




大家好,我是猫头虎!今天我要和大家分享一下OpenAI最新发布的旗舰模型——GPT-4o的各种新特性。这款全新的“omni”模型不仅能处理文本,还能理解和生成音频、图像和视频,让我们一起来看看它有哪些令人激动的新功能吧!✨
1. 多模态输入输出
文本、音频、图像和视频全能选手
GPT-4o可以同时处理和生成文本、音频、图像和视频内容。这意味着你不仅可以用文字和它交流,还可以让它识别和生成图像、听懂和回复你的语音,甚至处理视频内容。这个特性让GPT-4o成为了一个真正的多模态AI。
实际应用案例
视觉识别:GPT-4o可以识别复杂的视觉内容,帮助进行图像分类、物体检测等任务。 音频处理:它能够处理多重语音输入,进行语音识别和生成。 视频分析:GPT-4o可以理解和分析视频内容,进行视频摘要和标注。
2. 超快响应速度
闪电般的速度
GPT-4o的响应速度极快,最短仅需232毫秒,平均为320毫秒,几乎达到了人类在对话中的反应时间。这使得与GPT-4o的互动更加流畅和即时,让用户体验更上一层楼。
实际应用场景
实时对话:在聊天机器人应用中,GPT-4o可以快速响应用户的每一个问题,让对话更自然。 实时翻译:GPT-4o可以在对话中即时翻译多种语言,提高跨语言沟通的效率。
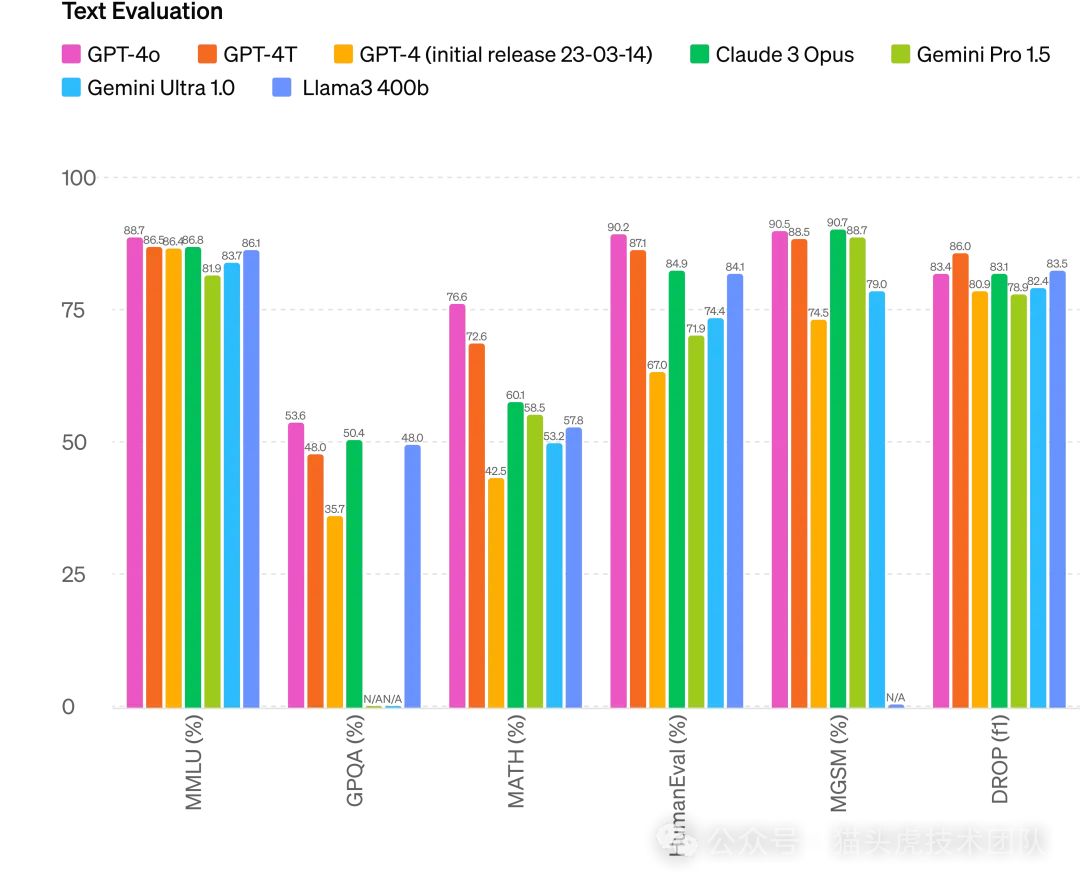
3. 多语言处理能力
强大的语言处理能力
GPT-4o在处理英语和编程语言的文本方面表现与GPT-4 Turbo相当,但在处理非英语语言文本时有显著提升。新的语言标记算法让GPT-4o在多语言环境下更为高效和准确。
支持的语言
GPT-4o支持多达20种语言,并能有效减少标记数量,提高处理效率。例如,在处理中文、日语和韩语等语言时,GPT-4o能显著减少标记数量,从而提高处理速度和准确性。
4. 成本与效率优化
更高的性价比
GPT-4o在API使用上比GPT-4 Turbo便宜了50%,并且速度提升了2倍。这意味着开发者和企业能够以更低的成本享受到更优质的AI服务,特别是在大规模应用中,更高的效率和更低的成本让GPT-4o更具竞争力。
应用场景
大规模文本生成:新闻机构和内容创作公司可以以更低的成本生成大量优质内容。 实时数据分析:企业可以利用GPT-4o进行实时数据分析,提高决策效率。
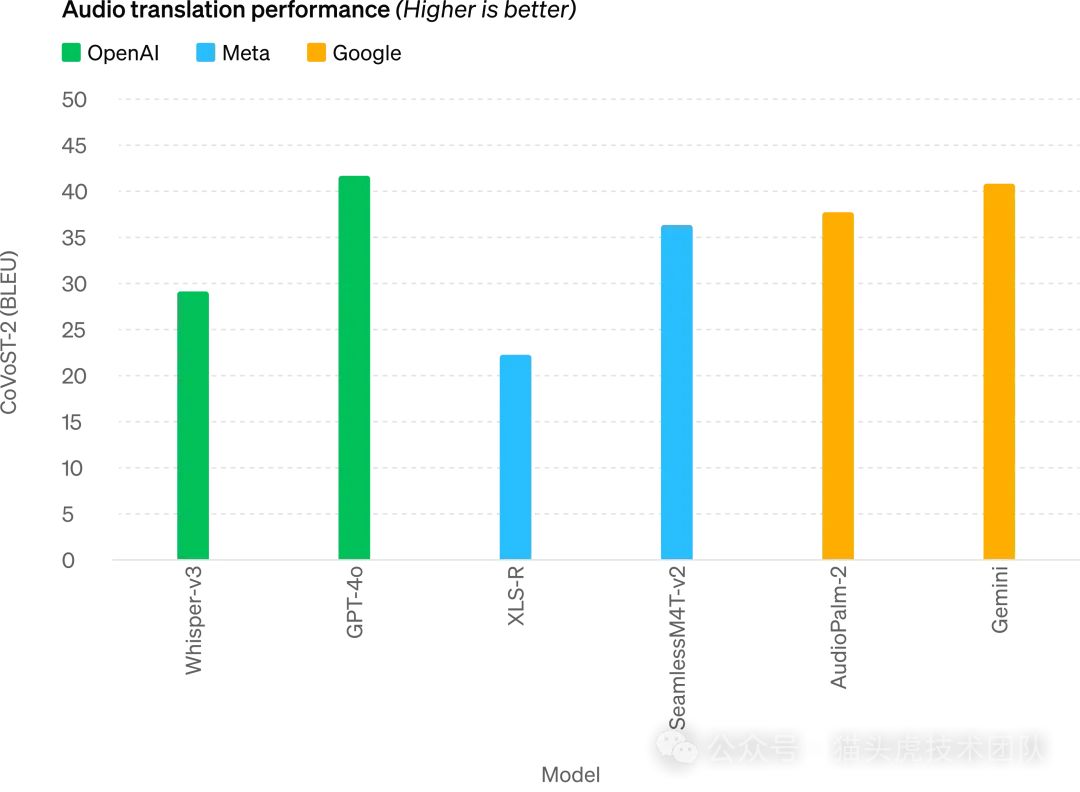
5. 视觉与音频处理
视觉处理能力
GPT-4o在视觉感知和理解方面表现出色,能够处理复杂的视觉任务,如图像分类、物体检测、场景理解等。
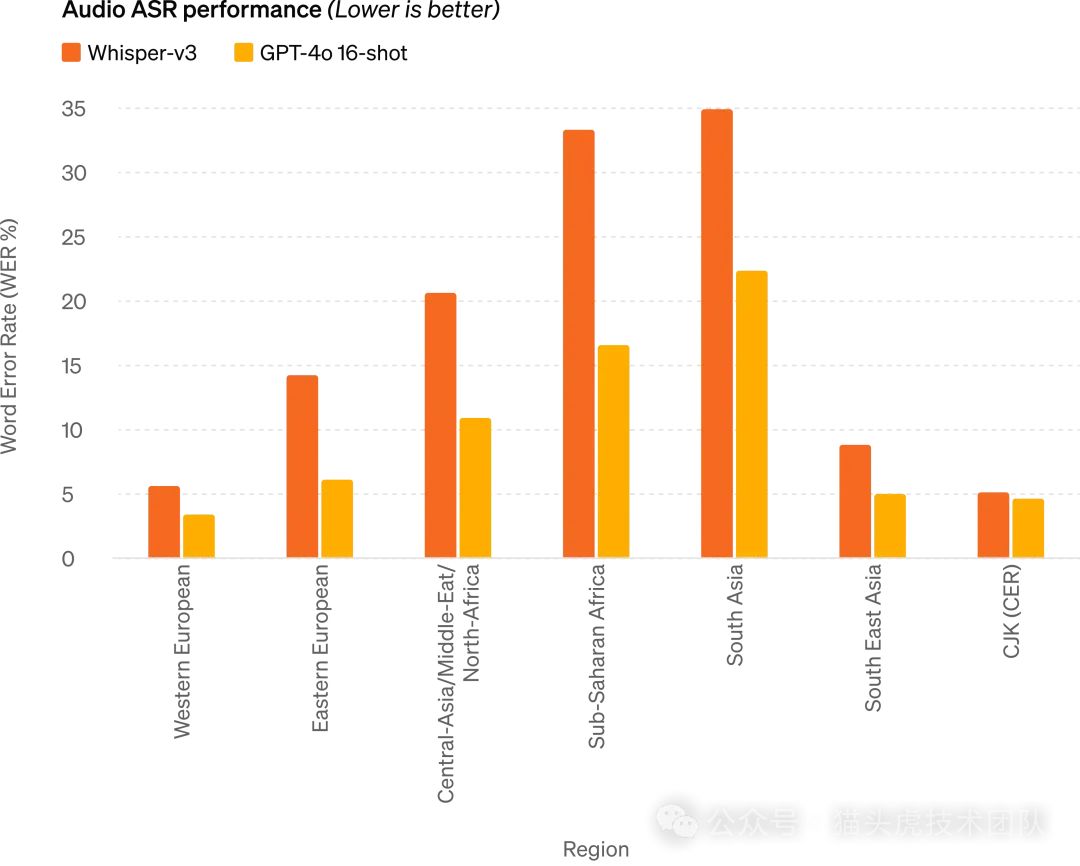
音频处理能力
GPT-4o显著提升了对各种语言的语音识别能力,尤其是对资源较少的语言表现出色。它还能进行高质量的音频生成,甚至能够在对话中处理多重语音输入和背景噪音。
6. 安全性与限制
内置安全性
GPT-4o在设计时就考虑到了跨多模态的安全性,通过过滤训练数据和优化模型行为,确保安全输出。它还接受了70多位外部专家的广泛测试,以识别新增多模态可能引入或放大的风险。
持续改进
虽然GPT-4o已经展示出强大的功能,但OpenAI将继续对其进行优化和改进,解决可能存在的安全性问题和技术限制。
结语
GPT-4o凭借其多模态处理能力、超快响应速度、强大的多语言处理能力、更高的性价比以及卓越的视觉和音频处理能力,成为了AI领域的又一大突破。如果你对这些新特性感兴趣,欢迎关注我,扫码下方二维码加入我们的讨论群,与更多AI爱好者一起交流探讨!
期待你的加入!👇

