排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
12
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
首页
/
好久没分析Oracle数据库性能问题了,今天聊几毛钱的
好久没分析Oracle数据库性能问题了,今天聊几毛钱的
白鳝的洞穴
2025-04-25
756
其实目前让我干起来最舒服的活还是帮用户分析复杂的性能问题,利用二十年前掌握的技能,以及这些年积累的经验来做事情是轻车熟路的,除了费点脑子,其他啥都不费。原本我也以为以这个作为职业干到退休就算了,没想到这些年有如此的变化,与运维知识自动化纠缠了七年。
最近一个客户的系统经常出现性能问题,轻则卡顿,最严重的一次还引发了业务熔断。这套系统最近做了一次机房搬迁,换了一个国产存储。刚开始那次业务熔断与多种因素有关,其中很重要的原因是更换的存储虽然是全闪高端存储,但是IO延时不如原来的老存储,经过一系列的优化后,改善了不少。不过从AWR报告上来看,目前的一小时平均IO延时与搬迁前还是略差一些。最终确定是因为新存储在架构上存在问题,因此在超高负载下,对于超低延时的需求适配能力存在缺陷,已经无法进一步优化了。可能对于大多数用户,大多数业务系统来说,这种情况根本就遇不到,不过对于一些极端应用场景,遇到了就很难解决。
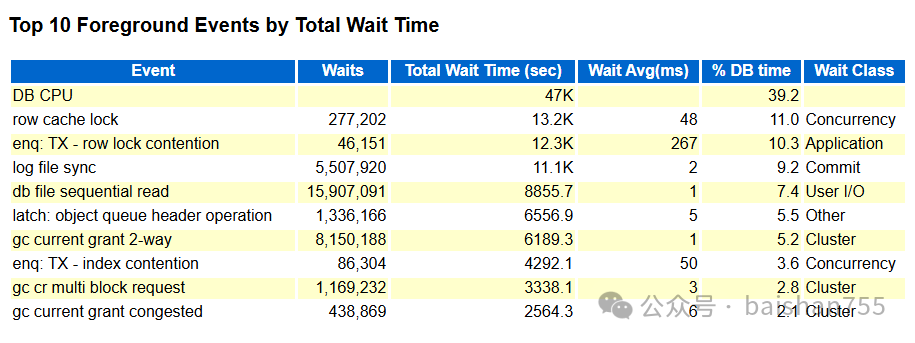
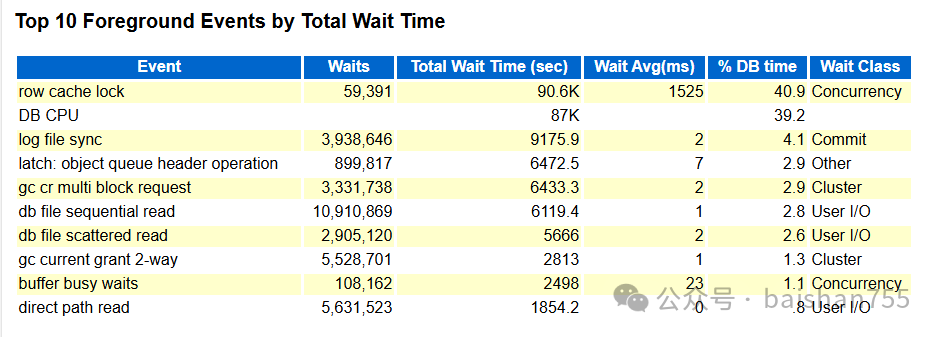
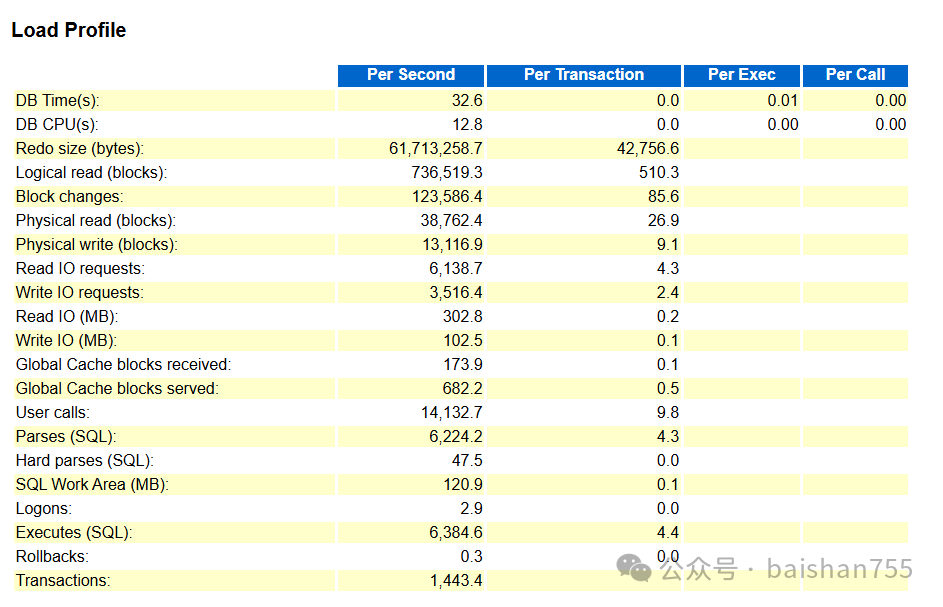
从这份凌晨0:45到1点多钟AWR报告上其实看不出什么特殊之处(这个时间段业务出现了比较严重的卡顿),可能很多朋友会有不同意见,这么多的row cache lock,行锁,日志同步的等待事件出现在AWR里,怎么能说没问题呢?这是因为最近这个系统的AWR报告看得多了,正常的,非正常的,搬迁前的搬迁后的,已经烂熟于心了。这些等待事件没啥问题的搬迁前就一直存在,而且状态比这个报告上严重得多,但是业务也没有出现明显卡顿,下面是一个没有问题时候的AWR报告截图。
业务卡顿主要是出现在几个几个并发量超高的业务,其他业务是正常的。从总体上看,数据库还是能够正常工作的。因此这种情况看AWR报告是不够用的。对于超高并发的系统,有一个重要的要看的是操作系统的系统调用争用你,一般来说用perf这样的工具去分析是十分必要的。
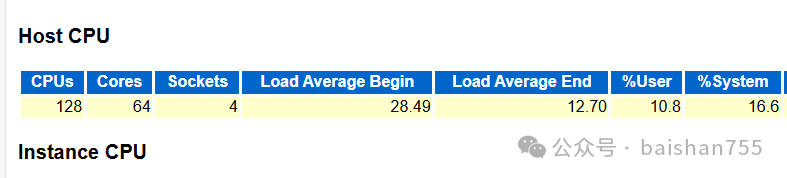
从HOST CPU状态来看,SYS占了16.6%,系统中肯定存在一些因高并发引发的争用。不过这套7*24的系统上并没有安装perf工具,他们的合规控制也不允许在系统非检修时间安装perf工具。对管控比较严格的用户来说,为了今后诊断故障方便,在安装时候一定要把perf这样的常用工具装上,否则今后除了停业检修这样几年遇不到一次的机会外,就很难做这个事情了。虽然你告诉客户这个绝无风险,在严格的合规性管控下,甲方DBA绝对不敢做这种事情,因为一旦出问题,就是丢工作。
这种情况下,看AWR,找出有问题的SQL都没太大的用处了。必须通过ASH做微观分析才能找到问题的根本点。在无法通过perf去看系统并发争用根因的前提下,只能退而求其次,找出rowcache lock的问题根源,并且寻找相关的解决方案。
在ASHDUMP数据中,没有看到明显的阻塞,只是看到LCK0存在row cache process的情况。这个只能证明出现阻塞的时候,存在RAC全局的阻塞,高并发解析等因素引发了这个问题。大多数等待rowcache lock的都是简单的单条insert语句。
参考负载文件的数据可以看出,解析十分高,不过硬解析还算可以。遇到这种问题是比较难找到根因的,对于这种超高并发超低延时的系统,大多数必须从应用层去优化,不过对于金融核心系统而言,应用层优化需要的时间比较长,因此目前只能先找到一种应急方案,让系统能够挺过这段时间,再慢慢优化。
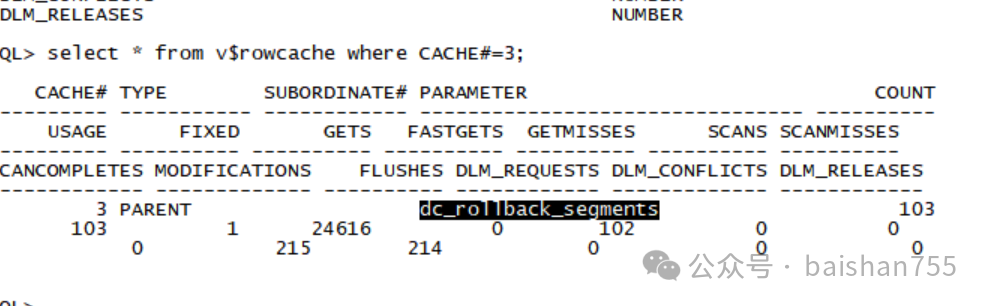
遇到row cache lock,又找不到阻塞源头的情况,一般而言,有一个小技巧,就是通过参数1去看等待的是哪个类型的row cache。
一查吓了一跳,居然是dc_rollback_segments,难道是系统中存在大事务失败回滚?仔细一问,原来他们有一个批处理业务,也属于交易的一部分,设置了十分钟超时退出,在故障期间这个业务超时中断比较严重。经过分析,他们会把超时设置到30分钟,从而减少回滚。
除了row cache的问题外,行锁问题也十分严重,通过AWR报告,可以看出itl等待、索引叶节点、枝节点分裂也很严重。这些表还都没做成分区表,在高并发写入下,出现因为索引引发的冲突也就很正常了。不过优化这些业务没那么简单,需要应用部门做详细的评估,因此目前最简单的处置方法就是定期对这些索引做REBUILD,并且在做REBUILD的时候加大PCTFREE和INITRANS参数。
高并发执行对于本系统来说是最致命的问题,如果业务并发进一步增加,这个问题还将更严重。不巧的是系统安装的时候session_cached_cursors这样对高并发执行性能有所改善的参数并没有调整,还是默认的50,而且这个参数是需要重启数据库的,因此暂时还无法优化。因此只能先做这么多了。
完成上述的一些小调整后,这两天系统运行还算平稳,没有出现严重的卡顿。不过这个系统是处在比较严重的亚健康状态下的。这些问题在以前IO性能十分好的情况下是不会引发大问题的,而现在IO性能出现了轻微的下降,就十分容易出问题了。在国外,这样的系统一般会选择购买Oracle一体机,在一体机这样稳定强大的IO支撑下,会跑得更加顺畅。不过未来两年这套系统也要迁移到国产软硬件平台上了,采购一体机是想都不用想的事情了。我也十分担心,今后的国产软硬件上,这个系统是否能够跑得很好。
也许我的担忧是多虑了,因为上国产软硬件,一方面硬件投资肯定要高不少,另外就是应用优化也会做得比较到位,现在的系统连个分区表都没做,今后估计横向纵向分拆是必然要做的事情。拆小后,这些问题可能都会迎刃而解了。前阵子我聊了聊分布式数据库是不是伪命题这个话题,有朋友就举例说,所有的分布式数据库问题都可以通过应用改造来变成N多个集中式数据库就能跑的。我回答说,你说得对,这个话题再往下谈,那么数据库也是个伪命题了,不就是个存数据,直接写文件不也一样能实现。
数据库系统
oracle
数据库性能
perf
文章转载自
白鳝的洞穴
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨