




本文对华东师范大学周傲英、钱卫宁院长团队和中兴通讯中心研究院副院长屠要峰等人共同编写的2024 VLDB论文《Fast Commitment for Geo-Distributed Transactions via Decentralized Co-coordinators》进行解读,全文共7817字,预计阅读需要15至25分钟。
在地理分布式数据库中,数据分片及其副本被部署于跨多个地区的数据中心,从而实现跨区域容灾能力,并可就近为全球用户提供服务。然而,地理分布式事务的处理过程中,尤其是在提交阶段,往往需要多轮跨区域通信,严重影响系统性能。为优化地理分布式事务的执行性能,本文提出了一种新型事务提交协议:去中心化两阶段提交(Decentralized Two-Phase Commit, D2PC),旨在最小化跨区域通信的负面影响。D2PC引入了多个协同协调器(co-coordinators),它们以并行方式进行提交协调。每个协同协调器负责在本地收集2PC投票,并做出PreCommit(预提交)决策。此外,D2PC引入了“绕过主节点的副本应答机制”,通过协同协调器直接传递消息,绕开主节点,进一步降低了提交延迟。该机制使得多个跨区域网络往返可以并发执行,并且每个区域在副本同步完成之前即可结束本地并发控制,从而显著降低阻塞概率,提高系统并发性。
1.1地理分布式数据库的兴起
地理分布式数据库已成为支持跨区域应用(如国际银行、电商平台、社交网络等)不可或缺的基础设施。一些典型的数据库系统如Spanner与CockroachDB,通过将数据划分为多个分片并将其副本部署于全球多个数据中心,以实现容灾与本地访问能力。
然而,这些数据库的核心竞争力在于其处理跨区域分布式事务的能力。为了保障事务的原子性,通常需采用如“两阶段提交(2PC)”等原子提交协议;同时,为了确保高可用性,应使用共识协议来保持跨区域数据副本之间的一致性。但这些协议均涉及多轮跨区域通信,每轮都可能引入耗时数百微秒的延迟。这种延迟不仅阻止关键应用程序满足其所需的服务水平协议(SLA),还会增加锁持有时间、加剧冲突,严重制约整体系统性能。因此,降低跨区域通信对分布式事务处理的负面影响,是提升系统实用性的关键。
1.2现阶段地理分布式数据库的局限性
在大多数现有系统中,事务层(负责提交协议)通常建立在复制层(负责共识协议)之上。例如,Spanner使用2PC协议叠加于Multi-Paxos协议上。缺点是由于分片的主节点可能分别位于不同区域,提交事务需要多轮跨区域通信,常常导致上层应用不得不放弃使用分布式事务,以换取更可控的性能。
近期已有多项研究尝试将共识协议与提交协议深度集成,以减少提交所需的网络往返次数。这些方法在无冲突场景中,可实现一次网络通信即完成提交,大幅降低延迟。但在存在冲突的场景中,它们仍需至少两轮通信,并在并发控制期间引发大量跨区域交互,导致冲突处理成本依旧高昂。同时,它们要求所有副本共同参与事务处理,这与现有数据库依赖主节点的架构存在根本冲突。
1.3提出D2PC的动机
为了解决上述地理分布式数据库的缺陷,本文提出D2PC协议,针对现有“分层架构”进行优化,旨在提升并发处理能力,并降低延迟。其主要思想是:在提交阶段,将协调任务分散至多个数据中心,由本地服务器与就近的“协同协调器”通信,避免跨区域协调瓶颈。
D2PC的设计核心如下:
在每个数据中心部署一个协同协调器,分别收集本地参与者分片的投票并作出PreCommit决策;
每个协同协调器在完成PreCommit后,即可通知本地主节点结束并发控制;
提交阶段时,协同协调器可直接将副本应答信息传送至主协调器,绕过分片主节点,减少一轮通信延迟。
最终,D2PC能够将提交延迟降低至1~1.5个跨区域往返时间RTT(Round Trip Time),显著优于现有协议。
2.1去中心化提交与过程解耦
在传统2PC协议中,协调器的位置严重影响并发控制周期的长度。尤其当协调器与参与者主节点位于不同区域时,跨数据中心通信会引入高延迟,导致参与者需要等待协调器较长时间才能结束并发控制。为缓解这一问题,D2PC提出从“单一协调器”转向去中心化的协调模式,在每个数据中心部署一个协同协调器(co-coordinator),从而实现本地化的协调。协调器在达成提交决策前有如下两个重要任务:
2PC投票收集:协调器需从所有参与者收集投票;
日志复制:所有参与主节点需复制事务日志。
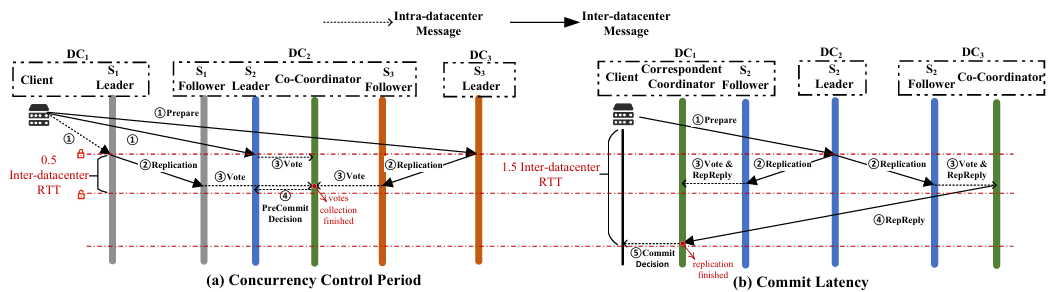
D2PC中缩短并发控制周期和减少提交延迟的示例
2PC投票收集和日志复制是两个相互独立的过程,D2PC的关键思想是解耦并且并行执行投票收集与复制流程:
当参与主节点收到Prepare消息后,立即向其他参与者(副本)复制事务日志和投票消息;
其他副本(也就是本地主节点外的其他收到副本的参与者)收到消息后将投票发给本地协同协调器;
协同协调器收集本地副本投票后,即可提前做出PreCommit决策并通知本地参与主节点;
本地主节点因此无需等待复制完成即可结束并发控制周期。
2.2绕过主节点的副本应答
类比“无主节点复制”方法,D2PC借助协同协调器实现了绕过主节点的副本回复机制,从而进一步降低提交延迟。具体流程如下:
每个本地副本将投票和复制应答一并发送给本地协同协调器;
本地协调器再将此复制应答直接转发给客户端所在数据中心的协调器(即主协调器);
该机制绕过了本地主节点,节省了一次跨数据中心消息跳转。
该机制被称为D2PC的快速路径(Fast Path),同时保留了传统路径(Slow Path)以提升容错能力。
2.3事务状态转移
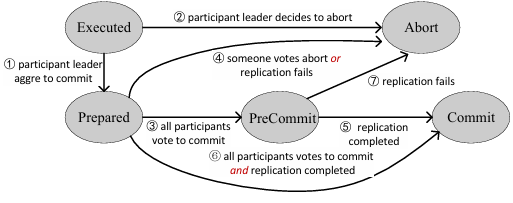
事务状态转换图
如图展示了事务在D2PC协议中的状态转移流程。与传统2PC相比,D2PC引入了一个新的状态:PreCommit。其中状态转移逻辑如下:
当本地协同协调器收集到本地副本的投票后,事务进入PreCommit状态;
当主协调器从各参与分片的多数副本中接收到复制应答后,事务进入Commit状态;
若某个分片的多数副本复制失败,即便事务已进入PreCommit,也必须中止(Abort)。
2.4系统架构
(1)系统部署:此地理分布式数据库系统部署于多个地理区域的数据中心,每个分片有2F+1个副本分布于不同区域。
(本地)协同协调器(Co-coordinator):在每个数据中心部署,负责本地PreCommit决策;
主协调器(Correspondent Coordinator):位于客户端同一数据中心,是唯一有权做出最终提交决策的节点;
协同协调器之间相互协作以确保提交结果具有容错性。
(2)客户端库:客户端作为数据库用户的执行单元,接口如下:Begin()用于创建事务对象,Read(tid, key)用于读取键值和版本号,Write(tid, key, val)写入键值,Commit(tid)用于提交事务,返回提交或者中止状态。

D2PC的各接口
(3)数据存储层:每个本地分片副本存储键值对,并实现并发控制:
Prepare(tid, rset, wset):验证事务是否可提交;
PreCommit(tid):在本地接收到PreCommit后结束并发控制;
Commit(tid) / Abort(tid):根据主协调器最终决策执行提交或中止。
本地副本间的通信、事务控制与决策均可独立完成,极大提升并行度与可扩展性。
3.1 D2PC 的提交过程
当客户端发起新事务时,首先会执行事务逻辑,生成读集与写集作为D2PC协议的输入。在执行阶段:读操作通过调用Read(tid, key)函数完成,默认由分片主节点提供服务,以获取最新版本的值;写操作是指将产生的新值加入到本地缓存中的写集;执行完毕后,客户端调用Commit(tid),事务进入D2PC的PreCommit阶段。PreCommit阶段流程如下:
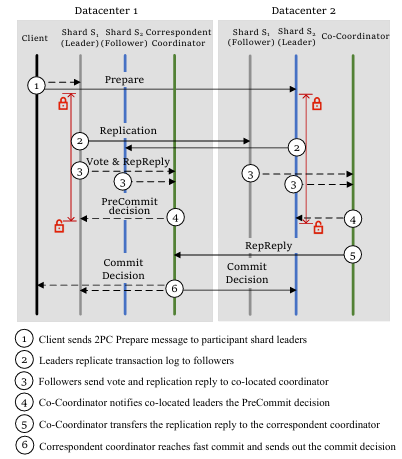
PreCommit阶段流程
1.客户端调用Commit后,向所有参与分片的本地主节点发送Prepare请求(流程①);
2.主节点验证事务是否可提交,若通过则标记为Prepared,并生成包含事务ID、读写集的日志;
3.日志连同投票结果被复制至所有本地副本,包括主节点本身(流程②);
4.每个本地副本接收到复制消息后,将投票与复制确认信息发给本地协同协调器(流程③);
5.本地协同协调器收集到足够副本投票后做出PreCommit决策(流程④);
6.本地协同协调器再将复制确认信息转发至客户端所在区域的主协调器(流程⑤);
7.主协调器收集各分片大多数副本的复制确认后做出最终提交决定(流程⑥)。
此流程同时支持“快速路径”与“慢速路径”,后者兼容传统分层架构,以增强系统的容错性
提交延迟分析:事务提交过程从客户端发送Prepare消息开始,并在接收到来自主协调器的通知时结束。
主协调器必须满足两个条件才能做出提交决策:1)必须接收所有参与分片的投票;2)必须接收每个分片的大多数副本的复制回复。由于本地副本到其本地协同协调器的消息是数据中心内的,因此数据中心间通信总共需要1.5轮,因此,总的提交等待时间是1.5个数据中心间RTT。
3.2通过协同协调器实现去中心化提交
D2PC中要求每个协同协调器在本地收集分片副本投票,并可独立做出以下PreCommit决策:
若有任一本地副本投票为Abort,则中止事务;
否则事务被标记为 PreCommit 并立即通知本地主节点;
由于每个协同协调器仅基于本地副本投票做决策,保证PreCommit的一致性。
在D2PC中,并发控制周期的定义为:开始于主节点收到Prepare消息,结束于收到协同协调器发来的PreCommit决策。在默认部署中,涉及一次跨数据中心消息往返,因此并发控制周期仅为0.5 RTT。事务提交后,为确保提交决策的容错性,主协调器会将该决策复制至多数协同协调器,实现“非阻塞恢复”。
3.3依赖关系跟踪
由于D2PC在PreCommit阶段提前结束并发控制,因此需维护依赖关系以确保可串行性与可恢复性。D2PC为每个元组引入了一个PreCommit列表,可以有效地识别和管理写后读(wr)依赖关系,即读取尚未提交事务写入内容的事务。读取操作若命中该列表,则记录wr依赖,并更新当前事务的in和被依赖事务的out列表;当PreCommit的事务最终提交,其out中事务的in计数减一;若中止,则依赖者in设为-1。

D2PC对wr依赖关系的全流程管理
对于算法中对wr依赖关系的全流程管理,有两项规则:
若事务in>0,即存在未提交依赖,则不可提交;
若in=-1,则必须中止。
3.4故障与恢复
(1)主协调器故障:
若主协调器在决策发送后失效:选择一名本地协同协调器作为主协调器,并通过让本地协同协调器确定是否收到了启动恢复阶段的决策。在收到回复后,该决策将被接受并通知给各分片主节点和其他本地协同协调器;
若主协调器在决策发送前失效:新的主协调器启动终止协议,与所有主节点通信,重新做出提交/中止决策;
(2)协同协调器故障:
本地主节点未收到PreCommit,但最终仍可从主协调器获得最终决策;
若超过F个本地协同协调器故障,主协调器无法通过快速路径获得所有副本回复,但可退回慢速路径,确保事务正常提交。因此,协同协调器的故障不会妨碍事务的成功提交。
(3)参与者副本故障:只要主协调器能从F+1个副本中收集到投票与复制确认,仍可做出决策;否则需等待新主节点选出后继续执行。
3.5读取优化
默认情况下,读取操作服务由主节点提供,确保数据新鲜。但在地理分布式场景下,远程访问主节点代价昂贵,因此D2PC提供本地读取优化策略:客户端可直接读取本地副本,减少跨区域通信;为确保一致性,在提交阶段引入读版本验证:
在准备(Prepare)阶段附带读数据集及其版本;
主节点收到后验证版本新鲜性,若读到旧版本,则中止事务。
D2PC的读取优化策略在提升性能同时保持一致性,特别适用于OCC,2PL协议也可通过策略调整兼容性。
3.6集成至分层数据库
由于D2PC仅对地理分布式数据库中的提交过程进行了极小的改动,因此很容易集成进当前主流的分层架构系统中。D2PC可以在提交过程中使用慢速路径,但是也提出了快速路径作为改进,此改动仅涉及数据中心内的消息通信(intra-datacenter message),没有跨区域开销。因此,D2PC集成进现有系统时,无需大改原有提交协议,每台数据库服务器仅承担极小的额外通信负担。此外,为了配合并发控制周期的缩短,底层数据存储模块应支持追踪写后读(wr)依赖关系。这一设计允许分片主节点提前终结并发控制周期,从而提升整体系统并发度。
4.1实验设置
(1)测试环境:所有实验在阿里云部署的ECS实例上进行,跨5个数据中心分布。默认情况下采用3-副本部署,分别位于杭州、旧金山和法兰克福;在5-副本部署中,额外引入北京和弗吉尼亚。每台服务器配备4核CPU与8GB内存,共部署3个分片(shard),每个分片包含3–5个副本。在每个数据中心中,服务器充当为本地协同协调器。
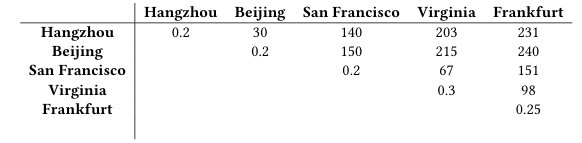
五个数据中心之间的网络延迟(ms)
(2)对比方案:
比较D2PC结合两种基于2PC的机制(2PL与 OCC):D2PC+2PL、D2PC+OCC。
比较D2PC+2PL和标准事务协议(Spanner:2PC+2PL);
比较D2PC+OCC和2PC+OCC,作为Spanner变种;
比较D2PC+OCC和Carousel,一种协同设计设置。
评估读取优化的效果:2PC+2PL-NRO和D2PC+2PL-NRO
(3)工作负载:使用了两个工作负载进行评估:第一个是Retwis应用程序的合成工作负载,它模拟了Twitter的功能。Retwis工作负载包含四种类型的事务,每个事务平均访问2-3个分片中的4-10个数据项。第二个工作负载是YCSB+T,它是YCSB的扩展,支持事务性。
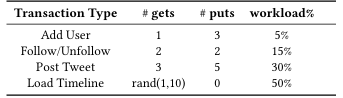
Retwis的工作负载
4.2不同负载下的性能表现
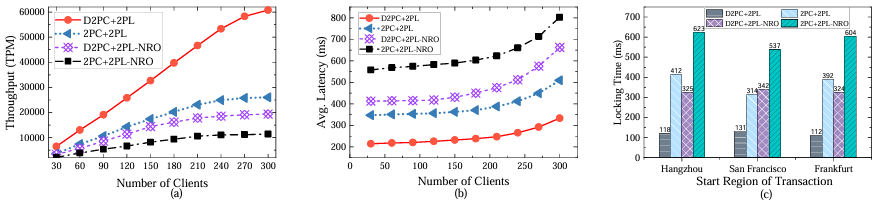
在2PL下各基线的结果

在OOC下各基线的结果
实验采用Zipf系数为0.7的中等冲突度对Retwis负载进行评估。实验表明,在2PL下,关闭读取优化时,D2PC+2PL-NRO相比2PC+2PL-NRO吞吐量提升1.73倍,延迟降低25%,并发控制周期缩短44%;开启读取优化后,两者性能显著提升,D2PC+2PL相比2PC+2PL提升更大:吞吐量提升2.33倍、延迟降低42%、锁持有时间减少66%;
另一方面,在OCC下,D2PC+OCC相比其他方案也展现出显著性能优势,如在300个客户端下提交延迟约为250ms,较2PC+OCC降低约43%,并发周期减少64%,吞吐量达其2.43倍。同时,当负载较低时,D2PC+OCC和Caribbean的延迟相当。随着客户端数量的增加,冲突的可能性增加。在这种情况下,Caribbean的快速提交路径失败,并切换到慢路径。随着并发的增加,D2PC+OCC在事务延迟方面优于Caribbean。在并发控制周期长度方面,D2PC+OCC展示了比Caribbean显著的优势。在300个客户端下,D2PC+OCC的吞吐量比Caribbean高47%,延迟降低23%,并发控制周期缩短46%,同时,并发控制周期短,冲突少,中止率降低34%。
4.3 5-副本部署下的性能表现

在OOC下5-副本部署的结果
实验表明在所有5-副本数据中心部署中,尽管副本数增加,但D2PC+OCC表现依旧优异:首先,D2PC+OCC的并发控制周期进一步缩短,吞吐量是Carousel的1.29倍,是2PC+OCC的2.2倍。尽管此时D2PC提交延迟略升,但仍低于2PC+OCC,且在高并发(超过240客户端)下D2PC的中止率与延迟更低;相较而言,Carousel在高并发下需要额外通信来解决冲突,导致性能下降更明显。
4.4冲突负载下的性能表现
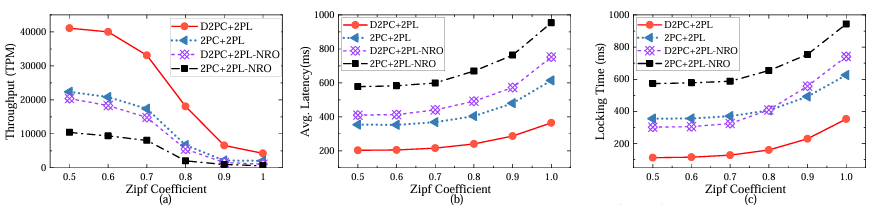
在2PL下对于冲突负载的结果

在OOC下对于冲突负载的结果
实验中通过调整Zipf系数模拟冲突程度,固定客户端数为150。结果表明,无论使用2PL或OCC,随着冲突增大,所有方案吞吐量均下降,但是D2PC在高冲突负载下吞吐量始终优于Carousel和2PC+OCC,无论是否开启读取优化操作。在2PL下D2PC+2PL的吞吐量最高可以是2PC+2PL的3.06倍,即使没有进行读取优化,D2PC的吞吐量也可以达到2PC的1.8倍。
4.5协同协调器的容错性与可扩展性
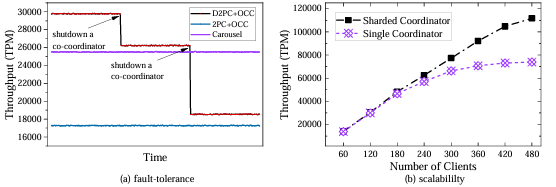
协同协调器的容错性与可扩展性结果
(1)容错性评估:首先实验人为关闭两个协同协调器后,部分事务无法进入PreCommit,导致了D2PC吞吐量下降。当仅剩一个协同协调器时,D2PC将退化为2PC+OCC,其性能略逊于Carousel;然而,即使只剩一个协同协调器,D2PC的参与者主节点可本地完成并发控制,性能仍优于2PC+OCC。
(2)扩展性评估:实验进一步评估了主协调器分片策略在提高可扩展性方面的效果,采用的工作负载为Retwis,Zipf系数为0.7。为了模拟性能限制,限制D2PC每个协同协调器资源(1核CPU + 512MB内存),之后使用分片策略,将负载均摊至多个协同协调器组(如每个数据中心配置N个)。实验结果表明,D2PC吞吐量随并发客户端数增长而线性提升,展现出D2PC良好可扩展性。
4.6提交延迟与并发控制周期时长的详细分析
在该实验中设置工作负载为YCSB+T负载A(50%写,50%读)。具有3-副本部署,150个客户端,Zipf系数为0.,7并使用OCC作为并发控制协议。
实验中定义了三种网络延迟:
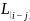 :数据中心
:数据中心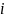 与
与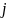 之间的 RTT;
之间的 RTT;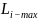 :接收所有其他数据中心回复所需最大延迟;
:接收所有其他数据中心回复所需最大延迟;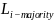 :接收多数数据中心回复所需延迟。
:接收多数数据中心回复所需延迟。
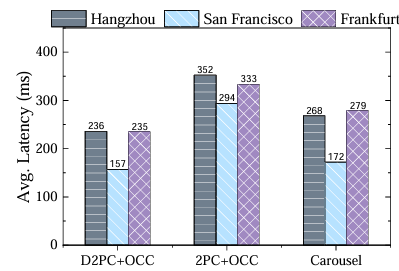
提交延迟比较
(1)提交延迟比较:结果由决定,实验结果显示,D2PC与Carousel提交延迟均被优化较好;而2PC+OCC的延迟更高,主要是受制于复制确认过程;同时,不同发起中心的事务延迟有所不同(如杭州为230ms,旧金山为140ms)。
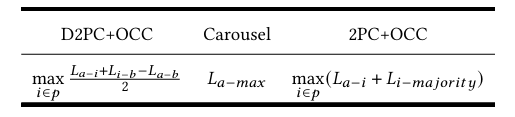
分片主节点的并发控制周期长度
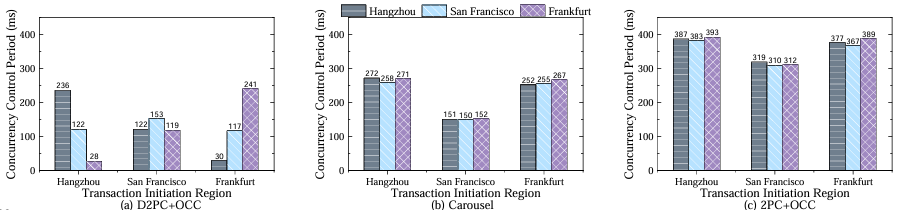
并发控制周期长度的比较
(2)并发控制周期比较:表格概述了不同方法的并发控制周期长度。
实验假设事务在数据中心a发起,并分析数据中心b的分片主节点的并发控制周期长度。理论上,Carbide和2PC+OCC的并发控制周期长度与它们的提交延迟相对应,它们的并发控制周期长度分别为1个数据中心间RTT和2个数据中心间RTT,而D2PC为0.5 RTT。
实验结果也证明了这一点,D2PC的并发控制周期长度根据位置而变化,但是D2PC的总体并发控制周期长度仍然显著低于其他方法。这是因为D2PC凭借更短周期,有效减少冲突,提升吞吐量。
5.1两阶段提交与阻塞问题
在分布式数据库系统(DDBMS)中,数据通常被划分为多个分片,以实现系统的可扩展性。然而,当事务跨越多个分片时,就需要一个原子提交协议来确保原子性,即令所有涉及的服务器在提交决策上达成一致。两阶段提交协议(2PC)是许多分布式数据库系统中广泛使用的方案。它包含两个阶段:准备阶段和提交阶段。
准备阶段(Prepare Phase):各参与者向协调器发送投票(提交或中止);
提交阶段(Commit Phase):协调器在收到所有“提交”投票后决定提交,否则中止。
但2PC存在严重的阻塞问题,因为协调器是唯一能做出最终提交决策的节点,一旦协调器在发送决定之前宕机,参与者将被“挂起”,无法释放事务资源(比如锁),导致系统停滞。
为解决该问题,已有诸多变种协议被提出:
三阶段提交(3PC):引入“准备提交”阶段,参与者在最终提交前就已知决策,提升了容错性;
增强三阶段提交(E3PC):使用法定数机制进一步增强可靠性;
Paxos Commit:结合Paxos协议将提交决策复制到多个副本中;
Easy Commit:参与者将协调器决策转发至其他参与者,提升健壮性;
Cornus:面向分离存储架构的一阶段提交协议,具有存储高可用的假设。
这些协议通过不同方式提升容错能力,避免因协调器故障而阻塞提交。本论文中的D2PC同样致力于解决阻塞问题,但以更简洁且兼容现有架构的方式实现。
5.2地理分布式数据库中的事务提交
地理分布式数据库将分片副本部署在多个数据中心,以提高容灾能力和访问就近性。事务提交过程因此不可避免地跨越区域网络,带来显著通信开销。当前主流的地理分布式数据库系统多采用分层架构,比如Spanner使用Multi-Paxos支持复制层,并在其之上运行2PC:
上层为事务协调层,使用如2PC的原子提交协议;
下层为复制层,使用Paxos或Raft实现副本一致性。
该架构与主从分片配合良好,但问题在于:一旦协调器与分片主节点不处于同一区域,事务提交就需要额外的跨区域通信,显著增加了事务提交延迟。为此,一些研究提出了协同设计(co-design)的理念,尝试融合提交协议与复制协议,比如MDCC,TAPIR,Janus等。这些方案在无冲突情况下效果显著,但在冲突场景中,仍需额外通信,或强制中止冲突事务。更重要的是,这些方案往往要求所有副本参与事务处理,与主从架构天然不兼容,部署代价较高。相比之下,D2PC旨在兼容现有主从架构,同时大幅减少提交阶段的跨区域通信。
5.3写可见性
除了提交延迟延长并发控制周期外,另一个造成并发控制周期过长的重要原因是:写操作的可见性被延迟,以保证事务的可恢复性。设想一个事务T1写入数据x,随后事务T2读取T1的写入。如果系统允许T2提交在T1之前,就可能出现T1的失败,因为这种调度违反了读后写依赖的提交顺序。
因此,大多数并发控制机制选择:直到事务提交后,写操作才能对外可见。虽然能确保可恢复性,但也延长了并发控制周期。近年来,一些研究提出了提前写可见性(Early Write Visibility):
(1)基于锁机制的协议:
ELR(Early Lock Release):事务执行完即可释放锁,延迟日志持久化;
CLV(Commit Logic Validation):重设计锁表以记录事务依赖关系并强制执行依赖事务的提交顺序;
Bamboo:进一步打破 2PL,在执行期间释放锁以提升并发性。
(2)基于非锁机制的协议:
PWV:用于确定性数据库,事务执行顺序被允许提前确定;
Hekaton:提出多版本并发控制(MVCC)中,允许读取“准备提交”状态下的数据。
但在地理分布式事务场景中,提前写可见性的研究仍非常稀缺。
D2PC提利用各数据中心的“协同协调器”来实现提前写可见性,能同时缩短并发控制周期与提交延迟,并兼容2PL与OCC。
本文提出了一种在地理分布式数据库中的事务提交协议D2PC,该协议的主要目标是最小化跨区域通信对系统实时性和提交延迟的影响。D2PC通过协同协调器实现分布式提交,并将2PC和复制过程并行化。与基于2PC的提交方法相比,D2PC的提交方法具有更高的效率和更好的性能。D2PC在吞吐量和延迟方面表现出显著的性能改进。此外,与实现快速提交的无主节点提交方法相比,D2PC实现了提交延迟减少,同时也提供了更高的吞吐量提高。
论文解读联系人:
刘思源
13691032906(微信同号)
liusiyuan@caict.ac.cn





