




点击上方↗️「活水智能」,关注 + 星标🌟

作者:Júlio Almeida
编译:活水智能

在这个大语言模型(LLM)的新时代,银行和金融机构面临一定的劣势,因为前沿模型由于硬件要求几乎不可能进行本地部署。然而,银行数据的敏感性带来了显著的隐私问题,尤其是当这些模型仅作为云服务提供时。为了解决这些挑战,组织可以选择本地部署或小型语言模型(SLM)的方案,以确保数据保存在内部,避免敏感信息泄露。这种方法能够在利用先进的LLM能力(本地部署或最小化外部调用)的同时,严格遵守诸如GDPR、HIPAA或各类金融指令等法规。
本文展示了如何通过结合以下工具构建完全本地化的文档智能解决方案:
• ExtractThinker(https://github.com/enoch3712/ExtractThinker) —— 一个开源框架,用于协调OCR、分类和数据提取管道,适配LLM。
• Ollama(https://github.com/ollama/ollama) —— 一种用于部署本地语言模型(如Phi-4或Llama 3.x)的解决方案。
• Docling(https://github.com/DS4SD/docling) 或 MarkItDown(https://github.com/microsoft/markitdown) —— 灵活的库,用于文档加载、OCR和布局解析。
无论您是在严格保密规则下工作、处理扫描PDF,还是希望进行高级的基于视觉的提取,这套端到端的技术栈都能提供一个完全在您自身基础设施内运行的安全、高性能管道。
1. 选择合适的模型(文本 vs. 视觉)
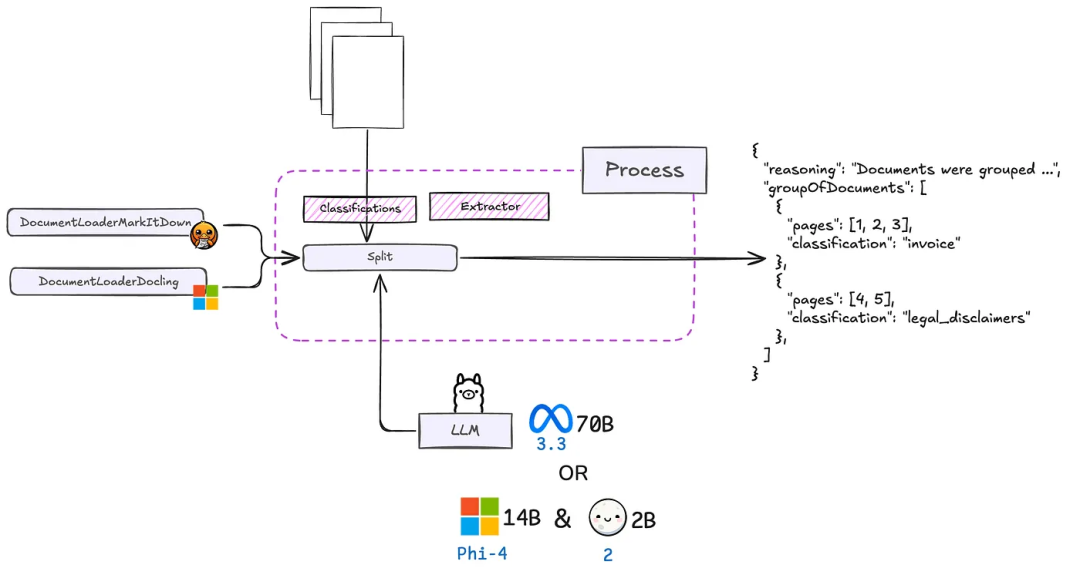
在构建文档智能技术栈时,首先需要决定使用仅支持文本的模型还是支持视觉的模型。仅支持文本的模型通常是本地部署的首选,因为它们更容易获取且限制较少。然而,支持视觉的模型在高级拆分任务中可能至关重要,特别是当文档依赖视觉线索(如布局、配色方案或特定格式)时。
在某些场景中,可以为不同阶段配对不同的模型。例如,一个较小的moondream模型(0.5B参数)可以处理拆分任务,而Phi-4 14B模型则负责分类和提取。许多大型机构更倾向于部署一个单一且更强大的模型(如Llama 3.3或Qwen 2.5,70B参数范围)来覆盖所有用例。如果您只需要处理以英语为主的智能文档处理(IDP),可以直接使用Phi4完成大部分任务,同时保留轻量级的moondream模型以应对边缘拆分情况。这完全取决于您的具体需求和可用的基础设施。
2. 文档处理:MarkItDown vs. Docling
在文档解析方面,有两个流行的库脱颖而出:
MarkItDown
• 简单、直接,广泛受到微软支持。
• 非常适合不需要多OCR引擎的直接文本任务。
• 安装和集成都非常方便。
Docling
• 更高级,支持多OCR引擎(如Tesseract、AWS Textract、Google Document AI等)。
• 非常适合扫描工作流或从图像PDF中进行强大的提取。
• 文档详尽,灵活应对复杂布局。
ExtractThinker允许您根据需求选择DocumentLoaderMarkItDown
或DocumentLoaderDocling
,无论是简单的数字PDF还是需要多引擎OCR的复杂任务。
3. 运行本地模型
虽然Ollama是一个运行本地LLM的流行工具,但目前也有多个解决方案可以与ExtractThinker无缝集成,用于本地部署:
• LocalAI(https://github.com/mudler/LocalAI) —— 一个开源平台,可以在消费级硬件(甚至仅使用CPU)上运行LLM,如Llama 2或Mistral,并提供简单的端点供连接。
• OpenLLM(https://github.com/bentoml/OpenLLM) —— 一个由BentoML开发的项目,通过OpenAI兼容的API暴露LLM。它针对吞吐量和低延迟进行了优化,适合本地部署和云端部署,支持多种开源LLM。
• Llama.cpp(https://github.com/ggerganov/llama.cpp) —— 一种运行Llama模型的低级方法,支持高级的自定义配置。适合需要细粒度控制或高性能计算(HPC)设置的场景,但管理起来更复杂。
Ollama 通常因其简单的设置和CLI而成为首选。然而,对于企业或HPC场景,Llama.cpp服务器部署、OpenLLM或类似LocalAI的解决方案可能更为合适。上述所有方案都可以通过将本地LLM端点指向环境变量或代码中的基础URL,与ExtractThinker集成。
4. 应对小上下文窗口
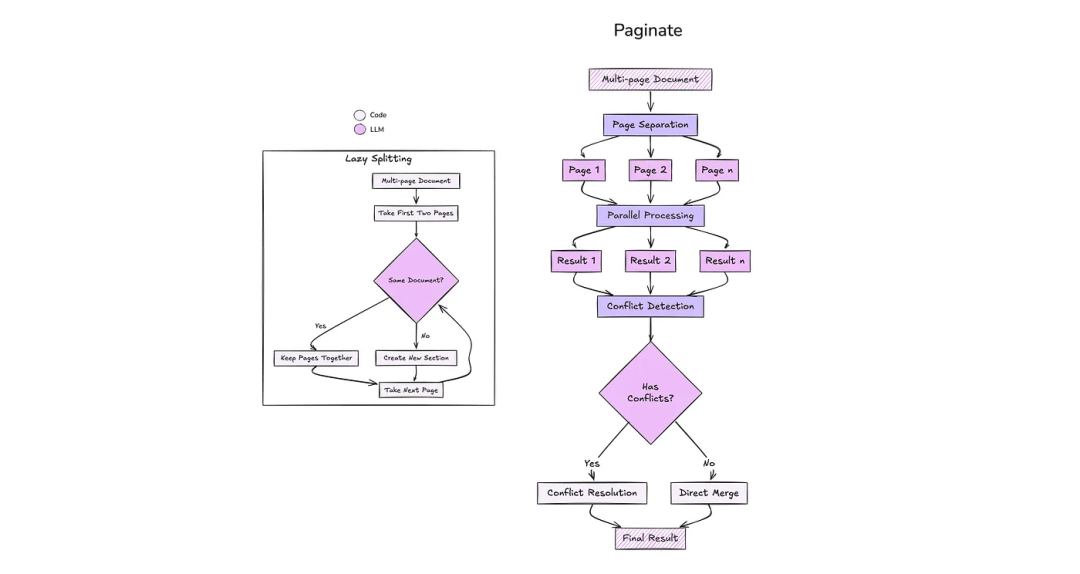
在使用上下文窗口有限的本地模型时(如~8K tokens或更少),必须合理管理以下两方面:
文档拆分
为避免超出模型的输入容量,Lazy Splitting(懒拆分)是一种理想的方法。与一次性加载整个文档不同:
• 您可以逐步比较页面(如第1-2页,然后第2-3页),判断它们是否属于同一子文档。
• 如果是,则将它们合并以供下一步处理;如果不是,则开始一个新的片段。
• 这种方法对内存友好,并能通过一次仅加载和分析几页的方式扩展到非常大的PDF。
**注意:**如果模型的Token容量较高,建议使用Concatenate(合并);如果容量有限,则优先选择Paginate(分页)。
处理部分响应
对于较小的本地模型,如果提示词过大,每次响应也可能被截断。PaginationHandler可以优雅地解决此问题,具体方法包括:
• 将文档的页面拆分为单独的请求(每页一个请求)。
• 在最后合并页面级结果,并在页面对某些字段存在分歧时进行可选的冲突解决。
**注意:**如果Token容量较高,建议使用Concatenate(合并);如果容量有限,则优先选择Paginate(分页)。
快速示例流程
1. 懒拆分PDF,使每个片段/页面保持在模型限制以下。
2. 分页处理页面:每个片段的结果单独返回。
3. 合并页面级结果为最终的结构化数据。
这种最小化的方法确保您在将PDF输入模型时以及处理多页响应时都不会超出本地模型的上下文窗口。
5. ExtractThinker:构建技术栈
以下是集成这些组件的最小代码片段。首先,安装ExtractThinker:
pip install extract-thinker
文档加载器
如上所述,我们可以使用MarkItDown或Docling。
from extract_thinker import DocumentLoaderMarkItDown, DocumentLoaderDocling
# DocumentLoaderDocling or DocumentLoaderMarkItDown
document_loader = DocumentLoaderDocling()
定义数据结构
我们使用基于Pydantic的数据结构来指定需要提取的数据结构。例如,发票和驾驶执照:
from extract_thinker.models.contract import Contract
from pydantic import Field
class InvoiceContract(Contract):
invoice_number: str = Field(description="Unique invoice identifier")
invoice_date: str = Field(description="Date of the invoice")
total_amount: float = Field(description="Overall total amount")
class DriverLicense(Contract):
name: str = Field(description="Full name on the license")
age: int = Field(description="Age of the license holder")
license_number: str = Field(description="License number")
分类
如果您有多种文档类型,可以定义分类对象。您可以指定:
• 每种分类的名称(如“发票”)。
• 描述。
• 它映射到的数据结构。
from extract_thinker import Classification
TEST_CLASSIFICATIONS = [
Classification(
name="Invoice",
description="This is an invoice document",
contract=InvoiceContract
),
Classification(
name="Driver License",
description="This is a driver license document",
contract=DriverLicense
)
]
整合:本地提取流程
以下代码展示了如何创建一个提取器,它使用我们选择的document_loader
和一个本地模型(如Ollama、LocalAI等)。然后,我们构建一个流程,以单一管道加载、分类、拆分和提取数据。
import os
from dotenv import load_dotenv
from extract_thinker import (
Extractor,
Process,
Classification,
SplittingStrategy,
ImageSplitter,
TextSplitter
)
# Load environment variables (if you store LLM endpoints/API_BASE, etc. in .env)
load_dotenv()
# Example path to a multi-page document
MULTI_PAGE_DOC_PATH = "path/to/your/multi_page_doc.pdf"
def setup_local_process():
"""
Helper function to set up an ExtractThinker process
using local LLM endpoints (e.g., Ollama, LocalAI, OnPrem.LLM, etc.)
"""
# 1) Create an Extractor
extractor = Extractor()
# 2) Attach our chosen DocumentLoader (Docling or MarkItDown)
extractor.load_document_loader(document_loader)
# 3) Configure your local LLM
# For Ollama, you might do:
os.environ["API_BASE"] = "http://localhost:11434" # Replace with your local endpoint
extractor.load_llm("ollama/phi4") # or "ollama/llama3.3" or your local model
# 4) Attach extractor to each classification
TEST_CLASSIFICATIONS[0].extractor = extractor
TEST_CLASSIFICATIONS[1].extractor = extractor
# 5) Build the Process
process = Process()
process.load_document_loader(document_loader)
return process
def run_local_idp_workflow():
"""
Demonstrates loading, classifying, splitting, and extracting
a multi-page document with a local LLM.
"""
# Initialize the process
process = setup_local_process()
# (Optional) You can use ImageSplitter(model="ollama/moondream:v2") for the split
process.load_splitter(TextSplitter(model="ollama/phi4"))
# 1) Load the file
# 2) Split into sub-documents with EAGER strategy
# 3) Classify each sub-document with our TEST_CLASSIFICATIONS
# 4) Extract fields based on the matched contract (Invoice or DriverLicense)
result = (
process
.load_file(MULTI_PAGE_DOC_PATH)
.split(TEST_CLASSIFICATIONS, strategy=SplittingStrategy.LAZY)
.extract(vision=False, completion_strategy=CompletionStrategy.PAGINATE)
)
# 'result' is a list of extracted objects (InvoiceContract or DriverLicense)
for item in result:
# Print or store each extracted data model
if isinstance(item, InvoiceContract):
print("[Extracted Invoice]")
print(f"Number: {item.invoice_number}")
print(f"Date: {item.invoice_date}")
print(f"Total: {item.total_amount}")
elif isinstance(item, DriverLicense):
print("[Extracted Driver License]")
print(f"Name: {item.name}, Age: {item.age}")
print(f"License #: {item.license_number}")
# For a quick test, just call run_local_idp_workflow()
if __name__ == "__main__":
run_local_idp_workflow()
6. 隐私与PII:云端LLM的挑战
并非所有组织都能或愿意运行本地硬件。一些组织更倾向于使用先进的云端LLM。如果选择云端方案,请注意以下几点:
• 数据隐私风险:将敏感数据发送到云端可能带来合规性问题。
• GDPR/HIPAA:相关法规可能完全禁止数据离开本地环境。
• VPC + 防火墙:您可以将云资源隔离在私有网络中,但这会增加系统复杂性。
注意:许多LLM API(如OpenAI)确实提供GDPR合规性。但如果您受严格监管或希望轻松切换供应商,建议考虑本地方案或云端掩码处理方案。
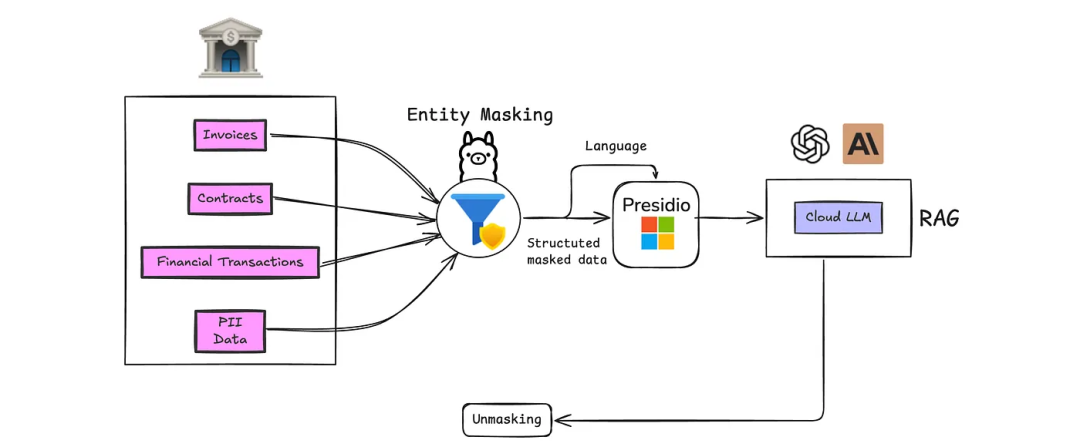
PII掩码处理
一种稳健的方法是构建一个PII掩码处理管道。工具如Presidio可以在将数据发送至LLM之前,自动检测并去除个人标识符。这样,您可以保持对模型的独立性,同时确保合规性。
7. 结论
通过结合ExtractThinker与本地LLM(如Ollama、LocalAI或OnPrem.LLM)以及灵活的文档加载器(Docling或MarkItDown),您可以从零开始构建一个安全的、本地化的文档智能工作流。如果法规要求完全隐私或最小化外部调用,这套技术栈能够在不牺牲现代LLM能力的情况下,将您的数据完全保留在内部。
学习资源
若要了解更多知识图谱或图数据库相关教学,你可以查看公众号的其他文章:
4种方法+1个工具,轻松用LLMs构建知识图谱! Neo4j + LangChain:如何构建基于知识图谱的最强RAG系统? 利用AI大模型,将任何文本语料转化为知识图谱,可本地运行 解读 Graph RAG:从大规模文档中发现规律,找到相互关系,速度更快,信息更全面! 利用LLM构建非结构化文本的知识图谱
活水智能成立于北京,致力于通过AI教育、AI软件和社群提高知识工作者生产力。中国AIGC产业联盟理事。
活水现有AI线下工作坊等10+门课程,15+AI软件上线,多款产品在研。知识星球中拥有2600+成员,涵盖大厂程序员、公司高管、律师等各类知识工作者。在北、上、广、深、杭、重庆等地均有线下组织。
欢迎加入我们的福利群,每周都有一手信息、优惠券发放、优秀同学心得分享,还有赠书活动~
👇🏻👇🏻👇🏻

