




点击上方↗️「活水智能」,关注 + 星标🌟

作者:Alex Gilmore
编译:活水智能
本文将深入探讨如何在 GenAI 应用中有效利用函数调用,借助 LangChain、LangGraph 和 Pydantic 实现更强大的功能。函数调用是一种强大的方法,它允许 LLM 生成符合代码中可调用函数及其参数的结构化输出。这使得 GenAI 应用不仅仅是聊天机器人,更扩展了它们的能力,使其能够执行更高级的数据检索方法和更具交互性的任务。
本文将讨论函数调用以及如何通过 OpenAI Chat Completions API 和 LangChain 来实现函数调用功能。其他 LLM 提供商可能有不同的函数调用方法,但从概念上讲,它们应该是类似的。
本文的示例应用是一个烹饪助手,它可以访问包含食谱及其作者的数据库。文章将讨论 LangGraph 工作流架构以及各种工具及其执行方式。最后,通过一些示例问题,演示此应用程序如何使用不同的工具来解决问题。
此示例应用程序使用 Neo4j 作为底层数据库。虽然此处展示的工具专为通过 Cypher 查询语言从 Neo4j 数据库检索数据设计,但这些概念同样适用于使用其他数据库的 LLM 应用。
代码和示例 notebook 可以在 GitHub (https://github.com/a-s-g93/function-calling-medium-article) 上找到。
术语定义
为了更好地理解本文的内容,我们先明确几个关键术语。由于 GenAI 领域发展迅速,部分概念可能存在多种解读。因此,本文将采用以下定义:
• Agent(代理):使用 LLM 来决定下一步要采取哪些步骤的系统。
• Workflow(工作流):通过预定义的路径协调 LLM 和工具的系统。
• Agentic workflow(Agentic 工作流):包含预定义路径和代理的混合系统。
• GraphRAG:指利用图数据库中的图遍历来检索信息的一种 RAG 方法。
• Retrieval-augmented generation (RAG)(检索辅助生成):从外部数据源收集数据并将其作为上下文提供给 LLM 以生成响应的过程,最终生成答案。
• Tool(工具):LLM 知道并可能调用的函数(术语“工具”和“函数”将互换使用)。
• Tool calling(工具调用):与函数调用相同,指的是提示 LLM 返回包含字典列表的结构化输出的过程,每个条目包含一个函数名称及其参数。
技术栈
这里涵盖的概念不限于此技术栈。但是,请注意并非所有 LLM 都支持函数调用。
• LangChain:LLM 接口
• LangGraph:LLM 编排框架
• Neo4j:图数据库
• OpenAI:LLM 提供商
• Python
• Pydantic:用于 Python 的高级类型检查和验证
定义工具
LangChain 支持多种定义工具:https://python.langchain.com/docs/how_to/tool_calling/的方式。一种强大的方法是通过 Pydantic 类。这允许您显式定义工具描述和参数,同时提供验证检查。然后,这些相同的类可以处理和验证返回的工具调用信息。以下是演示应用程序可以访问的一些工具:
class text2cypher(BaseModel):
"""默认的数据检索工具。使用 LLM 生成一个新的 Cypher 查询来满足任务。"""
task: str = Field(..., description="Cypher 查询必须回答的任务。")
class get_most_common_ingredients_an_author_uses(BaseModel):
"""检索特定作者在其食谱中最常用的成分。"""
author: str = Field(..., description="要搜索的完整作者姓名。")
@field_validator("author")
def validate_author(cls, v: str) -> str:
return v.lower()
以上代码定义了两个工具:
•
text2cypher
: 这是一个默认的数据检索工具,它使用 LLM 生成 Cypher 查询来满足特定任务。•
get_most_common_ingredients_an_author_uses
: 这个工具用于检索特定作者在其食谱中最常用的成分。它接受一个author
参数,并使用field_validator
确保作者姓名转换为小写。
Agentic 工作流架构
此示例中的 agentic 工作流使用 LangGraph(https://langchain-ai.github.io/langgraph/concepts/) 进行编排。LangGraph 工作流中的每个节点都是一个包含进程的组件,而每条边代表这些节点之间信息的流动。在此示例中,需要注意以下几个节点:
1. Guardrails(护栏)
2. Planner(规划器)
3. Tool Selection(工具选择)
4. Error Handling(错误处理)
5. Predefined Cypher Executor(预定义 Cypher 执行器)
6. Text2Cypher
7. Summarize(总结)
8. Final Answer(最终答案)
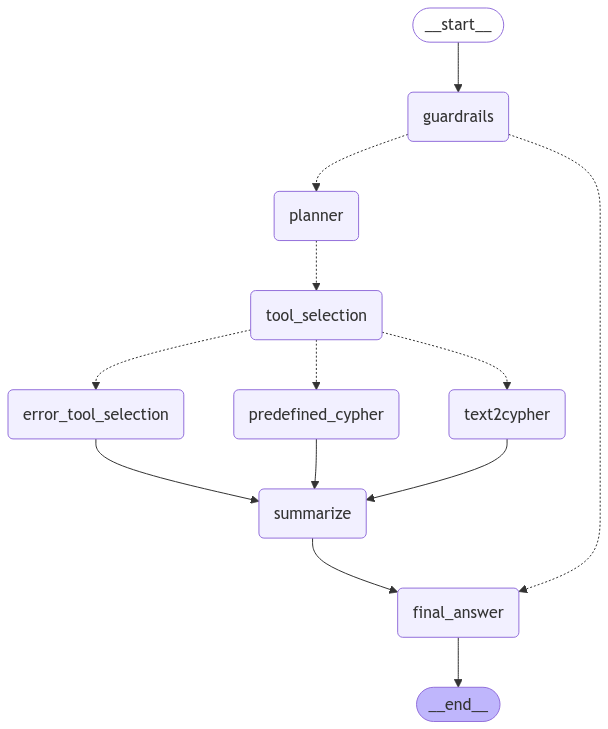
虽然本文主要关注函数调用,但还需要注意此 LangGraph 工作流的其他一些功能。
Planner 和 Summarize 之间的节点通过 map-reduce (https://langchain-ai.github.io/langgraph/how-tos/map-reduce/) 操作执行,其中每个找到的任务都映射到 Tool Selection 节点,并且工具执行结果作为列表减少到状态变量中——在本例中为 cyphers
。这允许并行处理每个任务,从而缩短整体响应时间。
Text2Cypher 节点是一个仅被视为节点的 subgraph(子图)(https://langchain-ai.github.io/langgraph/how-tos/subgraph/)。这使得 Text2Cypher 进程可以轻松保持其自身状态,并以模块化方式包含在其他 agentic 工作流中。
Multi-tool agentic 工作流构建代码:https://github.com/a-s-g93/function-calling-medium-article/blob/main/ps_genai_agents/workflows/multi_agent/multi_tool.py
Guardrails 和 Planner 节点
Guardrails 节点决定传入的问题是否在应用程序的范围内。如果不在范围内,则提供默认消息,并且工作流路由到最终答案生成。
Planner 节点接收来自 Guardrails 节点的已验证的输入问题,并识别提供令人满意的答案所需的任务。然后,这些任务可以由工具选择和执行步骤并行处理。
Guardrails 代码:https://github.com/a-s-g93/function-calling-medium-article/blob/main/ps_genai_agents/components/guardrails/node.py
Planner 代码:https://github.com/a-s-g93/function-calling-medium-article/blob/main/ps_genai_agents/components/planner/node.py
Tool Selection 节点
Tool Selection 节点将工具分配给单个任务。如果该工具是 Text2Cypher,则必要的状态将路由到 Text2Cypher 子图。如果该工具是预定义的 Cypher 查询,则必要的状态将改为路由到预定义的 Cypher Executor 节点。也可能未选择任何工具。在这种情况下,节点可以默认为 Text2Cypher 或路由到错误处理节点,该节点将正常失败。了解更多关于 Cypher:https://neo4j.com/docs/getting-started/cypher/) 的信息,Neo4j 使用的查询语言。
Tool Selection 代码:https://github.com/a-s-g93/function-calling-medium-article/blob/main/ps_genai_agents/components/tool_selection/node.py
Tool 节点
此示例中有许多工具,但只有两种调用它们的方法。一种是 Text2Cypher,它将为与预先存在的工具不匹配的问题生成新的 Cypher 语句。此工具将通过下面详细介绍的 Text2Cypher 子图执行。另一种工具是预先编写的参数化 Cypher 查询,它接受从输入任务中提取的参数,并通过预定义的 Cypher Executor 节点运行它们。
Predefined Cypher Executor
预定义的 Cypher Executor 是我们 LangGraph agentic 工作流中的一个节点。它负责运行 LLM 找到的带有参数的预定义 Cypher 查询。每个查询代表 LLM 可以使用的唯一工具。此节点将负责执行以下工具:
•
get_allergen_free_recipes
(获取不含过敏原的食谱)•
get_most_common_ingredients_an_author_uses
(获取作者最常用的食材)•
get_recipes_for_diet_restrictions
(获取适合饮食限制的食谱)•
get_easy_recipes
(获取简单食谱)•
get_mid_difficulty_recipes
(获取中等难度食谱)•
get_difficult_recipes
(获取困难食谱)
例如,当 LLM 选择 get_allergen_free_recipes
作为工具时,会从任务文本中提取过敏原列表:
class get_allergen_free_recipes(BaseModel):
"""检索不包含所提供过敏原的所有食谱的列表。"""
allergens: List[str] = Field(
..., description="食谱中应避免的过敏原列表。"
)
然后,此列表将通过 $allergens
参数注入到预定义的 Cypher 查询中,并针对 Neo4j 数据库执行,以检索用于生成最终答案的上下文:
MATCH (r:Recipe)
WHERE none(i in $allergens WHERE exists(
(r)-[:CONTAINS_INGREDIENT]->(:Ingredient {name: i})))
RETURN r.name AS recipe,
[(r)-[:CONTAINS_INGREDIENT]->(i) | i.name]
AS ingredients
ORDER BY size(ingredients)
LIMIT 20
Predefined Cypher Executor 代码:https://github.com/a-s-g93/function-calling-medium-article/blob/main/ps_genai_agents/components/predefined_cypher/node.py
Text2Cypher
Text2Cypher 是我们 LangGraph 工作流中的一个子图,但在工具选择步骤中它被视为一个工具。负责选择工具的 LLM 代理不需要知道 Text2Cypher 的详细信息;它只需要知道它可以做什么以及它需要什么输入。抽象出子图详细信息和函数逻辑可以显著减少 LLM 处理的 token 数量。
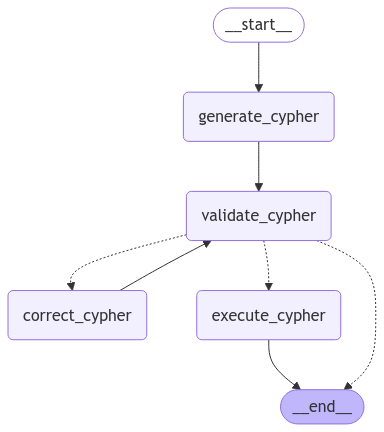
此处未涵盖 Text2Cypher 的详细信息,但更多信息位于 LangChain 文档(https://python.langchain.com/docs/tutorials/graph/) 中,该文档启发了此架构和 Effortless RAG With Text2CypherRetriever(https://neo4j.com/blog/developer/effortless-rag-with-text2cypherretriever-cb1a781ca53c),由 Neo4j 工程师编写。
Text2Cypher 子图代码:https://github.com/a-s-g93/function-calling-medium-article/tree/main/ps_genai_agents/components/text2cypher
Error-Handling 节点
如果 LLM 请求在工具选择期间未能返回工具,并且没有默认工具,则应用程序可能会路由到 Error-Handling 节点。在此示例中,它只是为失败的任务附加一个空数据集,允许应用程序继续运行而不会中断。这是以可能缺少必要的上下文为代价的。
Tool Selection Error-Handling 代码:https://github.com/a-s-g93/function-calling-medium-article/blob/main/ps_genai_agents/components/errors/tool_selection/node.py
Summarize 和 Final Answer 节点
Summarize 节点负责以易于最终用户理解的格式总结检索到的数据。一旦异步检索到所有数据,它将在此节点中处理。然后,它将发送到 Final Answer 节点,该节点将格式化并返回最终答案以及执行的查询和检索到的数据。
Summarize 代码:https://github.com/a-s-g93/function-calling-medium-article/blob/main/ps_genai_agents/components/summarize/node.py
Final Answer 代码:https://github.com/a-s-g93/function-calling-medium-article/blob/main/ps_genai_agents/components/final_answer/node.py
工具作为上下文
本节使用 OpenAI Chat Completions API 来解释如何将工具作为上下文与消息一起提供给 LLM。
典型的 LLM 请求可能包含几种消息类型:
• User(用户) → 包含用户问题和一些说明
• System (Developer)(系统(开发者)) → 模型通常应如何表现;这些在用户消息之前提供
• Assistant(助手) → 任何以前的或示例 LLM 响应
这些消息作为 Python 字典列表传递给 OpenAI Chat Completions API 的 messages 参数。以下是 OpenAI 文档中的一个示例:
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "developer", "content": "You are a helpful assistant."},
{
"role": "user",
"content": "Write a haiku about recursion in programming."
}
]
)
print(completion.choices[0].message)
有关更多信息,请参阅 OpenAI 的文本生成文档:https://platform.openai.com/docs/guides/text-generation。
为了将函数作为上下文传递给 LLM,它们作为 Python 字典列表提供给 tools 参数。以下是 OpenAI 文档中的另一个示例:
from openai import OpenAI
client = OpenAI()
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current temperature for a given location.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City and country e.g. Bogotá, Colombia"
}
},
"required": [
"location"
],
"additionalProperties": False
},
"strict": True
}
}]
completion = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "What is the weather like in Paris today?"}],
tools=tools # <-- Pass Functions / Tools here
)
print(completion.choices[0].message.tool_calls)
有关更多信息,请参阅 OpenAI 的函数调用文档:https://platform.openai.com/docs/guides/function-calling?lang=python#function-calling-steps。
LangChain 通过其 LLM 类上的 bind_tools()
方法对此进行了抽象。这处理将工具格式化为 Python 字典并将其传递给 OpenAI Chat Completions API 的 tools 参数。查看更多使用 LangChain 进行工具调用的示例]:https://python.langchain.com/docs/concepts/tool_calling/。
解析工具响应
请记住,此示例中的函数是使用 Pydantic 类定义的。这允许您使用这些相同的类轻松验证返回的函数调用并捕获任何现有错误。然后,可以将这些错误传递回 LLM 以在更正循环中修复函数调用。它还能够轻松地对结果进行后处理,例如将所有字符串转换为小写或在适当的时候舍入数字。
LangChain 提供了一个输出解析器,用于处理此问题,称为 [PydanticToolsParser](https://python.langchain.com/api_reference/core/output_parsers/langchain_core.output_parsers.openai_tools.PydanticToolsParser.html)
。此解析器允许进行其他配置,例如仅返回列表中的第一个工具:
tool_selection_chain: Runnable[Dict[str, Any], Any] = (
tool_selection_prompt
| llm.bind_tools(tools=tool_schemas)
| PydanticToolsParser(tools=tool_schemas, first_tool_only=True)
)
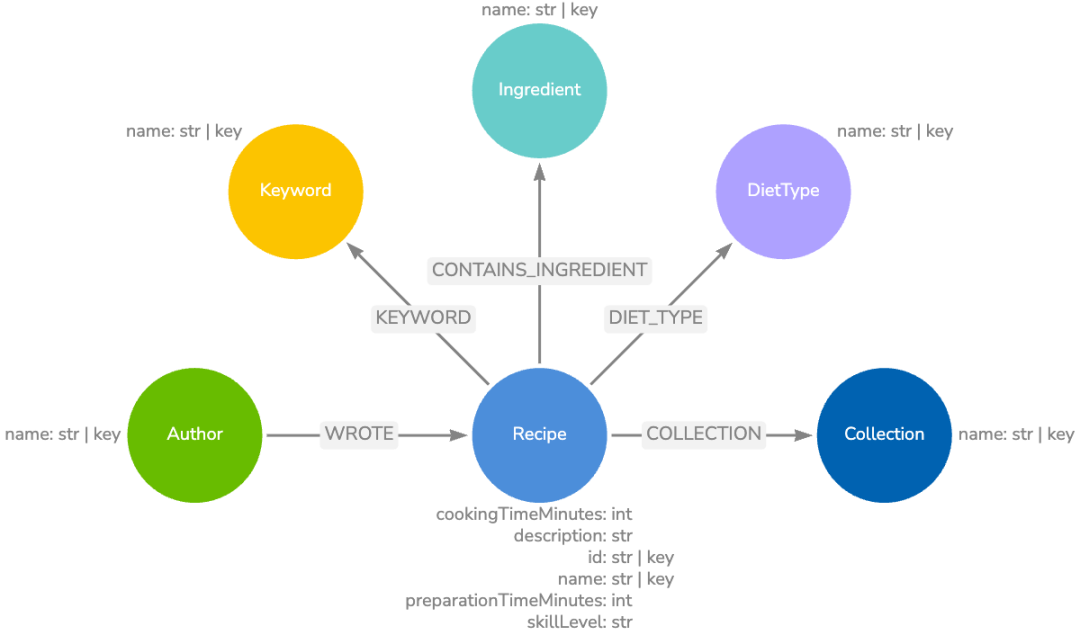
数据
此示例应用程序可以访问包含 BBC Good Food 食谱信息的 Neo4j 图数据库。它是 Neo4j 提供的示例数据集:https://neo4j.com/docs/getting-started/appendix/example-data/。
演示
此 agentic 工作流能够通过使用预定义的 Cypher 工具或 Text2Cypher 来回答问题。仅当工具描述与任务的需求完全匹配时,才会提示它使用预定义的 Cypher。否则,它应该选择 Text2Cypher。检索到所有数据后,它将被总结并返回给用户。
此 LangGraph agentic 工作流输出具有以下字段的响应。为了本演示的目的,没有必要知道工作流中的中间状态,但这些输出状态将用于分析下面的响应。
class CypherOutputState(TypedDict):
task: str
statement: str
parameters: Optional[Dict[str, Any]]
errors: List[str]
records: List[Dict[str, Any]]
steps: List[str]
class OutputState(TypedDict):
"""多代理工作流的最终输出。"""
answer: str
question: str
steps: List[str]
cyphers: List[CypherOutputState]
仅 Text2Cypher
这个问题实际上与 LLM 可以使用的任何预定义的 Cypher 工具都不匹配。因此,应选择 Text2Cypher 工具来解决此问题。
q1 = await agent.ainvoke(
{
"question": "有多少作者写过食谱?"
},
)
LLM 返回:
**303 位作者写过食谱。**
工作流步骤显示 Text2Cypher 用于回答此问题:
[
'guardrails',
'planner',
'tool_selection',
'generate_cypher', # <-- 开始 Text2Cypher
'validate_cypher',
'execute_cypher',
'text2cypher', # <-- Text2Cypher 完成
'summarize',
'final_answer'
]
仅预定义的 Cypher
这个问题可以通过执行其中一个预定义的 Cypher 工具来回答。LLM 根据上面定义的 Pydantic 类表示选择适当的工具:
q2 = await agent.ainvoke(
{"question": "Emma Lewis 最喜欢用哪些食材?"}
)
LLM 返回:
- **橄榄油**: 39 个食谱
- **黄油**: 37 个食谱
- **蒜瓣**: 29 个食谱
- **洋葱**: 24 个食谱
- **鸡蛋**: 21 个食谱
- **柠檬**: 21 个食谱
- **植物油**: 18 个食谱
- **普通面粉**: 15 个食谱
- **细砂糖**: 13 个食谱
- **百里香**: 11 个食谱
工作流步骤验证使用了预定义的 Cypher 工具:
[
'guardrails',
'planner',
'tool_selection',
'execute_predefined_cypher', # <-- 预定义的 Cypher 工具
'summarize',
'final_answer'
]
由于 Cypher 查询在响应对象中返回,因此也可以查看它:
Emma Lewis 最常用的食材是什么?
MATCH (:Author {name: $author})-[:WROTE]->(:Recipe)-[:CONTAINS_INGREDIENT]->(i:Ingredient)
RETURN i.name as name, COUNT(*) as numRecipes
ORDER BY numRecipes DESC
LIMIT 10
Parameters:
{'author': 'emma lewis'}
Text2Cypher 和预定义的 Cypher
这个问题包含两个独立的任务。一个可以通过预定义的 Cypher 工具解决,而另一个将需要 Text2Cypher。由于 Planner 节点异步路由任务,因此应用程序可以并行执行这些工具:
q3 = await agent.ainvoke(
{
"question": "有什么简单的食谱可以做吗? 另外,你能分享你知道多少种食材吗?"
},
)
LLM 返回:
- **杏子和开心果法式奶油蛋糕**
- **蜂蜜洋甘菊茶**
- **酥皮蛇**
- **快速香蕉冰淇淋三明治**
- **花生酱辣椒红洋葱**
我知道大约 3068 种食材。
同样,工作流步骤验证了使用了预期的工具:
[
'guardrails',
'planner',
'tool_selection',
'execute_predefined_cypher', # <-- 预定义的 Cypher 执行器
'generate_cypher', # <-- # 开始 Text2Cypher
'validate_cypher',
'execute_cypher',
'text2cypher', # <-- Text2Cypher 完成
'summarize',
'final_answer'
]
虽然上面的步骤看起来是串行的,但请记住,
*planner*
和*summarize*
之间的步骤是并行执行的。
应用程序还存储带有其 Cypher 查询和参数的任务。这可以用作额外的验证。
# 预定义的 Cypher 任务
有什么简单的食谱可以做吗?
MATCH (r:Recipe {skillLevel: "easy"})
RETURN r.name as name
LIMIT $number_of_recipes
Parameters:
{'number_of_recipes': 5} # 此参数由 LLM 识别
# Text2Cypher 任务
你知道多少种食材?
MATCH (i:Ingredient)
RETURN count(i) AS numberOfIngredients
Parameters: # 这里不需要参数
None
总结
函数调用是一种强大的工具,它能够显著扩展 LLM 的功能范围。本文演示了使用两种不同类型的工具从 Neo4j 检索数据,但工具可以涵盖广泛的功能。例如,它们可以允许访问各种数据库或发出 API 请求。Pydantic 模型可以定义这些工具并验证其输出,从而实现更可预测的响应。
虽然本文重点介绍了使用 LangChain 和 Pydantic 来处理工具调用,但有多种方法可以实现此目的,并且可以通过使用 LLM 提供商的 API 简单地完成。
资源
GitHub Repo:https://github.com/a-s-g93/function-calling-medium-article
LangChain: Build a Question Answering Application Over a Graph Database - https://python.langchain.com/docs/tutorials/graph/
Anthropic: Building Effective Agents - https://www.anthropic.com/research/building-effective-agents
Neo4j: Effortless RAG with Text2CypherRetriever - https://medium.com/neo4j/effortless-rag-with-text2cypherretriever-cb1a781ca53c
LangChain: How to Use Chat Models to Call Tools - https://python.langchain.com/docs/how_to/tool_calling/
LangChain: How to Create Map-Reduce Branches for Parallel Execution - https://langchain-ai.github.io/langgraph/how-tos/map-reduce/
LangChain: How to Use Subgraphs - https://langchain-ai.github.io/langgraph/how-tos/subgraph/
LangChain: LangGraph Docs - https://langchain-ai.github.io/langgraph/concepts/
OpenAI: OpenAI Chat Completions API Docs - https://platform.openai.com/docs/
GitHub Repo: https://github.com/a-s-g93/function-calling-medium-article
学习资源
若要了解更多知识图谱或图数据库相关教学,你可以查看公众号的其他文章:
活水智能成立于北京,致力于通过AI教育、AI软件和社群提高知识工作者生产力。
活水现有AI线下工作坊等10+门课程,15+AI软件上线,多款产品在研。知识星球中拥有2600+成员,涵盖大厂程序员、公司高管、律师等各类知识工作者。在北、上、广、深、杭、重庆等地均有线下组织。
欢迎加入我们的福利群,每周都有一手信息、优惠券发放、优秀同学心得分享,还有赠书活动~
👇🏻👇🏻👇🏻

