




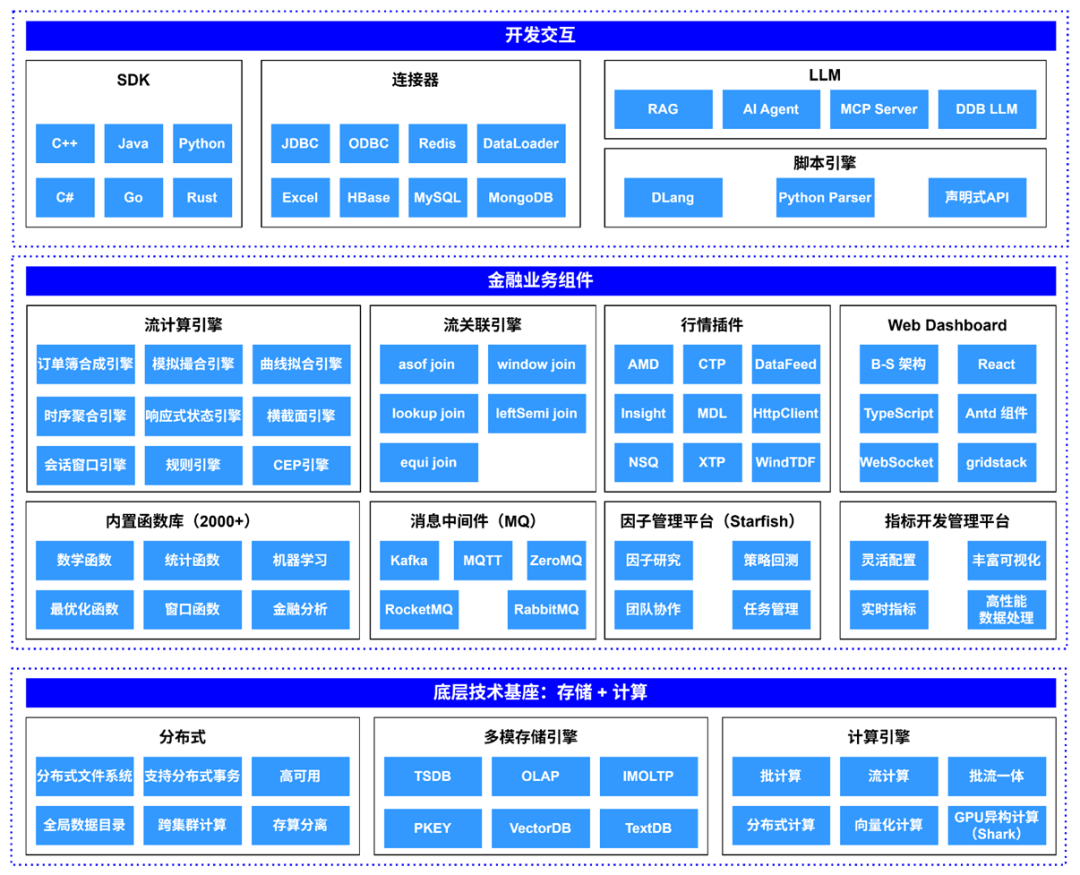
4月22日下午,DolphinDB 在深圳举办 D-Day 行业交流会。来自券商、公募、私募等机构的二十余位量化专家齐聚一堂,围绕企业级实时计算平台与 AI 技术在量化行业中的应用与价值展开深入探讨。
会上,DolphinDB 创始人兼 CEO 周小华博士重点分享了团队最新研发成果——企业级实时计算平台 Orca 的核心能力和行业价值。他指出,金融量化行业对企业级实时计算平台的强烈需求,既源于行情中心、因子计算、IBOR 统一资产管理等复杂业务场景,也来自跨部门协作中数据割裂、管理分散所带来的挑战。Orca 作为 DolphinDB 打造的企业级实时计算平台,不仅具备强大的实时数据注入、存储、查询与计算能力,还提供数据一致性保障、存算分离架构、多集群统一管理等关键特性,全面赋能机构构建高效、稳定、可扩展的数据基础设施。



为何需要企业级实时计算平台?
在金融量化领域,对于企业级实时计算平台的需求既源于业务场景的复杂性,也与管理层面系统协同的挑战密切相关。
从业务视角看,无论是行情中心构建、因子计算与发布,还是实时/准实时风控、基于 IBOR(Investment Book of Record,投资账簿记录)的统一资产管理,这些核心场景都需要依赖系统对海量数据的实时响应能力。以 IBOR 为例,其本质是打破传统 T+1 核算模式,要求系统在数秒内同步全球市场的交易流水、持仓变动及清算结果,并基于此动态计算资产净值、风险敞口和合规指标。这对系统提出了低延时注入、实时查询、高效实时计算和低延时输出的全链路性能诉求。
从管理视角看,金融机构普遍面临系统碎片化与数据孤岛的治理难题。不同部门如投研、交易与风控往往采用独立的技术栈,导致开发标准不统一、协作效率低下。机构也缺乏统一的实时数据中心,数据分散在多个系统中,无法实现全局关联分析。而且,更全面的风控依赖于头寸、交易等数据的实时更新,而系统割裂所造成的数据延迟,可能会严重影响风控系统的准确性与时效性。
因此,机构需要一个能够打破数据壁垒、整合多业务场景,同时提供毫秒级实时计算能力的平台化工具。
而 Orca,则正是这样一款面向企业级需求的实时计算平台。
Orca 实时数据处理能力
Orca 源于 DolphinDB,在实时数据处理方面具备极为出色的能力。
在实时数据注入方面,Orca 提供多种高效且低延迟的方式:支持毫秒级延迟的 SDK 接入、百微秒级的行情插件接入,以及延迟低至单微秒的 Swordfish 嵌入式版本,全面覆盖不同场景下的实时数据注入需求。
g = createStreamGraph("factor")baseStream = g.source("snapshot", 1024:0, inputSchemaDef.name, inputSchemaDef.typeString).reactiveStateEngine(factors0, `code).fork(2)oneMinStream = baseStream[0].parallelize(`code, parallelism).dailyTimeSeriesEngine(60000, 60000, factors1, sessionBegin, sessionEnd, `timestamp, false, `code).reactiveStateEngine(factors2, `code).sync().crossSectionalEngine(factors3, `code, 'keyCount', keyCount, false, `timestamp, true).sink("one_min_factors").map(msg -> select *, now() from unpivot(msg, `timestamp`code, msg.columnNames()[2:])).sink("dfs://factor/one_min")fiveMinStream = baseStream[1].parallelize(`code, parallelism).dailyTimeSeriesEngine(5*60000, 5*60000, factors1, sessionBegin, sessionEnd, `timestamp, false, `code).reactiveStateEngine(factors2, `code).sync().crossSectionalEngine(factors3, `code, 'keyCount', keyCount, false, `timestamp, true).sink("five_min_factors").map(msg -> select *, now() from unpivot(msg, `timestamp`code, msg.columnNames()[2:])).sink("dfs://factor/five_min")
Orca 企业级解决方案
在企业级数据管理方面,Orca 提供了完善的能力支持,包括数据一致性保障、存算分离架构、计算任务依赖调度机制以及多集群统一管理等关键功能,助力企业构建高效、稳定、可扩展的数据基础设施。
通过异步复制和流数据跨集群订阅机制,Orca 能够确保各个集群间的数据一致性。同时,Orca 还采用了统一的命名规范,方便用户管理和查询数据,降低数据管理的复杂性。
在 Orca 平台上,用户可以根据需求自行配置存储和计算资源,将存储和计算资源分开管理,提高系统的可扩展性和可靠性。此外,Orca 还支持计算依赖调度功能,通过声明式 API、运维监控和血缘管理等功能实现计算任务的自动化调度和管理。
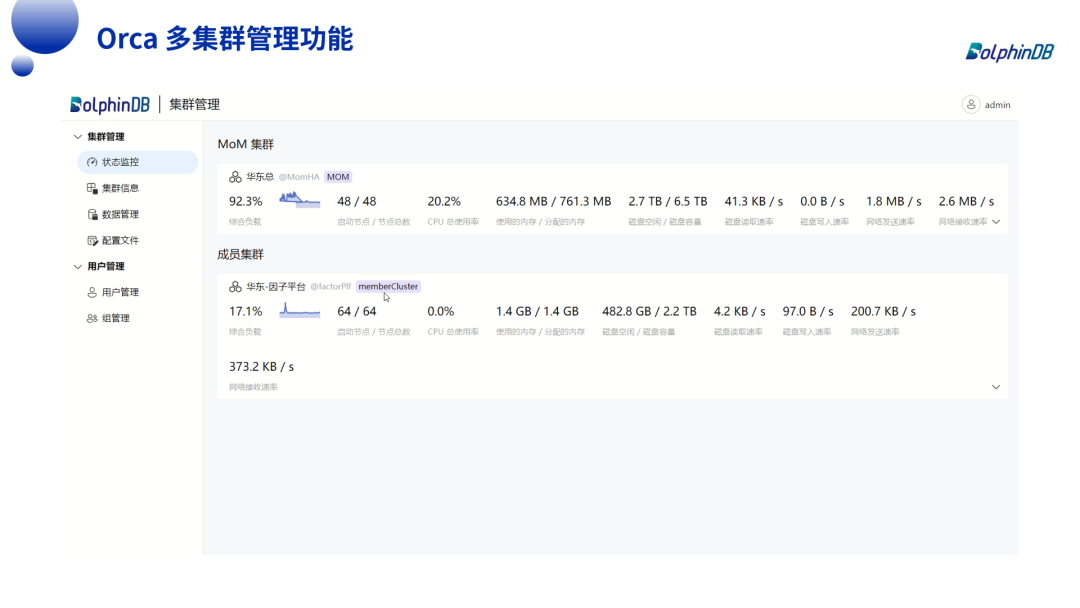
通过多集群管理功能,用户可以直观地了解各个集群的运行状态和资源使用情况,及时发现并解决问题,提高系统管理的效率和可靠性。
Orca 平台未来展望
D-Day 期待您的加入
D-Day 是由 DolphinDB 发起的行业交流系列活动,旨在为用户们提供一个专业、开放的交流机会与平台,方便大家深入探讨在量化交易中如何有效提升综合投研效率,以技术融入业务,创造应用价值。
DolphinDB 将不定期在北京、上海、广州、深圳等地举办 D-Day 线下活动,如果您有参与 D-Day、联合举办技术研讨会、行业闭门会等合作意向,欢迎通过小助手与我们联系(dolphindb1)!

