




分享一个很意思的SQL优化案例,字段已有索引,但尝试了多种方法均无法奏效,最终只能通过改写SQL语句来优化查询效率。
1、sql优化背景
2、慢sql和执行时间
select a.col1 as d_id,
a.col2 as s_id,
a.col3 as bm,
a.col4,
a.col5,
(select b.col1 from table2 b where b.col_itname ='zb1'and b.col1 = a.col20) as bb,
a.col6 as dzzlxr,
a.col7 as dzzlxdh,
(select b.col1 from table2 b where b.col_itname ='zb2'and b.col1 = a.col21) as bc,
(select b.col1 from table2 b where b.col_itname ='zb3'and b.col1 = a.col22) as cb,
a.col8,
date_format(a.col9, '%Y-%m-%d %H:%i:%s') as gx,
a.col10 as cid,
a.col11 as tp,
(select b.col5 from table1 b where b.col1 = a.col2) as sj,
(selectcount(*) from table3 dy leftjoin table1 dzz on dy.col1 = dzz.col1 where dzz.col11 like concat(a.col11,'%')) as rc
from table1 a
where1=1
and a.col1 in ( /* 这里 in 了 600 个 字符串条件 */ );
100条执行成功, 执行耗时1分 28秒 248毫秒. 执行号:1432757809
3、慢sql执行计划
1 #NSET2: [1330892675, 12345, 692]
2 #PIPE2: [1330892675, 12345, 692]
3 #PIPE2: [1330892669, 12345, 692]
4 #PIPE2: [1330892663, 12345, 692]
5 #PIPE2: [1330892657, 12345, 692]
6 #PIPE2: [1330892648, 12345, 692]
7 #PRJT2: [4, 12345, 692]; exp_num(17), is_atom(FALSE)
8 #NEST LOOP INDEX JOIN2: [4, 12345, 692]
9 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
10 #BLKUP2: [3, 1, 0]; INDEX33571964(A)
11 #SSEK2: [3, 1, 0]; scan_type(ASC), INDEX33571964(table1 as A), scan_range[DMTEMPVIEW_22201688.colname,DMTEMPVIEW_22201688.colname]
12 #SPL2: [1330892644, 1, 852]; key_num(2), spool_num(4), is_atom(FALSE), has_variable(0)
13 #PRJT2: [1330892644, 1, 852]; exp_num(3), is_atom(FALSE)
14 #HAGR2: [1330892644, 1, 852]; grp_num(1), sfun_num(3); slave_empty(0) keys(A.ROWID)
15 #NEST LOOP LEFT JOIN2: [1327131762, 71772595, 852]; joincondition(DZZ.col11 LIKE exp11) partition_keys_num(0) ret_null(0)
16 #NEST LOOP INDEX JOIN2: [4, 12345, 692]
17 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
18 #BLKUP2: [3, 1, 0]; INDEX33571964(A)
19 #SSEK2: [3, 1, 0]; scan_type(ASC), INDEX33571964(table1 as A), scan_range[DMTEMPVIEW_22201689.colname,DMTEMPVIEW_22201689.colname]
20 #HASH2 INNERJOIN: [26, 116278, 160]; LKEY_UNIQUE KEY_NUM(1); KEY(DZZ.col1=DY.col1) KEY_NULL_EQU(0)
21 #CSCN2: [1, 12345, 104]; INDEX33571530(table1 as DZZ)
22 #SSCN: [13, 116278, 56]; IDX_DYJBXX_ORGID(table3 as DY)
23 #SPL2: [9, 9876, 740]; key_num(2), spool_num(3), is_atom(FALSE), has_variable(0)
24 #PRJT2: [9, 9876, 740]; exp_num(2), is_atom(FALSE)
25 #HASH RIGHT SEMI JOIN2: [9, 9876, 740]; n_keys(1) KEY(DMTEMPVIEW_22201694.colname=A.col1) KEY_NULL_EQU(0)
26 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
27 #HASH2 INNERJOIN: [9, 9876, 740]; LKEY_UNIQUE KEY_NUM(1); KEY(B.col1=A.col2) KEY_NULL_EQU(0)
28 #CSCN2: [1, 12345, 96]; INDEX33571530(table1 as B)
29 #CSCN2: [2, 12345, 644]; INDEX33571530(table1 as A)
30 #SPL2: [5, 11618, 740]; key_num(2), spool_num(2), is_atom(FALSE), has_variable(0)
31 #PRJT2: [5, 11618, 740]; exp_num(2), is_atom(FALSE)
32 #HASH RIGHT SEMI JOIN2: [5, 11618, 740]; n_keys(1) KEY(DMTEMPVIEW_22201695.colname=A.col1) KEY_NULL_EQU(0)
33 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
34 #HASH2 INNERJOIN: [5, 11618, 740]; KEY_NUM(1); KEY(B.col1=A.col22) KEY_NULL_EQU(0)
35 #SSEK2: [1, 120, 96]; scan_type(ASC), INDEX33572004(table2 as B), scan_range[('zb3',min),('zb3',max))
36 #CSCN2: [2, 12345, 644]; INDEX33571530(table1 as A)
37 #SPL2: [5, 11618, 740]; key_num(2), spool_num(1), is_atom(FALSE), has_variable(0)
38 #PRJT2: [5, 11618, 740]; exp_num(2), is_atom(FALSE)
39 #HASH RIGHT SEMI JOIN2: [5, 11618, 740]; n_keys(1) KEY(DMTEMPVIEW_22201696.colname=A.col1) KEY_NULL_EQU(0)
40 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
41 #HASH2 INNERJOIN: [5, 11618, 740]; KEY_NUM(1); KEY(B.col1=A.col21) KEY_NULL_EQU(0)
42 #SSEK2: [1, 120, 96]; scan_type(ASC), INDEX33572004(table2 as B), scan_range[('zb2',min),('zb2',max))
43 #CSCN2: [2, 12345, 644]; INDEX33571530(table1 as A)
44 #SPL2: [5, 11618, 740]; key_num(2), spool_num(0), is_atom(FALSE), has_variable(0)
45 #PRJT2: [5, 11618, 740]; exp_num(2), is_atom(FALSE)
46 #HASH RIGHT SEMI JOIN2: [5, 11618, 740]; n_keys(1) KEY(DMTEMPVIEW_22201697.colname=A.col1) KEY_NULL_EQU(0)
47 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
48 #HASH2 INNERJOIN: [5, 11618, 740]; KEY_NUM(1); KEY(B.col1=A.col20) KEY_NULL_EQU(0)
49 #SSEK2: [1, 120, 96]; scan_type(ASC), INDEX33572004(table2 as B), scan_range[('zb1',min),('zb1',max))
50 #CSCN2: [2, 12345, 644]; INDEX33571530(table1 as A)
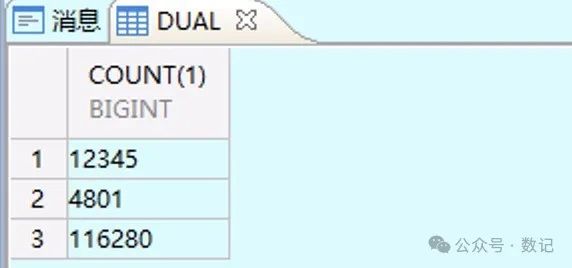
4、涉及表的数据量
select count(1) from table1
union all
select count(1) from table2
union all
select count(1) from table3;
5、分析过程
用瞪眼大法观察,目测是这几段标量子查询导致慢的(啥是瞪眼大法?问就是优化这么多案例的经验)
(select b.col1 from table2 b where b.col_itname = 'zb1' and b.col1 = a.col20) as bb,
(select b.col1 from table2 b where b.col_itname = 'zb2' and b.col1 = a.col21) as bc,
(select b.col1 from table2 b where b.col_itname = 'zb3' and b.col1 = a.col22) as cb,
(select count(*) from table3 dy left join table1 dzz on dy.col1 = dzz.col1 where dzz.col11 like concat(a.col11,'%')) as rc
每段标量子查询测试后,发现是最后一段标量子查询缓慢导致
-- (select b.col1 from table2 b where b.col_itname = 'zb1' and b.col1 = a.col20) as bb,
-- (select b.col1 from table2 b where b.col_itname = 'zb2' and b.col1 = a.col21) as bc,
-- (select b.col1 from table2 b where b.col_itname = 'zb3' and b.col1 = a.col22) as cb,
(select count(*) from table3 dy left join table1 dzz on dy.col1 = dzz.col1 where dzz.col11 like concat(a.col11,'%')) as rc
做了个测试,如果将 like 改成 = 的话,非常快出结果
(select count(*) from table3 dy left join table1 dzz on dy.col1 = dzz.col1 where dzz.col11 = a.col11 ) as rc
dzz.col11 字段是有索引,尝试过各种手段都用不上,只能改写SQL。
6、SQL等价改写
我想法就是将 like 关联这种模糊态查询改成 = 这种确定态的精准匹配逻辑,想了好几个小时都没什么头绪。
后面只能去翻翻落总博客,,还没想到真的给我看到类似的case ,瞬间有了灵感做了下面改写:
select a.col1 as d_id,
a.col2 as s_id,
a.col3 as bm,
a.col4,
a.col5,
(select b.col1 from table2 b where b.col_itname ='zb1'and b.col1 = a.col20) as bb,
a.col6 as dzzlxr,
a.col7 as dzzlxdh,
(select b.col1 from table2 b where b.col_itname ='zb2'and b.col1 = a.col21) as bc,
(select b.col1 from table2 b where b.col_itname ='zb3'and b.col1 = a.col22) as cb,
a.col8,
date_format(a.col9, '%Y-%m-%d %H:%i:%s') as gx,
a.col10 as cid,
a.col11 as tp,
(select b.col5 from table1 b where b.col1 = a.col2) as sj,
b.cnt as rc
from table1 a
LEFTJOIN (
SELECTCOUNT(*) cnt,
dzz.col11
FROM table3 dy
LEFTJOIN table1 dzz
ON dy.col1 = dzz.col1
GROUPBY dzz.col11
) b ON SUBSTR(b.col11, 1, LENGTH(a.col11)) = a.col11
where1=1
and a.col1 in (
-- 这里 in 了 600 个 字符串条件
);
100条执行成功, 执行耗时5秒 326毫秒. 执行号:1435485506
改写完后5秒左右就能出结果了,差集比对后也是等价,呦西。
7、SQL改写后执行计划
1 #NSET2: [524737849, 358862, 740]
2 #PIPE2: [524737849, 358862, 740]
3 #PIPE2: [524737843, 358862, 740]
4 #PIPE2: [524737837, 358862, 740]
5 #PIPE2: [524737831, 358862, 740]
6 #PRJT2: [524737822, 358862, 740]; exp_num(16), is_atom(FALSE)
7 #NEST LOOP LEFT JOIN2: [524737822, 358862, 740]; joincondition(A.col11 = exp11) partition_keys_num(0) ret_null(0)
8 #NEST LOOP INDEX JOIN2: [4, 12345, 692]
9 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
10 #BLKUP2: [3, 1, 0]; INDEX33571964(A)
11 #SSEK2: [3, 1, 0]; scan_type(ASC), INDEX33571964(table1 as A), scan_range[DMTEMPVIEW_22201592.colname,DMTEMPVIEW_22201592.colname]
12 #PRJT2: [33, 1162, 48]; exp_num(2), is_atom(FALSE)
13 #HAGR2: [33, 1162, 48]; grp_num(1), sfun_num(1); slave_empty(0) keys(DZZ.col11)
14 #HASH RIGHT JOIN2: [25, 116278, 48]; key_num(1), ret_null(0), KEY(DZZ.col1=DY.col1)
15 #CSCN2: [1, 12345, 96]; INDEX33571530(table1 as DZZ)
16 #SSCN: [13, 116278, 48]; IDX_DYJBXX_ORGID(table3 as DY)
17 #SPL2: [9, 9876, 740]; key_num(2), spool_num(3), is_atom(FALSE), has_variable(0)
18 #PRJT2: [9, 9876, 740]; exp_num(2), is_atom(FALSE)
19 #HASH RIGHT SEMI JOIN2: [9, 9876, 740]; n_keys(1) KEY(DMTEMPVIEW_22201597.colname=A.col1) KEY_NULL_EQU(0)
20 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
21 #HASH2 INNERJOIN: [9, 9876, 740]; LKEY_UNIQUE KEY_NUM(1); KEY(B.col1=A.col2) KEY_NULL_EQU(0)
22 #CSCN2: [1, 12345, 96]; INDEX33571530(table1 as B)
23 #CSCN2: [2, 12345, 644]; INDEX33571530(table1 as A)
24 #SPL2: [5, 11618, 740]; key_num(2), spool_num(2), is_atom(FALSE), has_variable(0)
25 #PRJT2: [5, 11618, 740]; exp_num(2), is_atom(FALSE)
26 #HASH RIGHT SEMI JOIN2: [5, 11618, 740]; n_keys(1) KEY(DMTEMPVIEW_22201598.colname=A.col1) KEY_NULL_EQU(0)
27 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
28 #HASH2 INNERJOIN: [5, 11618, 740]; KEY_NUM(1); KEY(B.col1=A.col22) KEY_NULL_EQU(0)
29 #SSEK2: [1, 120, 96]; scan_type(ASC), INDEX33572004(table2 as B), scan_range[('zb3',min),('zb3',max))
30 #CSCN2: [2, 12345, 644]; INDEX33571530(table1 as A)
31 #SPL2: [5, 11618, 740]; key_num(2), spool_num(1), is_atom(FALSE), has_variable(0)
32 #PRJT2: [5, 11618, 740]; exp_num(2), is_atom(FALSE)
33 #HASH RIGHT SEMI JOIN2: [5, 11618, 740]; n_keys(1) KEY(DMTEMPVIEW_22201599.colname=A.col1) KEY_NULL_EQU(0)
34 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
35 #HASH2 INNERJOIN: [5, 11618, 740]; KEY_NUM(1); KEY(B.col1=A.col21) KEY_NULL_EQU(0)
36 #SSEK2: [1, 120, 96]; scan_type(ASC), INDEX33572004(table2 as B), scan_range[('zb2',min),('zb2',max))
37 #CSCN2: [2, 12345, 644]; INDEX33571530(table1 as A)
38 #SPL2: [5, 11618, 740]; key_num(2), spool_num(0), is_atom(FALSE), has_variable(0)
39 #PRJT2: [5, 11618, 740]; exp_num(2), is_atom(FALSE)
40 #HASH RIGHT SEMI JOIN2: [5, 11618, 740]; n_keys(1) KEY(DMTEMPVIEW_22201600.colname=A.col1) KEY_NULL_EQU(0)
41 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
42 #HASH2 INNERJOIN: [5, 11618, 740]; KEY_NUM(1); KEY(B.col1=A.col20) KEY_NULL_EQU(0)
43 #SSEK2: [1, 120, 96]; scan_type(ASC), INDEX33572004(table2 as B), scan_range[('zb1',min),('zb1',max))
44 #CSCN2: [2, 12345, 644]; INDEX33571530(table1 as A)
8、 总结
像这种用 like 做关联很明显是业务涉及不规范,不符合三范式要求。
在业务设计初期,尽量满足好三范式设计,后续才能少点用 like 这种模糊态的查询操作。
业务允许的情况下,尽量使用 = 精确匹配来代替like。
往期分享
安装部署
1.分享一个以前搭建主备集群遇到的一个路径乱码案例
2.给大家分享如何标准化部署达梦单机环境
3.DM达梦数据库中大写敏感介绍分享
数据迁移
1.分享工作中数据迁移的实用技巧与方法
2.Oracle迁移DM数据库实践
3.SQLark迁移实践分享(oracle-达梦数据库)
SQL调优
1.DM 传统行业SQL优化案例分享
2.DM数据库SQL优化案例分享
3.如何查询DM 数据库缓存执行计划与清理
4.使用ob_tools包收集分析oceanbase数据库oracle租户缓慢sql语句
5.使用format_obproxy_digest_log工具分析obproxy网络层耗时SQL
6.DM数据库回表优化案例
7.SQL优化案例分享
工具使用与日常处理
1.DataGrip访问国产数据库_datagrip 连接国产数据库
2.如何使用dbeaver连接达梦数据库
3.更新大字段提示-2201无效的对象问题
4.DM7读写分离部署问题总结
5.DM7读写分离集群备库数据不同步问题处理
6.达梦数据库DISQL工具部署及使用技巧
7.达梦数据库日常巡检方法分享
8.如何查询达梦数据库缓存执行计划与清理
9.达梦数据库运维工具分享
10.东方通中间件环境中如何部署达梦企业管理工具(DEM)
