





大模型的训练和推理任务,本质就是海量数据处理的过程。强大的算力集群,不仅需要高性能的 AI 加速卡和高性能的 RDMA 网络,还离不开高性能存储系统的支持。
当前,在大模型训练任务的数据读取、Checkpoint 加载,推理任务的快速分发和镜像加载等场景,数据的大小少则几十 GiB,多则几百 TiB 甚至至多达到数 PiB。存储速度越快,算力空闲时间越短。这需要一套能够支持大规模算力集群、海量数据场景的高性能存储加速系统。
RapidFS 是一款近计算存储加速工具。依托对象存储 BOS 作为数据湖存储底座,构建容量与性能解耦、冷热分层、透明流转的高性能存储方案。以 POSIX 挂载和 HDFS 协议,为上层计算应用提供统一文件访问入口,加速 AI 训练与推理、海量数据处理与分析、数据分发等业务场景下的存储访问。
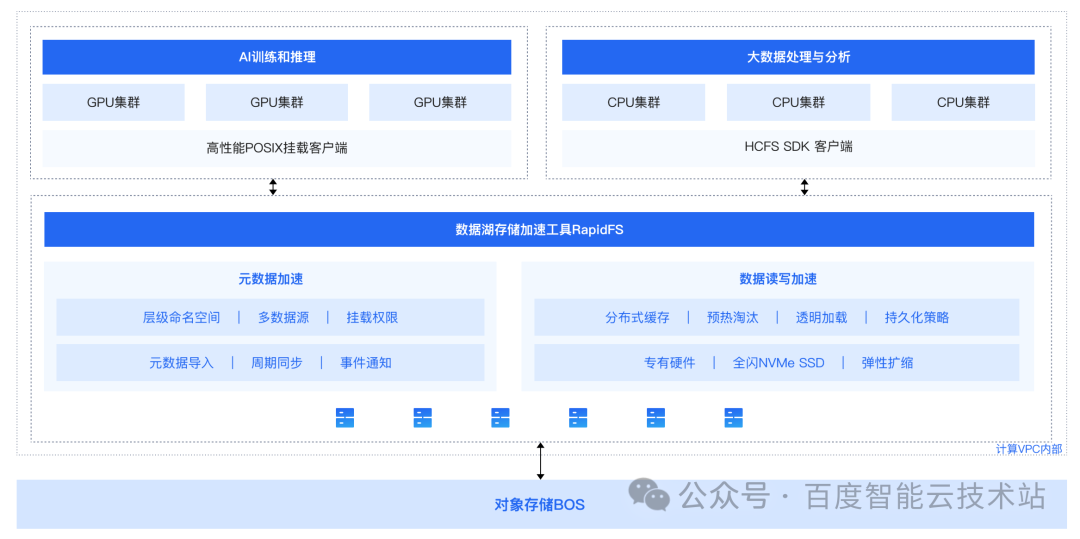
4. 性能测试详细说明
4.1. 服务器配置

4.2. 测试规模
我们分别对 20 个存储节点和 70 个存储节点规模的 RapidFS 集群进行了性能测试。
4.3. 测试方法
按照 DeepSeek V3 模型文件构造 160 个 4.3 GiB 文件,总计 688 GiB。将这些文件导入对象存储 BOS 并加载至 RapidFS 存储加速集群中。每个计算节点开启 8 进程从 RapidFS 存储加速集群中读取模型文件,持续压测 600 秒。
4.4. 测试结果
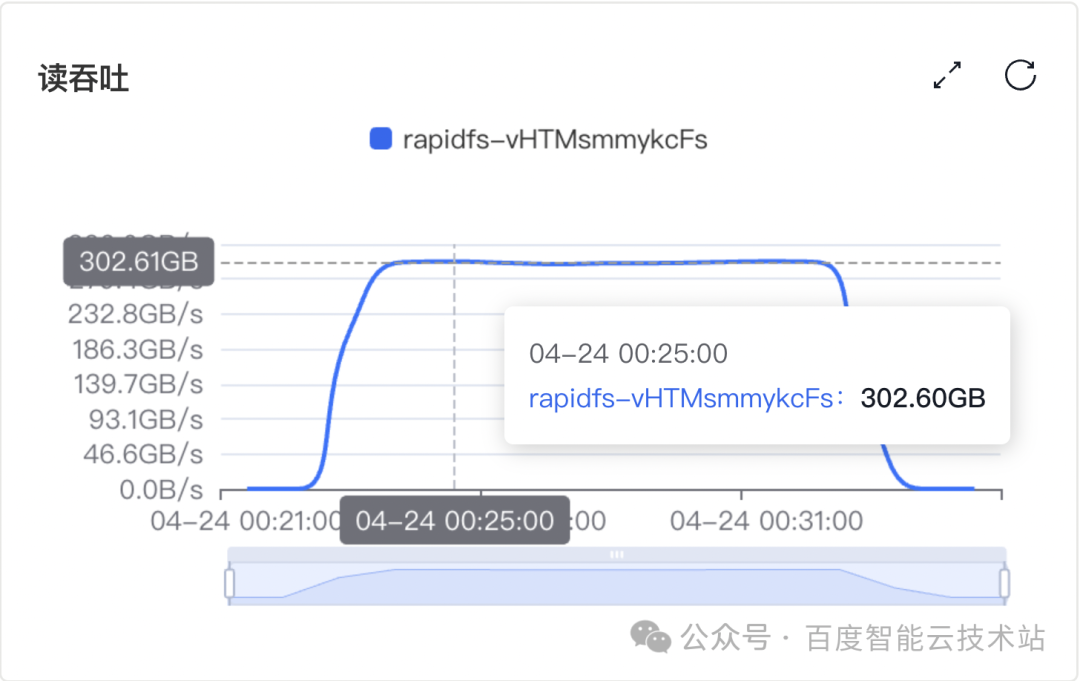
测试集群 A:20 个 RapidFS 存储节点
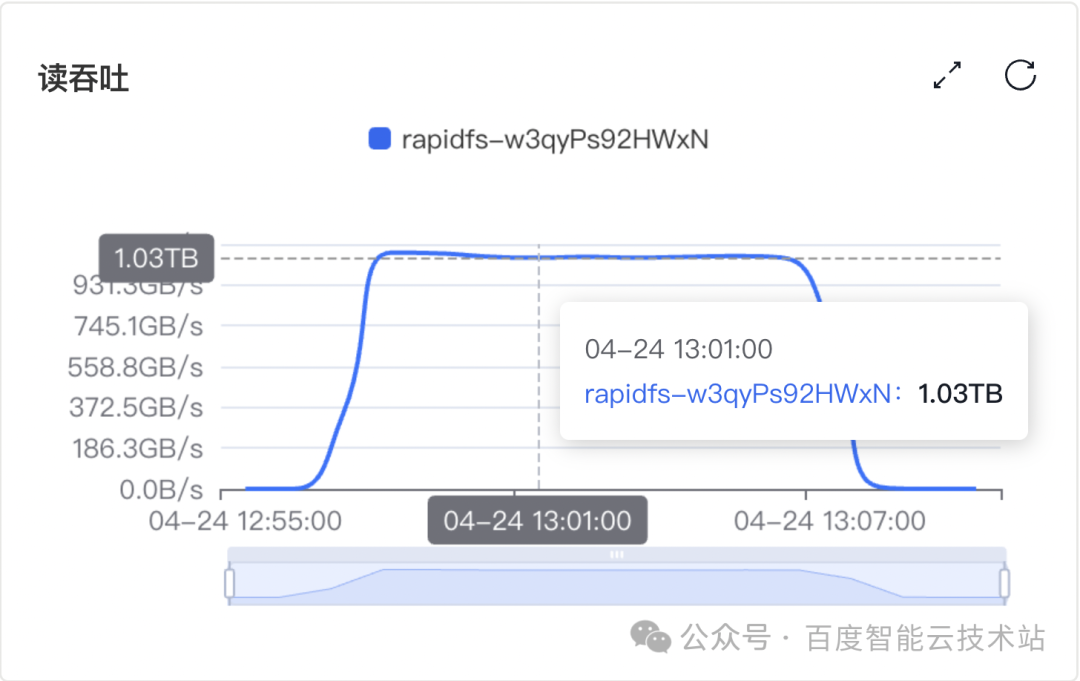
测试集群 B:70 个 RapidFS 存储节点
- - - - - - - - - - END - - - - - - - - - -
点击阅读原文
了解数据湖存储加速工具 RapidFS 更多信息
文章转载自百度智能云技术站,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
