




本文对北京理工大学王国仁教授、袁野教授团队等人共同编写的2024 VLDB论文《An Experimental Evaluation of Anomaly Detection in Time Series》进行解读,全文共8098字,预计阅读需要15至25分钟。
在统计学与计算机科学领域,时序数据中的异常检测已被研究了数十年,涵盖如欺诈检测、环境监测、工业制造、医疗健康等多种应用场景。虽然当前已有众多算法针对不同场景提出,但由于缺乏统一测试环境、标准化数据集和评价指标,导致用户在实际应用中难以选择合适的方法。作者从“数据维度”、“处理方式”和“异常类型”三大核心特征出发,构建了一套系统的分类体系,并在该体系下将17种最先进的算法划分为六个子类。实验中在真实与合成数据集上使用点异常评估指标(point metric)与针对子序列异常设计的子序列(范围)指标(range metric),对算法进行系统性地类内比较(intra-class)与类间比较(inter-class)。从效果、效率与鲁棒性多个维度出发,分析了这些算法在异常比例、数据规模、维度数量、异常模式与阈值设置等条件下的表现。最后,作者基于不同的使用场景对这些算法进行深入分析,并提出一套面向实际应用的异常检测算法选择指南。
1.1时序数据异常检测的发展
时间序列数据是近几十年来最常用的数据类型之一。时序数据分析旨在通过数据分析方法,以获得有价值的见解。时序中的异常检测是指去发现与大多数数据显著偏离的罕见观察结果,是时序数据分析(挖掘)中最重要的部分。时序数据异常检测已经在各种应用中对其进行了研究,例如欺诈检测、环境监测警报和工业制造、网络攻击识别等。
1.2系统性地评估时序数据异常检测方法的动机
尽管异常检测方法众多,但由于缺乏统一的测试环境和评价指标,现有研究很难帮助用户准确选择合适的算法来处理真实场景中的异常,主要原因有以下三点:
时序数据的复杂性与多样性:数据可能是单维或多维,异常类型也多种多样,现有方法往往只针对特定场景。例如,某些方法只能处理单维数据点异常,另一些只能识别固定长度的模式异常。
评估缺乏统一标准:不同研究使用不同指标,甚至对同一指标(如F1分数)采用不同计算方式,导致比较结果不一致。不同实现语言和结构也会影响性能。
指标与方法不匹配问题:许多研究在子序列异常数据集上采用点评估指标,并通过“point-adjust”策略来修改预测结果,但是实验中应该同时考虑效率和性能之间的权衡来分析这些措施的效果。
为了解决上述挑战,本文首先根据时序数据异常检测的三个方面和六个子类的基本特征,提出了一种对于检测方法的分类。之后,根据上述分类简要介绍了17种最先进的方法,并使用JAVA重新实现了其中的10种方法,使用相同的代码结构重构了所有方法,并构建了一个测试框架以避免潜在的影响。
实验中,为了进行公平的性能比较(针对第二点挑战),应该在同一测试环境中的同一类的方法之间进行系统的实验,这也被称为类内比较。包括以下几个方面:基于点和范围的指标的有效性、异常率、数据大小(可扩展性)、维度、异常模式。
同时(针对第三点挑战),实验中应该考虑在同一维度的类之间的比较,也称之为类间比较。最后从实际应用的角度来说,异常检测算法的还包括阈值设置方面的鲁棒性,本文分析了不同应用情况下方法的性能,对这些算法行为的分析将对用户有所帮助。
2.1问题定义
时序数据中的异常检测定义如下:
定义2.1(时序数据):时序数据是一组按时间顺序排列的数据点。设时序数据为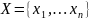 ,其中第
,其中第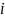 个观测值
个观测值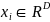 为
为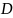 维向量,记录于时间戳
维向量,记录于时间戳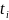 。子序列
。子序列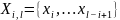 表示从第个时间点开始,长度为
表示从第个时间点开始,长度为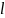 的一段连续时序数据。
的一段连续时序数据。
定义2.2(时序数据中的异常检测):异常是指那些与数据中大多数观测值显著不一致的观测点(或子集)。在时序数据中,异常检测的任务是识别数据点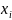 或子序列
或子序列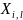 是否异常。
是否异常。
2.2分析维度
异常检测方法可以从不同角度进行分类。本文提出的分析框架包括以下三个维度:数据维度、处理方式和异常类型,在每个维度下进一步划分为多个子类别。
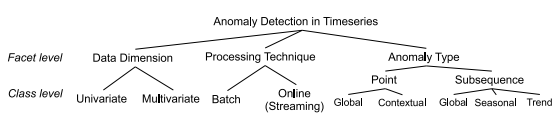
时序数据中异常检测算法的方面和子类别
2.2.1数据维度
数据维度描述了算法能够同时处理的变量数量。若序列为单维,即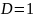 ,则为单维时序数据;若
,则为单维时序数据;若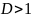 ,则为多维时序数据。
,则为多维时序数据。
高维数据场景:多维方法能利用维度间的相关性,从而提升检测准确率。但相较之下,单维方法因可在每个维度上并行处理,具有效率优势。实验表明,在处理51维的Swat数据集时,单维方法IDK耗时16.50秒,而多维方法PBAD耗时125.17秒,约为前者的10倍。此外,在高维数据中,LSTM等模型的性能也会显著下降。因此,评估在多维数据中使用单维模型的可行性尤为重要。
2.2.2处理方式
若时序数据为无限长(流式数据),则需使用实时检测方法;若数据集为有限集,则可使用批处理方法。实时检测方法最常采用滑动窗口技术。
大规模数据场景:批处理方法可一次性分析所有数据,因而精度更高;而实时检测方法处理实时数据流,速度更快。特别是在数据维度高、数据规模大的场景下(如维度>50,数据点>100k),效率与效果的权衡尤为关键。因此,探讨实时检测方法是否能在保证效率的同时,接近批处理方法的检测效果这个问题也是极其重要的。
2.2.3异常类型
在时序数据中,明显偏离常规的单个数据点被称为点异常(Point Anomaly),而相较于其他部分显著不同的连续子序列称为子序列异常(Subsequence Anomaly)。为了准确比较不同方法,实验中需要根据不同的异常类型采用匹配的评价指标,否则易产生误导性结论。
(1)点异常类型:分为全局异常和上下文异常。
全局异常(Global):若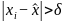 ,其中
,其中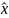 为整体期望,
为整体期望,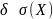 ,则该数据点被判定为异常。
,则该数据点被判定为异常。
上下文异常(Contextual):若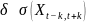 ,即某点与其邻域均值显著偏离,则该数据点被判定上下文异常。
,即某点与其邻域均值显著偏离,则该数据点被判定上下文异常。
(2)子序列异常类型:分为形状异常、季节性异常和趋势异常。
形状异常:若子序列基本形态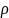 与参考形状之间的相似度
与参考形状之间的相似度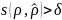 ,则该子序列点被判定为形状异常。
,则该子序列点被判定为形状异常。
季节性异常:若周期/重复模式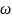 显著不同。
显著不同。
趋势异常:若趋势变化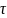 导致整体均值发生永久偏移,则该子序列点被判定趋势异常。
导致整体均值发生永久偏移,则该子序列点被判定趋势异常。
参数不确定性场景:大多数子序列检测算法要求用户提供目标异常子序列的长度,这是一个难以事先得知的参数。相比之下,点异常方法无需该参数(子序列长度为1)。因此需要关注以下两个问题:
点异常检测算法在子序列异常中是否依然有效?
是否有检测算法能同时应对上述不同异常模式?
根据前文提出的分类体系,作者选择了每个子类中具有代表性的最新方法,按照“检测技术类型”(即距离、模式、深度学习)分类简要介绍这些方法,并提取它们的关键参数。表格中列出了每个算法的基本属性,包括支持的维度类型、处理方式、异常类型、阈值设置方式、原始代码语言以及加速实现效果。
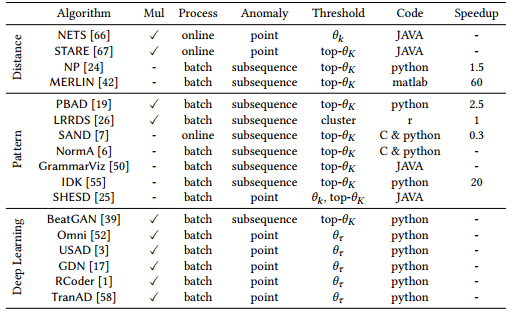
此处提及的所有异常检测方法
3.1基于距离的算法
此类算法可用于检测点或子序列异常,文章中以点异常为主进行说明。首先引出两个定义:
定义3.1(邻居):给定距离阈值
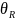 ,若两个数据点间距离
,若两个数据点间距离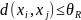 ,则称是
,则称是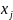 的邻居。
的邻居。
定义3.2(基于距离的异常点):若某数据点的邻居数量少于阈值
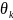 ,则该点被认为是异常点。
,则该点被认为是异常点。
这一类的算法中的关键参数包括距离阈值、邻居数量阈值,以及在实时检测方法中使用的窗口大小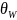 、滑动步长
、滑动步长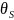 。同时,该类方法通常关注大规模数据的可扩展性,主要算法包括:
。同时,该类方法通常关注大规模数据的可扩展性,主要算法包括:
NETS:采用基于集合的策略,认为短时间内的数据集中分布于空间某些小区域。
STARE:通过判断滑动窗口间局部区域分布是否变化,跳过更新无变化区域。
NP:基于Bagging思想挖掘频繁与罕见子序列,采用邻域球替代最近邻,以增强鲁棒性。
DRAG、MERLIN:DRAG创建一个不一致候选集,然后在其中搜索最近邻距离大于超参数
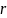 的不一致列表。MERLIN使用结构化搜索来确定异常距离阈值。
的不一致列表。MERLIN使用结构化搜索来确定异常距离阈值。
3.2基于模式的算法
此类算法试图识别数据中的规律性,如高频出现的子序列模式或分布特征,适用于检测子序列异常。
定义3.3(基于模式的异常):给定时序数据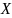 设子序列长度为,频率阈值为
设子序列长度为,频率阈值为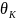 ,则得分排名靠前、与正常模式最不相似的前个子序列为异常
,则得分排名靠前、与正常模式最不相似的前个子序列为异常
这一类算法中的关键参数包括:支持度阈值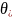 、异常得分阈值
、异常得分阈值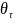 、数量阈值,主要算法包括:
、数量阈值,主要算法包括:
SHESD:对ESD(极端学生化偏差)方法进行季节性增强,采用STL分解,使用中位数与MAD(中值绝对偏差)代替均值与标准差。
NormA、SAND、IDK:通过聚类学习正态模型,计算目标子序列和正态模型相似性距离得出异常分数;SAND扩展了k-Shape算法以支持实时检测,IDK引入隔离分布式内核(Isolation Distributional Kernel)进行相似度计算。
PBAD、GrammarViz:分别基于频繁模式和语法归纳方法,提取偏离的子序列作为异常。
LRRDS:利用递归图与LREC曲线,计算局部递归率以衡量子序列异常度。
3.3基于深度学习的算法
近年来,深度学习在时序异常检测中应用广泛,主要包括重建式与预测式两种方式。
(1)重建式方法:首先通过编码器学习正常数据的潜在特征,再解码重建,重建误差大的数据点被视为异常。
OmniAnomaly(Omni):采用GRU与VAE相结合,来建模多维序列中的复杂时序依赖。
USAD:引入自编码器-解码器结构与双阶段对抗训练。
BeatGAN:结合自编码器与生成对抗网络,提供可解释的子序列异常检测。
RCoder:使用一维潜空间与FFT频谱分析增强异常检测。
TranAD:结合Transformer结构与对抗训练进行异常检测。
(2)预测式方法:基于历史观测预测未来值,实际值与预测值差异即为异常度量。
GDN:引入图神经网络建模多维间依赖,结合注意力机制进行预测。
3.4实现说明
考虑到如Apache IoTDB等系统对Java的支持优先,作者将非深度学习方法(除NormA)重写为Java版本。并统一所有方法的数据结构,以排除性能差异对比较结果的干扰。此外,为保证公平性,作者移除了自动阈值选择工具(POT)和预测结果调整方法(point-adjust),验证了重构前后的结果一致性,以确保实验可复现性。
本文的实验主要从类内对比(intra-class)与类间对比(inter-class)两个层面进行分析与总结
4.1实验设置
4.1.1数据集
实验中采用了多个公开的真实数据集和合成数据集,共15个真实数据集与8类合成数据变体,涵盖点异常与子序列异常、多维与单维、各种异常率、长度与模式。合成数据基于正弦波生成,并注入不同类型的异常(全局、上下文、季节性、趋势)以满足标签不可靠场景下的研究需求。
每种异常类型下的异常长度统一设置为50,确保所有方法可适用。同时为了减小随机性的影响,实验在合成数据每种类型中运行10次并取平均结果。完整数据集概况如下:
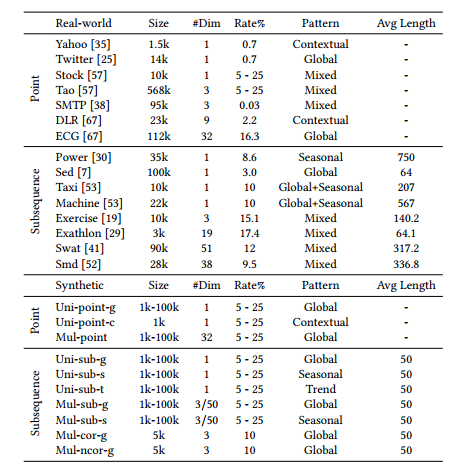
真实数据集和合成数据集概况
4.1.2评价指标
实验中的评价指标主要分为准确性指标和效率指标。
对于准确性指标,分为点指标和子序列(范围)指标:
点指标:采用Precision精确度,Recall召回率和F1作为指标。
子序列指标:采用子序列指标,衡量预测子序列与真实子序列之间的重叠程度。计算指标包括子序列召回率、精确率与F1指标。
对于效率指标,除去数据读取与结果评估,实验中统计模型处理与检测过程中的总耗时作为时间成本。
4.1.3参数搜索
为了公平比较各无监督算法,作者为每种方法设计了系统的超参数搜索空间。训练集(不含异常)按“训练集:验证集:测试集= 4:1:5”的比例划分。同时对算法(如对USAD方法)尝试不同的潜空间维度:{2, 5, 10, 20},最终选取在验证集上效果最优的配置。
4.2类内比较
4.2.1不同数据集
实验首先使用最佳参数评估在不同数据集上所有方法的性能。为了获得多维数据上单维方法的结果,实验分别在每个维度上运行它们,并结合所有报告的异常结果。
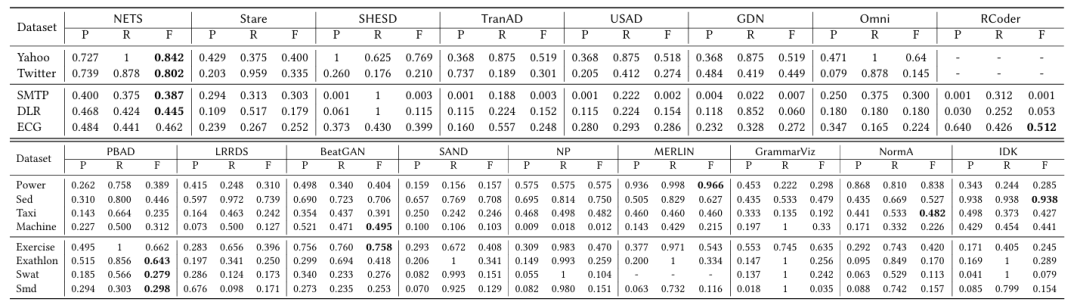
在不同数据集上算法的准确性
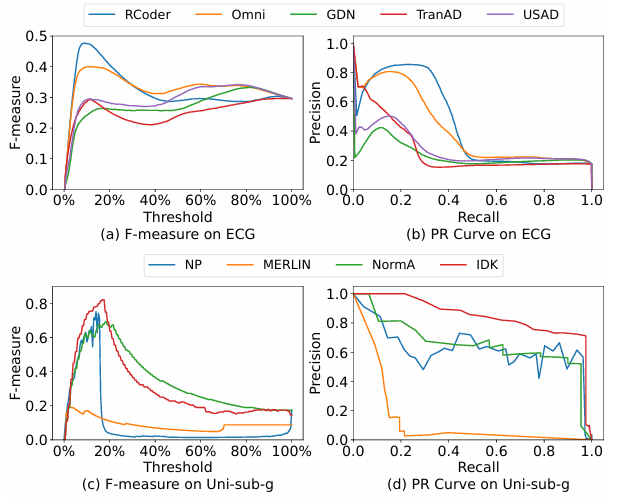
(1)点异常检测算法表现:实验结果表明,NETS在多个数据集上表现稳定且准确性高。STARE算法效果一般,因为高度依赖窗口中异常点数量参数,易受实际分布影响。深度学习方法中除RCoder外,其余在维度较低的数据上效果不佳。RCoder在ECG数据(32维)上表现出色,而在维度较低数据中效果反而逊色。时间效率方面,NETS最优,TranAD也较快。
(2)子序列异常检测算法表现:实验显示,多维方法如PBAD与BeatGAN在多维数据中优于单维方法。NormA在单维数据上效果稳定,MERLIN对季节性异常处理能力强,SAND在异常段过长时性能下降。GrammarViz与PBAD作为基于规则的算法,在某些单维数据中效果相近。
可以看出,对于不同的数据集,不存在万能的算法,每种方法适用于特定场景。总体来说,NETS参数调优后表现优异,PBAD与BeatGAN综合准确率高但耗时更多,而深度学习方法在复杂模式数据上优势不明显。
4.2.2异常率 变化
变化
实验在合成数据上将异常率从5%逐步提升至25%,以评估方法的敏感性和鲁棒性。
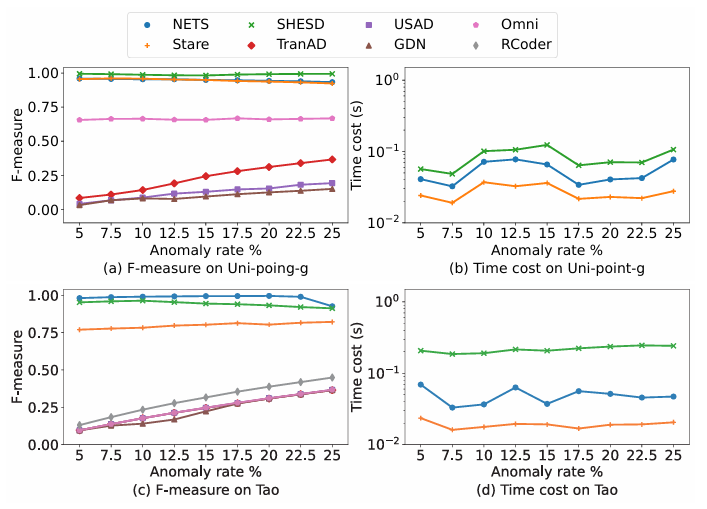
点异常检测算法结果
(1)点异常检测算法表现:实验结果表明,非深度方法(如NETS、STARE)在不同异常率下表现稳定。NETS在Tao数据集上表现稍弱,原因是当异常点与正常点邻居数相近时,难以设定合适阈值。部分深度方法(如TranAD、USAD、GDN)随着异常率上升而表现更佳,可能是因为其本身模型效果较差,预测出更多假阳性,恰好在高异常率下被“变为真阳性”。
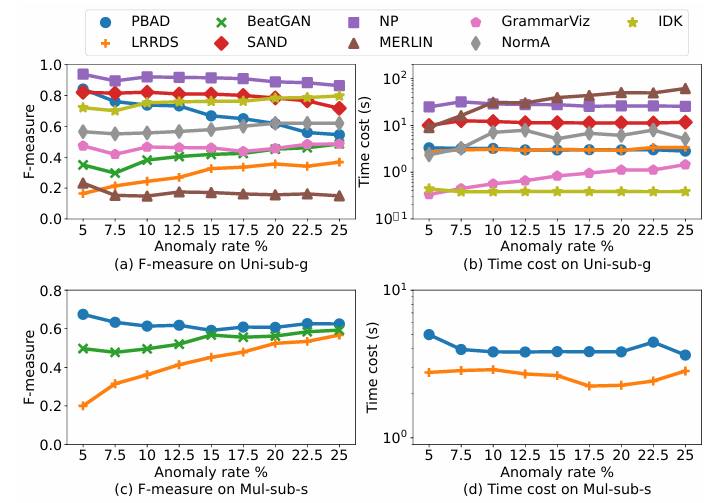
子序列异常检测算法结果
(2)子序列异常检测算法表现:实验结果可以看出,除MERLIN与GrammarViz外,大多数方法在不同异常率下运行时间基本稳定。准确性方面,PBAD等方法在低异常率时表现更好,而LRRDS与BeatGAN则在异常率高时更佳,这可能是由于减少了由异常点的粗略识别引起的误报。
总体来说,大部分算法在低异常率(<25%)时比较稳定,异常率增高有时反而提高F1分数,并且对效率的影响不大。
4.2.3数据规模 变化
变化
实验在数据规模从1k增长至100k的情况下,考察方法的延展性。
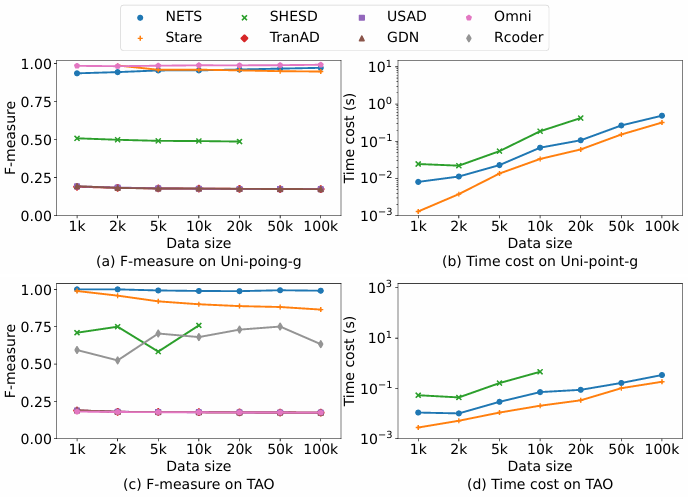
点异常检测算法实验结果
(1)点异常检测算法表现:实验结果表明,随着数据规模增长,各方法耗时均有所增加,但准确性基本稳定。NETS与STARE因算法结构优势,在大数据下效率最好。
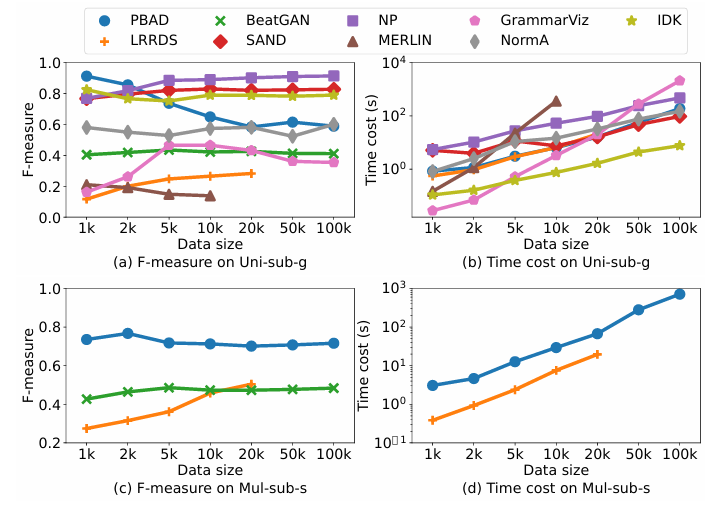
子序列异常检测算法实验结果
(2)子序列异常检测算法表现:实验观察到,在小规模(<10k)数据下,大部分基于模式的方法(如PBAD)性能波动较大,原因在于难以提取稳定的正常模式。数据足够大时,表现趋于稳定。MERLIN与LRRDS扩展性较差,大数据下耗时极长甚至内存溢出。
总的来说,NETS、STARE、NormA等方法效率优,同时小数据规模不利于基于模式学习的算法。
4.2.4维度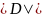 变化
变化
实验通过调整ECG与Swat数据的维度,评估方法在高维下的表现。
维度变化实验结果
(1)点异常检测算法表现:实验结果显示,所有方法在高维下准确性都进行了提升。RCoder由于引入更多参考与估计器,维度越高表现越好。计算开销也随维度增长显著增加。
(2)子序列异常检测算法表现:实验可以看出,LRRDS方法通过降维处理展现良好伸缩性;PBAD由于需对每个维度提取特征,导致维度增加时耗时急剧增长。Swat算法中的异常分布不一致,导致多方法在不同维度下表现差异显著。
总而言之,LRRDS维度扩展性较好,NETS/STARE对维度较敏感,适合低维场景,而RCoder适合维度>30场景。
4.2.5异常模式变化
作者还使用含有不同异常类型(点/区段、全局/上下文/季节性/趋势)的数据进行实验。
异常模式变化结果
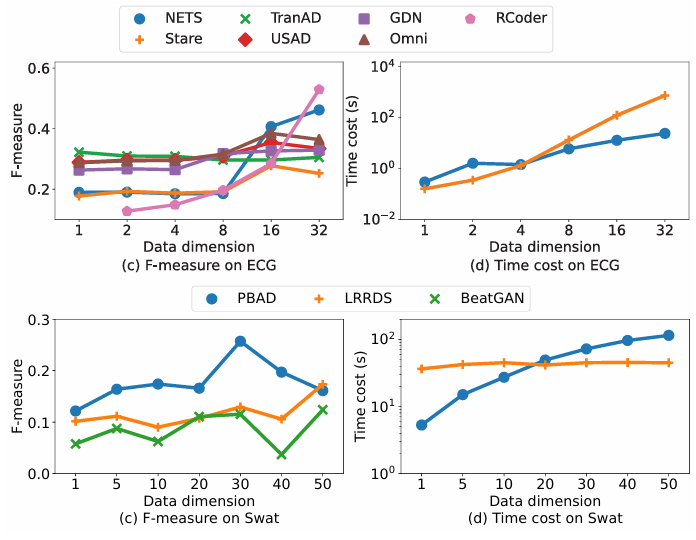
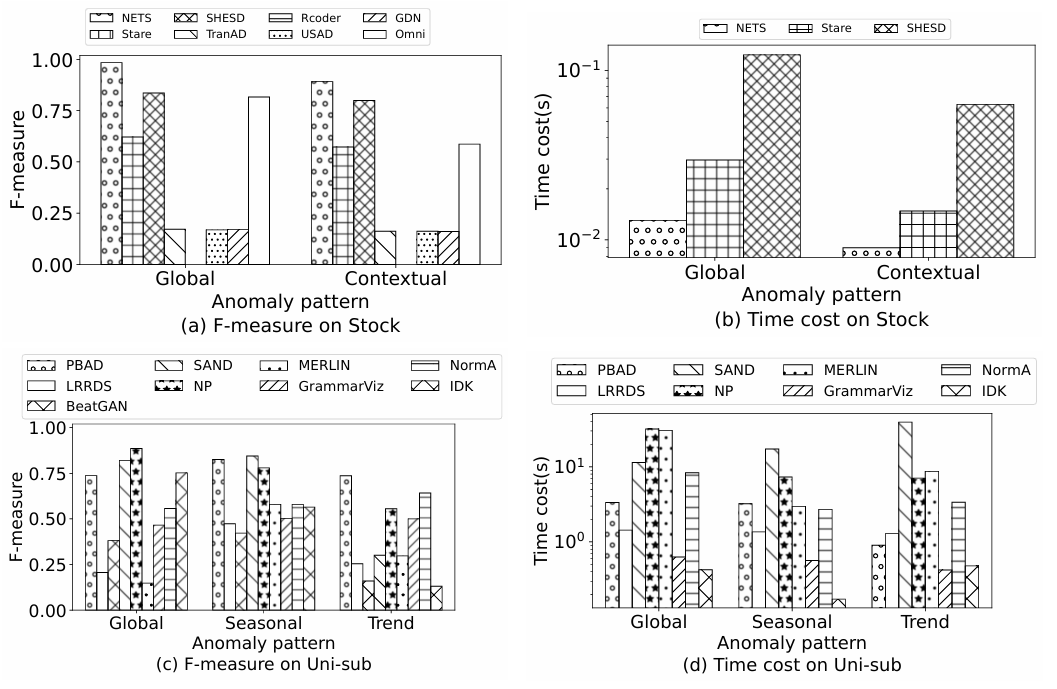
(1)点异常检测算法表现:实验中所有方法对全局异常(F1=0.618)的识别优于上下文异常(F1=0.551),并且计算开销变化不大。
(2)子序列异常检测算法表现:实验中算法平均F1分别为:全局异常0.550,季节性异常0.619,趋势异常0.398。其中,PBAD与NormA在各模式下稳定;SAND与NP适用于全局异常与季节性异常,而BeatGAN与IDK对趋势异常处理能力较弱。
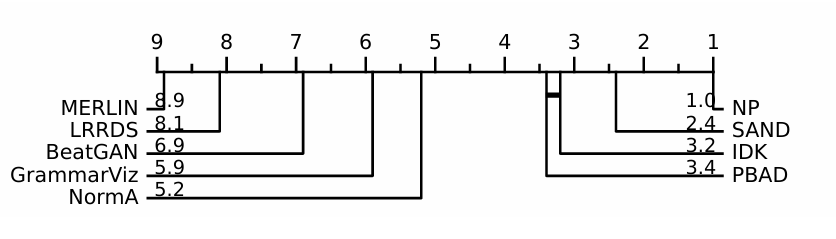
同时实验还使用Friedman检验与Wilcoxon后验检验分析不同算法在特定异常类型下是否显著优于其他方法。实验结果显示,某些方法在特定类型中确实显著更优(如NP在全局异常中)。
算法关键差异图
可以看出,全局异常比上下文异常更易识别。整体的异常识别难易程度可以归纳为:季节性异常最容易,趋势异常最难,并且没有适用于所有模式的方法。具体来说,NP适合全局异常;SAND/IDK不适用于趋势异常;基于距离的算法适用于全局与季节性异常,
4.3类间比较
实验还测试同一维度下不同类之间方法的性能。对多维数据的每个维度分别运行单维方法,然后将结果合并。对于处理技术方面,实验在大于100k且维度大于30的数据集上跨不同窗口和幻灯片大小运行实时检测方法。在异常类型方面,实验在不同评估指标下对具有子序列异常的数据集运行点异常检测算法和子序列异常检测算法,以分析指标的影响和预测中的调整。同时测试了在不同的应用方面阈值和性能的影响。
4.3.1单维方法用于多维数据
实验测试了将单维方法分别应用于多维数据每一维,并进行合并的结果(“Combination”这一行),以比较单维方法与多维方法的效果差异。
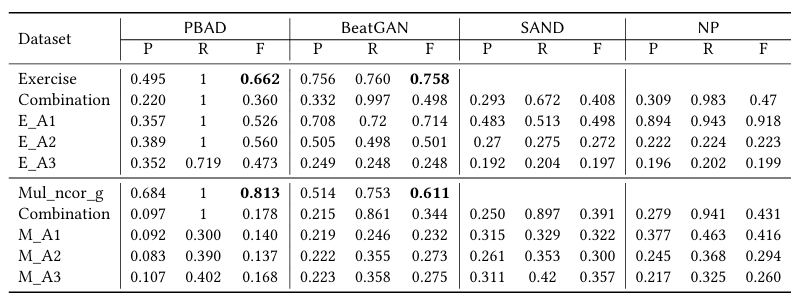
单一维度和组合维度的性能结果
实验发现,单维方法虽在某些维度表现出色,但合并结果往往召回率升高、精度下降,F1反而变差。这体现出了多维方法更优,能更好捕捉各维之间的关联。
4.3.2实时检测方法用于批数据
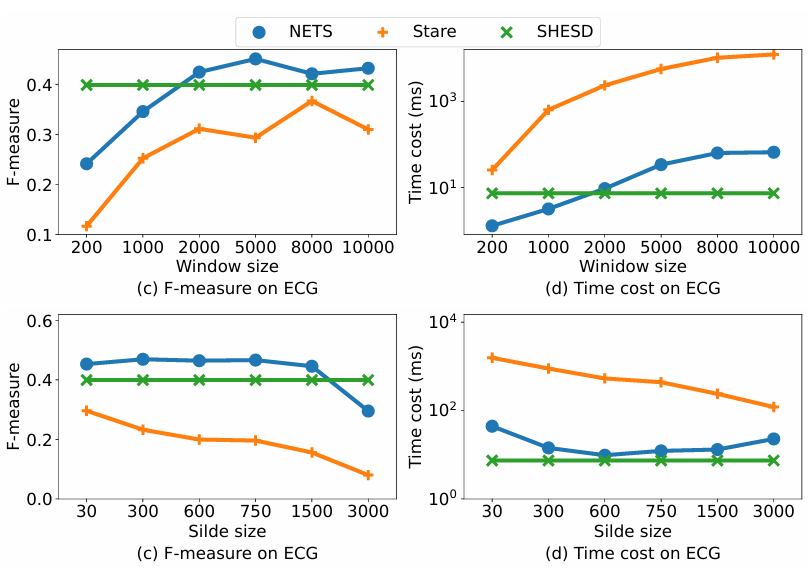
比较实时检测方法和批处理方法
实验对NETS与STARE两种算法在不同窗口、滑动步长下的表现进行分析(以ECG为例),并与批处理方法SHESD进行对比。实验结果表明,若窗口过小,正常点缺少足够的邻居,误报增多;若窗口过大,局部异常点的相邻点的数量可能超过预定义阈值,漏报增多。但是存在一个合理窗口范围来平衡精度与效率。
4.3.3在子序列异常中使用点异常检测算法
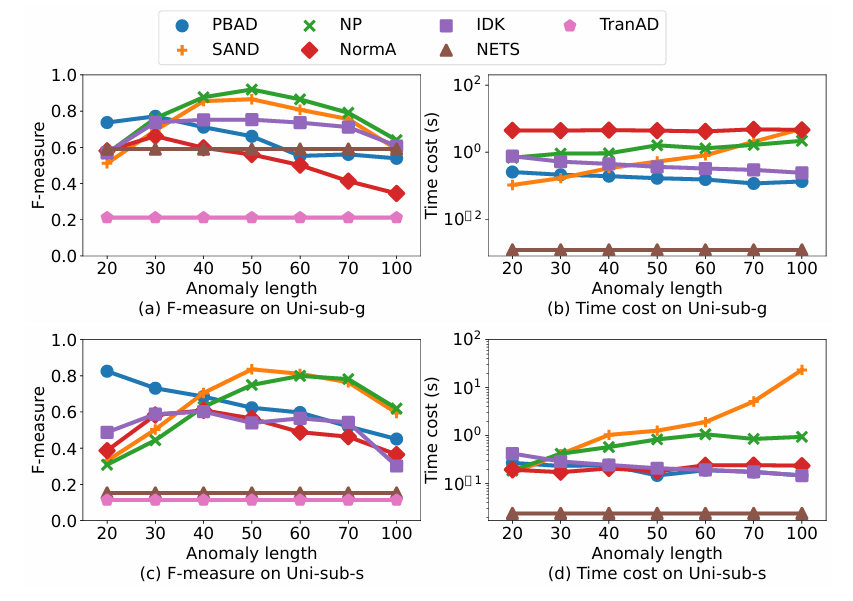
点异常检测算法应用于子序列异常数据结果
子序列异常检测算法总是将异常长度作为输入参数。相反,点异常检测算法不需要这样的输入(长度为1)。为了了解异常长度的影响,实验中使用注入全局异常和季节性异常的单维数据来避免维度的影响。实验结果表明,点异常检测算法对异常长度具有敏感性。对于全局异常和季节性异常,当异常长度为50时,NP和SAND可以表现出很好的性能,而PBAD和NormA性能随着异常长度的增加而衰减。同时,NETS在两种异常的时间成本很少。实验表明点异常检测算法也可以很好地处理全局子序列异常。
4.3.4评价指标与结果调整方法的影响
实验在多个包含子序列异常的数据集上,对比了以下三种策略下的模型表现:
(1)使用点异常检测算法,按点指标评估;
(2)使用点异常检测算法,配合Point-Adjust后处理,再按点指标评估(表格中算法后带*);
(3)使用子序列评估指标(range-based metric)直接评估点异常检测算法检测结果。
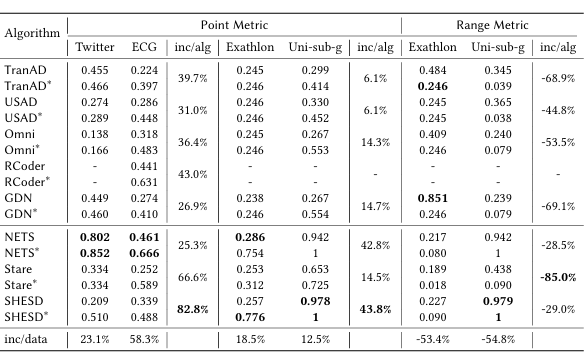
通过Point-Adjust方法的结果
实验结果发现,Point-Adjust方法确实可以在点指标下显著提高F1分数,但这并不意味着检测效果本身提升。使用子序列评估指标时,可以更真实地反映点异常检测算法在子序列异常上的覆盖效果,结果通常较低,但更具代表性。并且一些算法在未调整时表现平平(如NETS、USAD),但经调整后表现提升很大,但是一些高分的点异常检测算法在Point-Adjust后产生了大量虚高检测段,极易误导使用者。
4.3.5阈值鲁棒性
多种阈值对算法的影响
实验中尝试多种阈值设定方式,对比不同算法在固定与动态阈值下的表现。结果显示,一些方法对阈值设定极度敏感。使用动态阈值的算法如GDN、USAD在不当参数下精度急剧下降。作者此处建议使用数据驱动的阈值选择策略进行调整。
4.3.6应用分析
实验中还讨论了两个现实应用中的异常检测。场景1:某些应用对积极的结果更感兴趣,例如癌症检测。某些应用对消极的结果更感兴趣,例如识别垃圾邮件。场景2:在之前的研究中,实验假设离群值范围的所有位置都同样重要。在现实场景中,癌症检测和实时系统对于早期响应的要求比较高。对于场景1,实验在所有的真实数据集上使用点异常检测算法和子序列异常检测算法,在场景2上使用子序列异常检测算法。实验结果中Flat指标表示所有位置具有相同分数的度量,而Front指标表示为子序列异常的早期位置分配更多权重
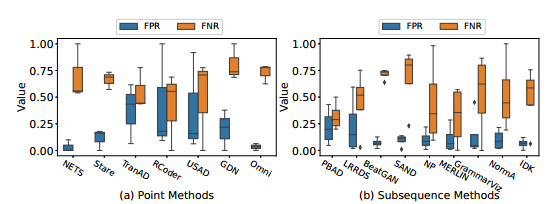
场景1实验结果
对于场景1,所有算法一般都有较高的假阴性率和较低的假阳性率,这表明它们更适合于消极应用,并且比异常样本更有能力检测正常样本。特别是NETS和Omni的假阳性较低,推荐用于垃圾邮件检测应用。另一方面,建议将TranAD和RCoder用于积极应用程序,因为它们能够报告所有异常。
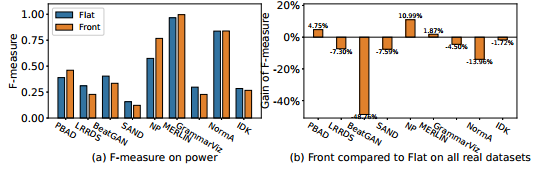
场景2实验结果
对于场景2,实验结果显示了算法在Flat和Front指标下对Power数据集的性能。可以看出,BeatGAN在Flat指标下的f-measure比PBAD高,但在使用Front指标时得分较低,表明它不适合早期检测。
作者在相关工作中总结8个先前关于时序数据中异常检测的实验研究,与本文的工作进行了对比。表格中前三列表示研究中涵盖的基本方面,比如在数据维度中包括单维,多维,单维和多维方法之间的比较;处理技术中包括了批处理,实时检测和两种方法之间的比较;异常类型则包括了点异常,子序列异常和两者之间的比较。同时,研究还包含了对阈值鲁棒性和应用指南方面的比较。整体的相关工作比较如下:

几种实验性调查的比较
本文介绍了时序数据中异常检测方法的分类,并提出了系统的实验类内和类间比较。作者将这些研究结果总结为实用指南,并提出了一些未来发展。
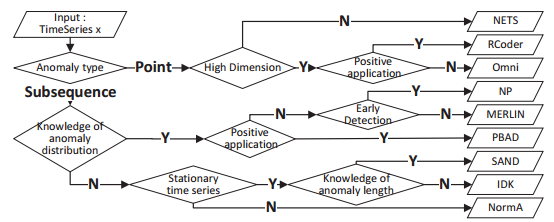
时序数据异常检测实用指南
(1)实用指南:图中给出了时序数据异常检测的实用指南,该指南基于异常类型、维度、应用程序类型等各个方面的实验结果,为未来的后续工作提供参考和帮助。
(2)可解释性: 近年来,异常检测方法的可解释性引起了许多关注。决策者可能对异常值发生的原因更感兴趣,以便他们可以采取适当的行动,特别是在物联网数据领域。开发一种提供高准确性和合理可解释性的方法可能是未来工作的新方向。
论文解读联系人:
刘思源
13691032906(微信同号)
liusiyuan@caict.ac.cn
数据库是基础软件的重要一员,是支撑全球数字经济蓬勃发展的核心技术产品。为推动我国数据库产业国际地位从跟跑、并跑到领跑,多家数据库企业、应用单位、系统集成商、数据库服务企业、硬件制造商,共同成立公益性免费社群数据库应用创新实验室(以下简称“实验室”),打造了中国数据库产业的“联合舰队”。实验室持续致力于推动我国数据库产业创新发展,以实际问题为导向,以合作共赢为目标,联合政、产、学、研、用等多方力量,协同推进数据库领域应用创新的相关工作。实验室将一直秉承开放理念,持续欢迎数据库领域各企业、各机构、各组织申请加入。





