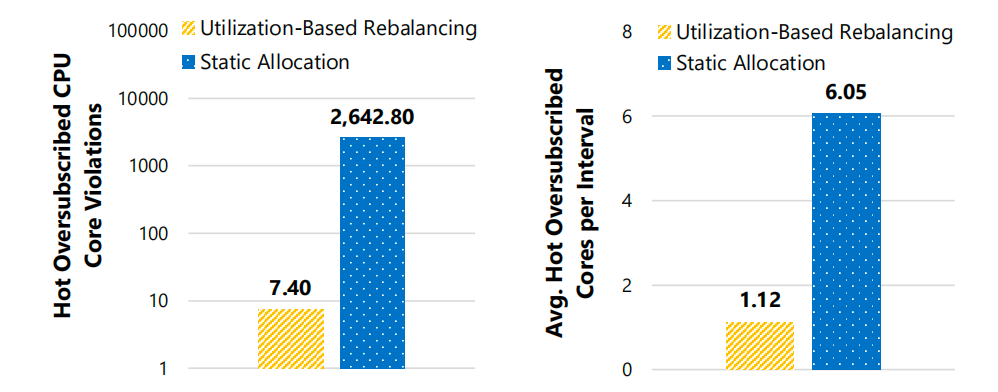
CDB工作负载下不同15秒间隔内的过热超额预订CPU核心数量x
结论:动态方案通过实时调整核心分配,显著减少核心过载,避免多租户竞争导致的性能瓶颈。
7.2.3工作负载性能影响
静态分配:因初始分配不当,部分核心利用率达 100%,尽管节点整体 CPU 资源充足,仍导致活跃数据库事务吞吐量下降 20%(从 335 TPS 降至 280 TPS),50/95/99 百分位查询延迟从 0.016/0.032/0.047 秒恶化为 0.141/0.250/0.297 秒。
动态重新平衡:通过将活跃租户与空闲租户的核心分配分散,避免单一核心过载,维持稳定的吞吐量和低延迟。
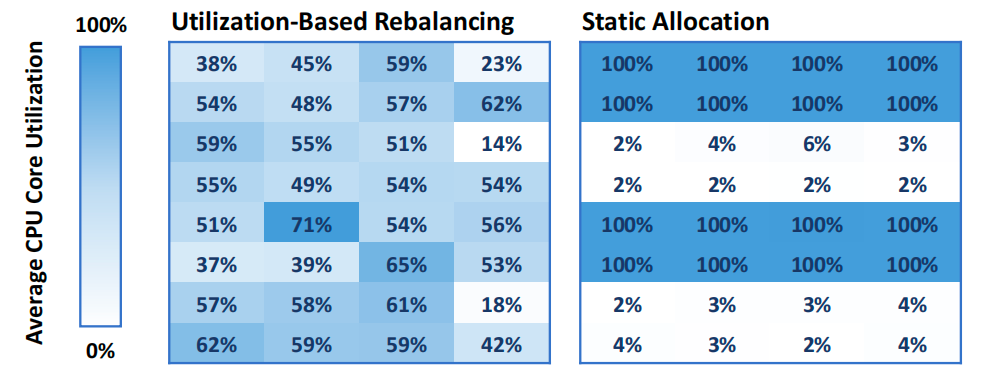
执行CPU密集型CDB工作负载且负载高度不均衡时节点上所有数据库核心的平均CPU利用率
实验验证了动态CPU重新平衡在多租户DBaaS中的关键作用:通过主动管理核心亲和性,系统能在高超额订阅场景下减少核心过载,保障租户性能稳定性,显著优于静态分配方案。这一技术为解决CPU资源竞争问题提供了高效且低开销的解决方案。
7.3租户放置实验评估
实验使用为Service Fabric 开发的高保真集群级PLB模拟器,跟踪模拟集群中的资源违规和租户迁移。租户资源使用通过Azure SQL 数据库生产租户的7天资源需求轨迹模拟,随机选取自两个资源使用模式差异显著的地理区域,轨迹包含10分钟粒度的CPU、内存和本地磁盘使用数据。
7.3.1模拟实验结果
资源违规与故障转移:原始Service Fabric PLB 的平均资源违规次数是改进版的1.83倍,故障转移次数是1.67倍。结果表明,在放置和负载均衡决策中纳入资源需求随时间的变化至关重要,改进后的PLB通过历史数据预测未来需求分布,显著减少了违规和迁移次数。
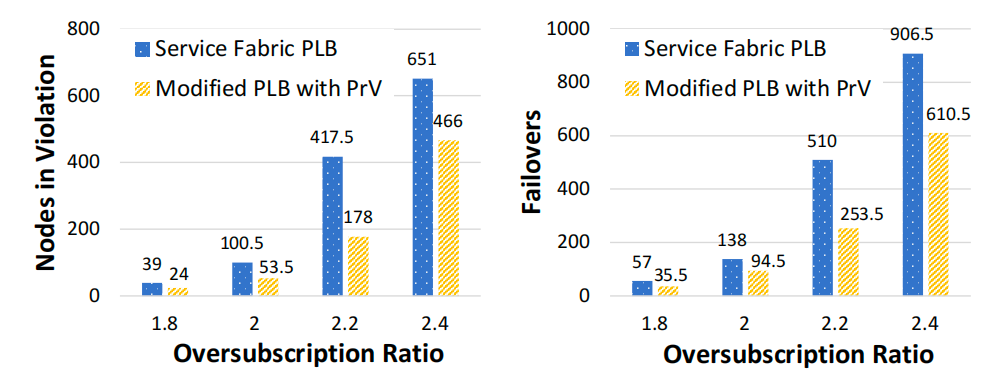
使用PLB模拟器时不同Azure区域租户的平均违规次数和故障转移次数
7.3.2真实集群部署
在Microsoft Azure 的40节点真实集群中重复实验(使用真实客户资源轨迹但不执行实际工作负载),原始PLB的平均资源违规次数是改进版的2.4倍,与模拟实验结果一致,验证了技术在真实环境中的有效性。

真实集群部署中的违规次数
7.3.3移动成本(MC)与新租户资源预留(ARU)的影响
将不同算法进行组合,对比实验服务的质量结果如下图:
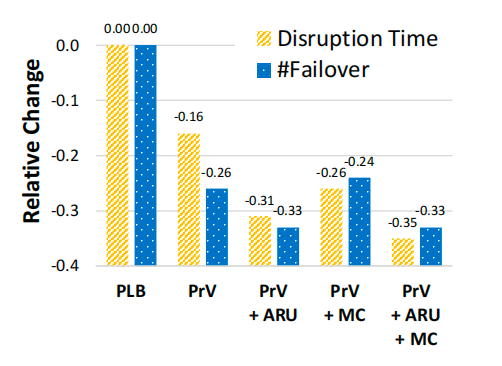
不同算法组合的服务质量提升
移动成本(MC):通过为不同租户故障转移分配权重(基于磁盘/内存使用和活跃度),显著减少了活跃租户的总中断时间,相比未使用MC的算法,中断时间降低幅度达26%-35%。
新租户资源预留(ARU):基于历史数据为新租户预留资源(使用前24小时90百分位资源消耗),有效减少故障转移次数,相比未使用ARU的算法,故障转移次数降低24%-33%。
组合效应:MC和ARU的结合未导致非目标指标退化,证明两者可互补优化服务质量。
7.4故障转移性能实验评估
7.4.1实验环境设置
测试对象:运行TPC-C工作负载的活跃数据库,故障转移至同集群内的新节点,对比两种场景:
启用缓冲池迁移(本文方法):通过推式迭代预复制方案迁移关键缓存页面(如缓冲池中的热页)。
传统故障转移:不保留缓存,故障转移后数据库需重新从存储加载数据(等效于清空缓冲池)。
7.4.2实验结果
将传统方法和本文方法结果进行多方面对比:
故障转移延迟:
传统方法:因需中止所有事务并重新加载数据,延迟达1200ms,主要耗时在缓冲池重建(从存储读取数据)。
本文方法:通过预复制缓冲池热页,延迟降至450ms,减少了62.5%,其中后台预复制阶段承担了70%的缓存迁移,仅30%的脏页在最终同步阶段处理。
在吞吐量恢复方面:
传统方法:故障转移后吞吐量骤降至峰值的30%,需约800ms恢复至稳定状态,因缓冲池内容完全丢失,大量查询触发磁盘I/O。
本文方法:吞吐量最低降至峰值的75%,仅需300ms恢复,因保留了大部分热页,减少了对磁盘的依赖。
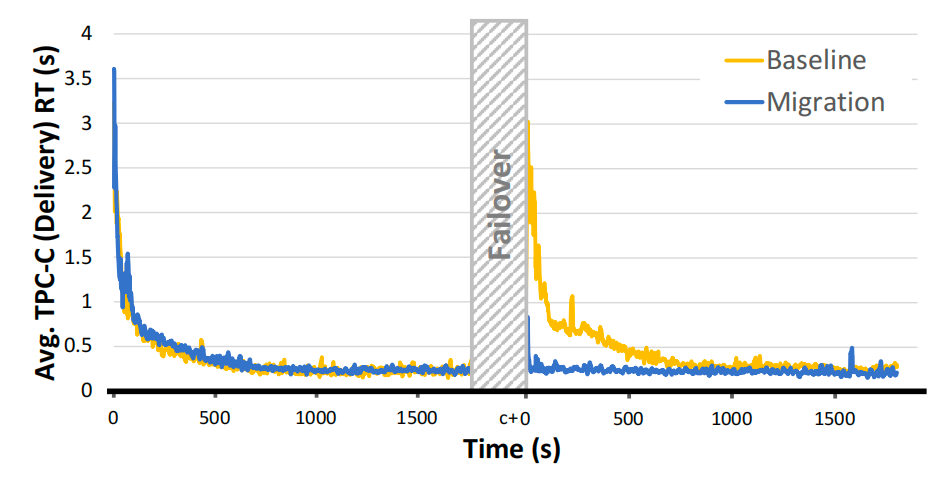
启用(迁移)和未启用(基准)缓冲池内容保留时,故障转移对TPC-C交付事务平均查询响应时间的影响(500个仓库)
缓冲池迁移机制在不显著增加故障转移延迟的前提下,通过保留关键缓存内容,将活跃租户的吞吐量下降幅度减少45%,恢复时间缩短62.5%,证明了低开销缓存保留技术在平衡故障转移效率与性能影响上的有效性。
8.1通用超额预订技术vs数据库感知的白盒方法
黑盒技术(如电源封顶、虚拟化资源超额预订)适用于任意应用,但未针对数据库特性优化。
白盒方法利用 DBMS 内部资源使用机制(如缓存、CPU 亲和性),在高超额预订下最小化性能影响,优于通用技术。
8.2多租户资源管理相关研究对比
SQLVM:聚焦单个 DBMS 实例内资源共享,本文针对独立进程的多租户架构,需跨租户通用指标(如 VoM)。
动态资源重新分配:补充了空闲数据库按需恢复技术,实时调整活跃数据库资源,而非仅启停操作。
租户放置:现有工作基于实时资源快照,本文纳入资源使用的时间动态变化,减少长期资源短缺。
8.3租户放置与整合的差异
传统方法优化服务器数量或负载均衡,本文固定集群规模,目标是最小化资源违规,避免频繁故障转移。
数据库长生命周期特性要求预测资源需求变化,而非依赖静态分配或单次整合。
8.4故障转移与迁移技术
传统实时迁移技术成本高(迁移大量状态、时间长),本文缓冲池迁移方案仅传输关键页面,结合租户活跃度管理,平衡性能影响与效率。
降低成本是数据库即服务(DBaaS)提供商面临的主要挑战,尤其是在无服务器数据库日益流行的趋势下。资源超额预订是实现这一目标的重要工具,它通过提高数据库集群的资源利用率来降低成本。
本文针对多租户DBaaS架构开发了灵活的资源分配技术,该技术利用了我们对服务器资源受限如何影响数据库性能的理解。这使得数据库的部署密度比传统方法更高,同时能够控制对数据库性能的影响。本文为未来多租户DBaaS资源分配的研究奠定了基础,例如通过控制数据库在数据中心内集群的分配决策来提高效率,以及在无服务器数据库中实现性能与成本的权衡。
论文解读联系人:
刘思源
13691032906(微信同号)
liusiyuan@caict.ac.cn





