





在大模型蓬勃发展的当下,智能需求激增,传统数据平台面临非结构化数据处理能力不足、算力瓶颈、存储分散等诸多挑战。
火山引擎多模态数据湖解决方案是面向AI时代的智能数据新基建,完整覆盖湖计算、湖存储、湖管理、湖分析等功能场景。可帮助企业在数据建设全链路过程中,实现文本、图像、音视频等非结构化数据资产的统一精细化管理,为模型预训练、后训练、AI 应用构建与开发提供端到端的智能数据服务。
4月22日,在Force Link AI 创新巡展·深圳站上,火山引擎发布了全新的AI数据湖服务(Lake AI Service,简称LAS)。
作为多模态数据湖方案中的重要产品,LAS能够帮助客户快速构建新一代AI数据湖,高效存储、管理和处理多模态数据(文本、图像、音视频等)。在产品协同性上,LAS链接了云上的多种基础设施,同时可以和火山近期发布的veMLP机器学习平台、以及火山MaaS方舟平台高效协同,支持数据准备、模型微调等场景,加速AI落地。
从实际客户案例来看,某企业借助火山引擎AI数据湖服务和豆包大模型实现文本翻译提效,数据处理上实现了零代码操作,开发周期缩短70%,翻译准确率提升20%,资源成本降低80%以上。

以下为现场演讲实录:
尊敬的来宾们,大家好。大模型时代,数据是加速企业AI落地重要的生产资料。从数据视角,企业落地AI应用时,数据平台面临着新的挑战。
一是处理数据多元化。企业积累的客服语音数据、各类企业营销素材、各种经营报表和表单等数据,都需要与模型能力有效结合,才可以快速帮助企业快速提升效率,发挥模型价值。
但现有数据平台更加擅长交易数据、用户行为数据等结构化、半结构化数据。面对快速爆发的各种非结构化数据处理需求,缺乏能力储备。
二是多元化数据处理需要强大、异构算力保障,更需要对算力灵活的调度。数据处理特别是离线推理的过程,通常需要CPU+GPU的异构计算,对数据进行分类、标注、元素提取,而GPU价格昂贵且供给紧缺,数据处理过程中需要CPU+GPU紧密联动,提升GPU资源使用效率。
三是数据孤岛问题。由于各种各样的原因,企业数据散落在对象存储、文件存储、数据库和用户本地环境中,由于缺乏有效管理和协调,企业在制定AI战略时,通常会面临数据流通不畅通的情况,不同数据存储格式和不同存储系统等兼容性等问题,也会影响AI落地效果。
最后,还有技术难适配业务发展问题。大模型领域技术迭代快,业务需求不确定性强,行业缺乏成熟数据处理范式,大家都在摸着石头过河。一个新的模型更新速度通常在一个季度或者更短,数据交付周期更在一周以内。传统的数据平台技术已经日益成熟,难以跟上智能时代快速迭的步伐。
我们知道,挑战背后也蕴藏着机遇。在智能涌现的当下,我们同时看到了数据平台演进的新机会。
伴随着大模型能力的不断提升,企业内部同时对于高质量垂直数据集建设诉求将会持续增强。比如医疗领域,准确诊断要求催生了对大量专业病例、高质量影像、基因数据需求。
同时,大模型时代,模型效果与数据息息相关,通过数据飞轮的高速转动,源源不断的为大模型持续注入新的增长动力。我们看到,在电商行业,可以通过大模型实现商品精准推荐,提高转化效率,交易产生的数据又能不断优化推荐模型,循环推动业务高效增长。
过去,以 BI 为核心传统数据平台,大模型时代面临向 AI+BI 双擎驱动升级需求。当梳理清楚这些机遇,就会清晰地看到,此时此刻我们正在参与重塑下一代数据平台的建设过程。
基于此,为了帮助企业更好地拥抱AI时代,我们推出了火山引擎多模态数据解决方案。
作为面向 AI 时代的智能数据基建,它能帮助企业实现对文本、图像、音频、视频等非结构化数据资产的统一精细化管理,兼容多种数据格式,为模型预训练、后训练和智能体开发等场景提供端到端的高效可靠、便捷易用的智能数据服务,帮助企业在AI时代构筑全面领先的数据竞争力。

在多模态数据湖解决方案中,我们打造了4个优势。
首先是高效协同,AI应用落地需要算法团队和数据团队紧密协同,过去算法同学需要消耗大量时间去完成数据准备工作,这对企业来说是一种严重的人力资源浪费。
高效数据平台需要让数据在企业内部各个不同系统之间自由的流动。多模态数据湖解决方案链接了云上的多种基础设施,同时可以和火山近期发布的机器学习平台、以及火山方舟平台,数据上无缝衔接,帮助企业在模型训练、模型蒸馏、模型微调、构建智能体能等多个场景自由流动。
其次是开源,多模态数据湖解决方案主要采用开源技术栈,如新兴Ray、Lance等技术栈,我们围绕这些开源技术提供了企业级能力增强,比如细粒度的数据容错、企业的运维体系、以及灵活的弹性伸缩策略等,用户可以享受到开源软件企业级体验。同时,无需担心云厂商锁定问题。
然后是开放,多模态数据湖方案分为计算、存储、管理、应用等多个层面,层层解耦。用户可以根据自身需求和数据基建设施升级规划和,选择灵活接入,更加易于集成。
最后还有AI赋能,我们融合豆包大模型企业级数据处理算子,比如embedding、文字提取、图片理解等智能化的数据处理算子,大幅提升数据处理效率。

火山引擎多模态数据湖覆盖了湖计算、湖存储、湖管理、湖分析四大模块,覆盖多模态数据建设全链路。
在湖计算层面,EMR容器形态和Serverless形态均支持了GPU+CPU异构计算,通过CPU和GPU资源的灵活调度和配置,可以大幅提升模型训练中GPU资源使用率
在湖存储方向,多模态数据湖解决方案有效整合火山引擎对象存储、文件存储、向量数据湖库、ByteHouse OLAP等多种数据存储方案,并在之上提供lance、iceberg等数据湖存储格式,帮助客户更高效的管理和使用数据
提到湖管理,多模态数据湖解决方案提供了有统一元数据和数据集,针对数据使用情况分析,优化存储介质,使用更有性价比存储产品,同时,多模态数据湖提供了存储诊断、小文件合并、QPS优化等多样化管理工具
而在湖分析方向,ByteHouse多模态数据分析查询和检索能力,还可以帮助客户更高效完成数据采样、分析等工作。

在多模态数据数据湖解决方案之外,今天重磅推出一款新的产品,火山引擎AI数据湖服务(Lake AI Service),简称LAS。
LAS是专门为大模型时代数据湖设计,LAS可以帮助客户实现多模态数据湖管理和存储,它衔接了数据存储和计算引擎。客户可以使用LAS快速构建一个多模态的数据湖。客户需要实现模型蒸馏时,可以在火山方舟中一键开启数据回流,灵活的实现数据处理操作。
以数据预处理过程为例,左图为一个常见的文本数据处理过程,包括对站点筛选、敏感隐私数据过滤、文章段落的全局去重和局部去重、网页标签分类以及数据质量版本控制等10多个环节。
用户在LAS中找到对应的数据处理算子,也可以根据自身业务需要灵活自定义数据处理算子,在LAS中完成数据处理逻辑定义后,可以使用EMR Serverless算力资源完成数据处理动作。如果还需要设置周期性调度,则可以在Dataleap数据开发模块进行配置。
在模型后训练环节,火山方舟和 AI 数据湖服务(LAS)一起打造了低成本、强安全、高效率数据蒸馏解决方案,把模型精调与优化交给平台来做,客户可以更专注于模型落地与业务价值增长上。
方舟与 AI 数据湖服务(LAS)无缝衔接,对于方舟平台上所有模型,均可以一键开启数据回流,通过高效的数据回流与反哺,进一步提升模型推理效果;方舟平台上的客户可以使用这个方案实现模型优化、敏捷迭代,构建更高效的模型应用。总结来说,我们在模型后训练环节,LAS提供了丰富多模态数据处理能力、灵活的数据集管理体系、以及更低成本的数据蒸馏方案。
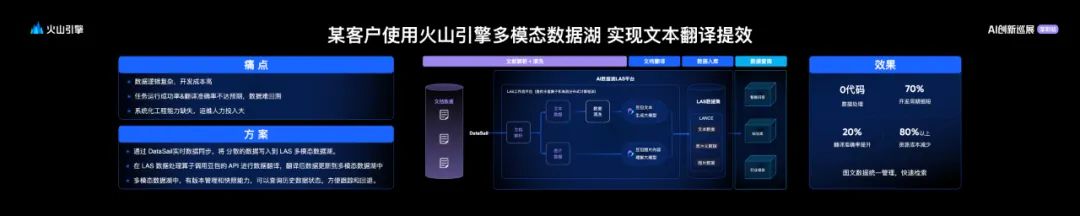
最后,我们再看一个客户案例,用户希望通过豆包大模型对百万文档实现高效翻译。
用户痛点是数据处理逻辑复杂,开发成本高;任务执行成功率和翻译准确率不达预期,数据难以回溯和排查;系统化工程能力缺失,运维资源投入大。
我们通过DataSail实时数据同步,将分散数据集中汇总到 LAS 多模态数据湖,在 LAS 数据处理算子调用豆包API 进行翻译,翻译后数据更新到多模态数据湖中,通过湖管理数据版本管理和快照能力,可以查询历史数据状态,方便跟踪和回退。
该解决方案落地后,企业实现了数据处理过程零代码,开发周期缩70%以上;翻译准确率提升 20%以上,资源成本减少 80%以上;图文数据统一管理,实时性数据问题问题快速检索。
今天我们一起回顾了大模型时代,企业数据平台面临的挑战。在挑战中,我们也同时看到了下一代数据平台升级的机会,这个机会在于对多模态数据价值深入挖掘和提炼,在于和AI能力深度融合。
基于此我们发布了多模态数据湖解决方案,以及新产品AI数据湖服务 LAS;以上只是我们数据智能新基建的开端,让我们在AI时代加速迭代,帮助企业快速智能涌现,谢谢。


 点击阅读原文,申请AI数据湖服务试用
点击阅读原文,申请AI数据湖服务试用