





来源:Christoffer Bergman
编译:活水智能
你是否曾经想找一首歌,但你不记得它的名字,也不记得是谁写的?或者你只是模糊地记得它的内容?让我们用四行代码构建一个工具,解决这个问题。

“互联网是一种可能会消失的潮流。我不认为从长远来看,人们会愿意花这么多时间浏览网络。” ——瑞典通信部长 Ines Uusmann,1996 年
这是瑞典通信部长 Ines Uusmann 在 1996 年的一句话。我猜她说得对,互联网确实是一种潮流,但它是一种已经存在了 20 年的潮流,并且显然不会消失。很难想象现代生活没有互联网的样子。实际上,在 90 年代初期引发这股潮流的是万维网的推出。
类似地,许多人称 AI 是一种潮流,这当然也是事实,但它与互联网潮流非常相似。AI 已经存在了半个多世纪,我相信它将在未来继续存在,像今天的互联网一样成为我们生活中不可或缺的一部分。万维网之于互联网,正如大语言模型(LLM)和生成式 AI 之于人工智能。
如果这个预测是正确的,那么对于软件开发人员来说,学习并接受这项新技术是非常重要的,不仅仅是通过与 ChatGPT 聊天,而是通过学习如何自己使用这项技术。而且你不需要成为数学家才能做到这一点。有许多优秀的工具可以让 AI 的使用变得简单。Neo4j 就是其中之一。
Neo4j 与 AI
知识图谱与大语言模型(LLM)及生成式 AI 结合的力量已广为人知,并且已经在数十篇文章中探讨过。随着向量索引、向量搜索和内置嵌入程序的加入,你所需要的一切都被打包在 Neo4j 图数据库中。
我不会深入讨论向量搜索的原理,只给你一个简要的理解。向量是具有长度和方向的东西,有点像箭头。在二维空间中,你可以用两个数字 x 和 y 来描述向量,如下所示。
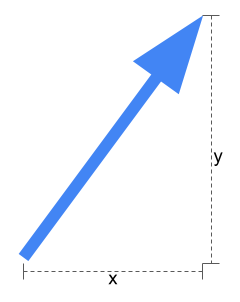
向量嵌入是指让大语言模型(LLM)创建一个单一的向量来表示自然语言文本(或图像或音乐片段)的内容,例如这篇博客文章。但它不是像上面那样的二维向量,而是一个具有数千维度的向量(在 OpenAI 的情况下是 1536 维)。现在你有了文本的数值表示,通过它你可以搜索相似的文本,例如另一篇关于生成式 AI 和 Neo4j 的博客(有几篇这样的博客)。这不是文本中使用的单词的相似性,而是文本的实际意义(这正是 LLM 设计来理解的)。
Neo4j 允许你将向量嵌入存储为节点上的属性,然后搜索与某个嵌入相似的节点。你还可以对这些向量进行索引,以加快搜索速度。这就是我们将用来创建歌词查找器的功能。
为什么要创建歌词查找器?
但为什么我们要创建这样一个工具呢?ChatGPT 在这方面表现得非常出色。如果我问它:
哪首 Metallica 的歌曲是关于一个在战争中受了重伤,失去了所有感官的人的?
它会回答:
你提到的 Metallica 歌曲是《One》。这首歌来自他们 1988 年的专辑《…And Justice for All》。这首歌的灵感来自 Dalton Trumbo 的小说《Johnny Got His Gun》,讲述了一名士兵在第一次世界大战中受伤后失去了所有感官,包括视力、听力和语言能力。在这首歌中,Metallica 表达了战争的恐怖与痛苦,以及在这种悲惨情况下个人身份的丧失。
那么,为什么我们还要自己创建这个工具呢?有几个原因:
• ChatGPT 只知道在训练大语言模型时存在的内容。因此,如果是 Metallica 最新专辑《72 Seasons》中的歌曲,它就无法工作。
• ChatGPT 很酷,但它并不完全可靠。有时候,它会直接撒谎。
• 如果你将此功能作为音乐服务(如 Spotify)的一部分,你只想搜索你库中的歌曲,而不是所有歌曲。
• 如果你想将这样的功能整合到像 Spotify 这样的工具中,你可能不想集成一个聊天功能,而是一个更明确的 API。
我们的工具
在开始之前,我们需要创建一个 OpenAI 账户。Neo4j 支持 OpenAI、VertexAI 和 AWS Bedrock 来进行嵌入,但我们将使用 OpenAI。请注意,这些是付费账户,因此会产生费用。但我为本文所做的所有测试费用不到 2 美分。在我们的 OpenAI 账户中,我们需要创建一个 API 密钥,这就是在下面查询中用作 $apiKey 的密钥。
Neo4j 5.x 版本逐步引入了生成式 AI 支持。我们将在此处使用的最新部分——嵌入程序——在 Neo4j 5.15 中发布,因此我们将使用该版本。
如果你有自己的 Neo4j 实例,你需要通过将 neo4j-genai-plugin-5.XX.0.jar 从 products 文件夹复制到 Neo4j 的 plugins 文件夹中来安装嵌入程序(并重新启动)。如果你使用 Aura,则默认可以访问这些程序。
测试本文内容的一种方法是设置一个 Aura Free 实例。只需在此处:https://neo4j.com/cloud/aura-free/ 设置一个免费账户,然后创建一个实例进行测试。记住你还需要注册一个 OpenAI 账户。
在本文中,我不会围绕这些功能编写任何应用程序。相反,我只会在 Neo4j 浏览器中编写 Cypher 查询。但如果你要开发一个这样的工具,当然应该将这些查询集成到你的应用程序中。
把所有写过的歌曲都纳入进来可能很酷,但我没有访问这些数据的权限,因此在这个例子中,我找到了一个包含所有 Metallica 歌曲歌词的库,直到《St Anger》为止。我找到了 HTML 格式的歌词,但我解析了这些歌词,并创建了一个包含艺术家(在本例中只有 Metallica)、专辑和歌曲的图谱,每首歌的歌词作为每个 Song 节点上的字符串属性。
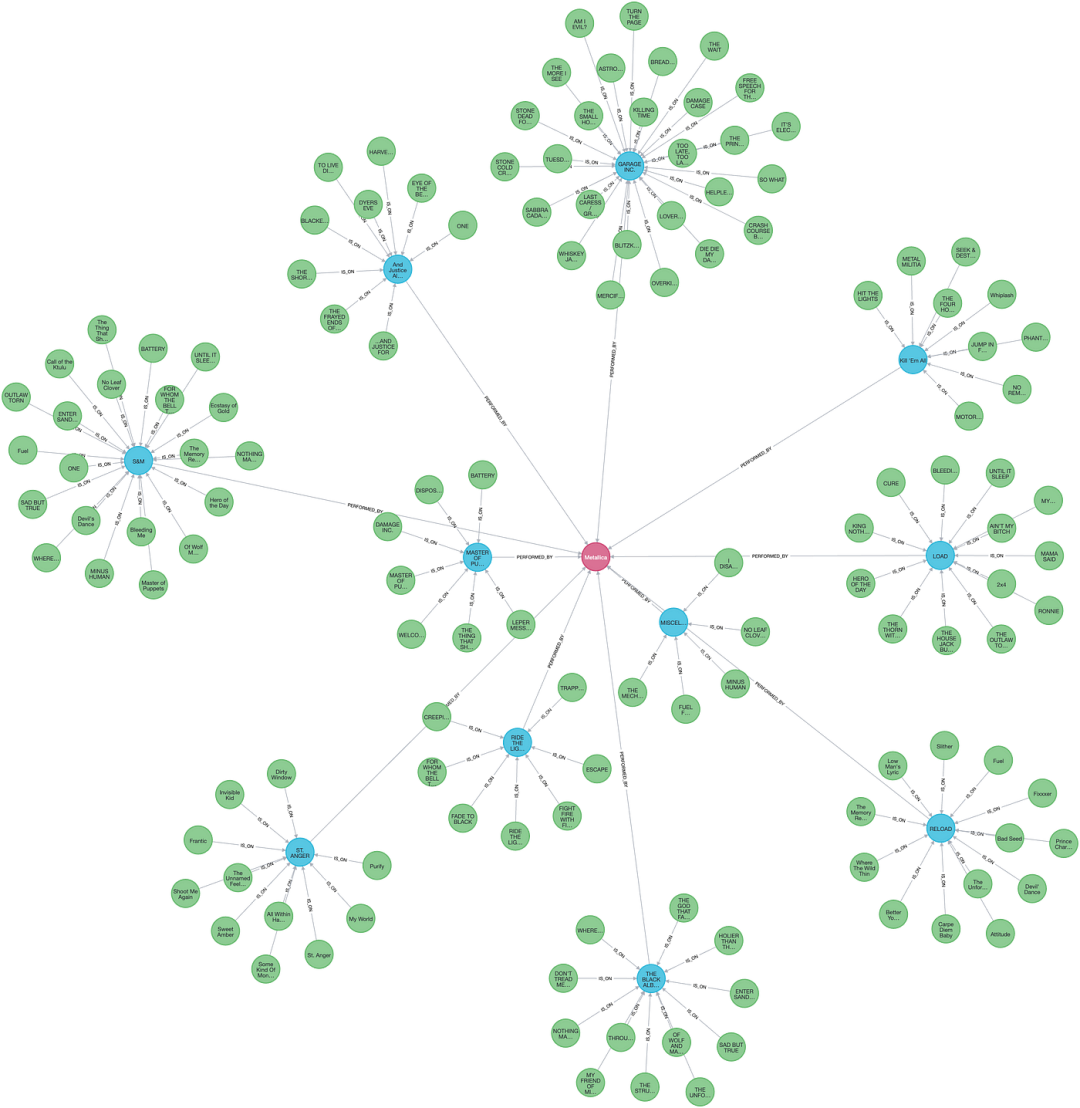
红色代表艺术家,蓝色代表专辑,绿色代表歌曲
如果你想为自己的测试复制这个数据集,你可以运行下面的代码来导入。当然,你也可以使用你自己喜欢的艺术家和歌曲,只要它遵循下面导入语句所暗示的相同架构。
LOAD CSV WITH HEADERS FROM 'https://drive.google.com/uc?export=download&id=1uD3h7xYxr9EoZ0Ggoh99JtQXa3AxtxyU' AS line
CREATE (song:Song {name: line.Song, lyrics: line.Lyrics})
MERGE (album:Album {name: line.Album})
MERGE (artist:Artist {name: line.Artist})
MERGE (song)-[:IS_ON]->(album)
MERGE (album)-[:PERFORMED_BY]->(artist)
现在我们有了数据库,首先需要在我们将用于向量的属性上创建一个向量索引。我们将这个属性称为 embedding,它位于 Song 节点上。1536 是向量的维度(记住,1536 是 OpenAI 使用的维度),最后一个属性 'cosine' 是用于相似度计算的算法。'cosine' 是通常推荐的算法。
CREATE VECTOR INDEX song_embeddings IF NOT EXISTS
FOR (s:Song) ON (s.embedding)
OPTIONS {
indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}
}
接下来,我们需要为每首歌添加歌词的向量嵌入。我们进行简单的 MATCH 来查找歌曲,然后将歌词属性字符串传递给嵌入函数。
MATCH (song:Song)
WITH song, genai.vector.encode(song.lyrics, "OpenAI", {token: $apiKey}) AS vector
CALL db.create.setNodeVectorProperty(song, "embedding", vector)
请注意,db.create.setNodeVectorProperty() 过程与 SET song.embedding = embedding 的作用相同,但使用这种方式存储向量时,数据格式会更加优化。
由于该查询会对数据库中的每首歌向 OpenAI 发起一个 API 调用,因此运行需要一些时间。还有一种替代方案是使用批量过程而不是上述函数,这样(在我们的例子中)只会发起一个 API 调用。
MATCH (song:Song)
WITH collect(song.lyrics) AS lyrics, collect(song) AS songs
CALL genai.vector.encodeBatch(lyrics, "OpenAI", {token: $apiKey}) YIELD index, resource, vector
CALL db.create.setNodeVectorProperty(songs[index], "embedding", vector)
这里的限制是一次批量调用可以包含的项目数量有限(在 OpenAI 的情况下为 2048),因此如果我们数据库中有 Metallica 之外的更多歌曲,我们需要分批处理,例如按艺术家或按专辑分批。
现在我们已经准备好进行歌词搜索。我们将搜索短语设置为一个名为 phrase 的参数,并且我们仍然有 apiKey 作为参数(在此不展示)。
:params
{
phrase: "A song about a guy who is so badly wounded in war so he no longer has any senses",
apiKey: "*****"
}
为了进行搜索,我们只需调用相同的函数为搜索短语生成向量嵌入,然后使用专门的过程在数据库中进行向量搜索,查找与嵌入最相似的歌曲。
WITH genai.vector.encode($phrase, "OpenAI", {token: $apiKey}) AS embedding
CALL db.index.vector.queryNodes('song_embeddings', 1, embedding) YIELD node AS song, score
RETURN song.name
这给了我们答案 DISPOSABLE HEROES。嗯,这并不是我们真正期望的。我们想到的是 ONE。Disposable Heroes 也是一首关于战争痛苦的歌曲,所以这是一个正确的答案,只是不是我们想要的那个。这并不是一门精确的科学。因此,通常最好请求多个匹配项的前几名。正确的答案通常在前 3-5 名结果中。queryNodes 的第二个参数是我们想要的结果数量,因此我们可以将其增加到 3。
WITH genai.vector.encode($phrase, "OpenAI", {token: $apiKey}) AS embedding
CALL db.index.vector.queryNodes('song_embeddings', 3, embedding) YIELD node AS song, score
RETURN song.name
现在,我们得到了以下结果。
DISPOSABLE HEROES
ONE
ONE
我们得到了正确的答案作为第二个匹配项。那么第三个匹配项呢?为什么我们得到了两次 ONE?因为它出现在多个专辑中,在我们建模的数据库中是重复的。
这就是知识图谱支持我们的解决方案时的强大之处。我们通过歌词找到了歌曲,但随后我们可以遍历图谱找到其他所有相关信息。
WITH genai.vector.encode($phrase, "OpenAI", {token: $apiKey}) AS embedding
CALL db.index.vector.queryNodes('song_embeddings', 3, embedding) YIELD node AS song, score
MATCH (song)-[:IS_ON]->(album:Album)-[:PERFORMED_BY]->(artist:Artist)
RETURN song.name AS Song, album.name AS Album, artist.name AS Artist
现在我们得到了
Song Album Artist
DISPOSABLE HEROES MASTER OF PUPPETS Metallica
ONE S&M Metallica
ONE And Justice For All.. Metallica
最后,我们只需再做一次测试以确保它正常工作。这次我们搜索:
关于一个男孩做噩梦的歌曲
结果是
Song Album Artist
Enter Sandman Black Album Metallica
Enter Sandman S&M Metallica
The thing that should not be MASTER OF PUPPETS Metallica
我想要的是 Enter Sandman,所以我认为这是成功的。
好了,我们用四行代码实现了一个智能的歌曲简介查找器!
学习资源
若要了解更多知识图谱或neo4j图数据库相关教学,你可以查看公众号的其他文章:
Neo4j+Milvus双剑合璧!打造更强大的GraphRAG知识图谱 Neo4j GraphRAG:1个Python包,轻松搞定RAG + 知识图谱! Neo4j + LangChain:如何构建基于知识图谱的最强RAG系统? 利用AI大模型,将任何文本语料转化为知识图谱,可本地运行 解读 Graph RAG:从大规模文档中发现规律,找到相互关系,速度更快,信息更全面! 利用LLM构建非结构化文本的知识图谱
活水智能成立于北京,致力于通过AI教育、AI软件和社群提高知识工作者生产力。中国AIGC产业联盟理事。
活水现有AI线下工作坊等10+门课程,15+AI软件上线,多款产品在研。知识星球中拥有2600+成员,涵盖大厂程序员、公司高管、律师等各类知识工作者。在北、上、广、深、杭、重庆等地均有线下组织。
双十一将至!新品上线,储值优惠、课程折扣、海量福利送不停!扫码加入福利群,提前锁定双十一专属优惠!
👇🏻👇🏻👇🏻

