




无论AI怎么进化,短期内有两个问题无法解决——幻觉与风格。
幻觉——骗我可以别太离谱
这世界本身充满了骗子,爱情骗子和AI骗子,区别在于——爱情骗子至少知道自己在撒谎,而AI却是无意识地编造。
幻觉指的是大模型输出看似合理但实际上不准确或完全虚构的信息。
幻觉来自什么?这不得不回到AI的本质——如果OpenAI继续采取现有的技术路径,幻觉这个问题永远无法在AI大模型内部解决,因为当前的AI的推理基于人类的语料,而不是基于真实世界。
换句话说,AI不是在理解世界,它是在“背书”,而且时不时还会背错。
同时,AI是一个概率机器,它的输出是基于统计相关性,而不是基于因果关系或真实世界的物理法则。即便它在某些情况下能够给出准确的信息,这也是因为它在海量数据中找到了与输入相关的模式,而不是因为它对问题有深入的理解。
那么,如何应对幻觉问题呢?RAG(Retrieval-Augmented Generation)。RAG通过将大模型与知识检索系统结合,使得AI在生成文本的过程中可以实时从外部知识库中检索相关信息。这一过程类似于人类在回答问题时查阅资料,从而显著减少了幻觉的发生。
简单来说,AI终于学会了“查字典”,不再完全靠“瞎编”。
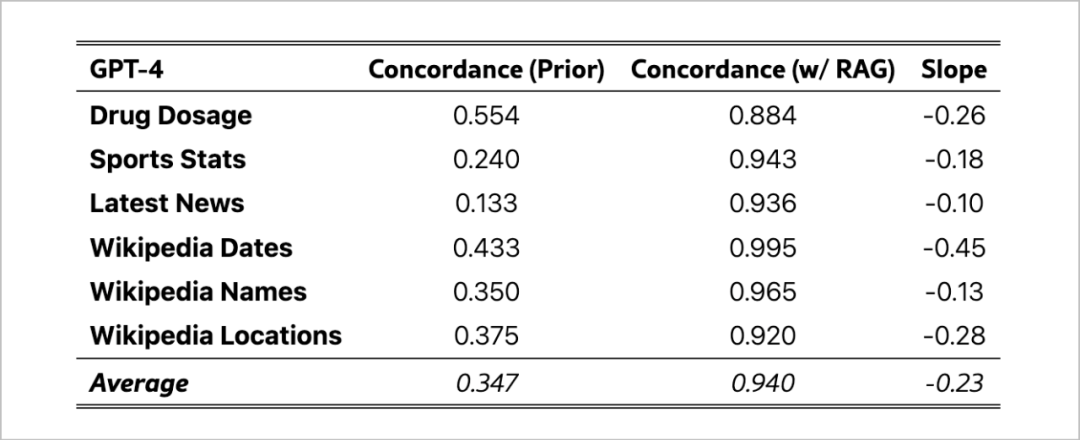
斯坦福大学的一项研究表明:在缺乏RAG技术的情况下,语言模型平均只能正确回答34.7%的问题。而在引入RAG后,准确率提升至94%。(arXiv:2404.10198v1)
它的基本原理是:先从外部知识库检索相关文本,再将其作为上下文输入生成模型,生成更准确的回答。这样,RAG不仅利用内部知识,还能实时获取外部信息,减少幻觉发生。
也许你觉得随着大模型的上下文窗口越来越长,我们就不用担心幻觉了,一口气给他一切相关的资料,自然就不担心幻觉,还需要使用RAG吗?
但最近的研究泼了一盆冷水。
NVIDIA的研究指出,长上下文模型在处理大量文本时效果并不理想,容易忽视关键信息,导致答案质量下降。研究表明,答案质量随检索文本片段增加呈倒U型曲线,说明长上下文模型无法完全取代RAG,尤其在需要精准回答的场景中。(arXiv:2409.01666v1)
RAG的好处是,它不再只靠模型自带的内容,而是能从外部数据源动态获取最新、最准确的信息。这样一来,AI的回答更靠谱,特别是在需要精准数据的场合。比如,AI回答用户的问题时、查询严肃资料时,RAG可以大大降低出错的几率。
RAG在市面上并不鲜见。从kimi、perplexity、chatgpt等产品的对话界面都能进行网络检索再回答问题,也可以上传文档进行提问。
但缺点,一是不永久,二是过程不可控,本身大模型已是黑箱,如果检索过程也被大模型公司牵着鼻子走,我们拉不开与周围人的差距,无法建立核心竞争力。AI可能会帮你找到答案,但它也可能顺便卖你一份广告。
实际上,对于有长期需求的用户,搭建一套自己的rag系统的成本并不高,有许多开源的项目已经有成型的框架,可以快速使用,我们只需要自定义那些最关键的数据即可,比如如何把长文本切块?使用什么方式检索?使用什么提示词返回?而这才是真正的关键差距。
风格——杀我别用感情刀
如果说幻觉是AI的“胡说八道”,那么风格问题就是它的“毫无个性”。
AI写的每一篇文章,都像是从同一个“流水线”上生产出来的,千篇一律,毫无灵魂。
当前的通用大模型,尽管能够模仿各种文体,但它的表达依然是基于已有的语料库,缺乏真正的原创性。换句话说,AI的风格是“借来的”,而不是“自发的”。
那么,我们可以等待AI支持快速个性化的那一天吗?可以,请你交钱吧,但可没那么简单,汽车、房子都有三六九等,大模型难道不行吗?给相近功能的产品做不同的定价,以区分开不同的阶层,这是人类最擅长做的事情。
但你又不能没有,就像房子和车子一样,文明社会用爱杀人,大模型是AI时代的地皮。
如何解决风格问题?这就引出了我们要讨论的第二个解决方案——微调大模型。
通过微调,我们可以针对特定领域或个性化需求对大模型进行定制化训练,使其在生成内容时更具风格化。就像给AI上了一堂“风格课”,希望它能从“千篇一律”变得“与众不同”。
微调的过程类似于一个作家在不断打磨自己的写作风格。通过反复调整模型的参数和输入数据,AI可以逐渐形成一种更贴近人类创作的风格,从而在特定领域中表现出更高的创造力和个性化表达。
那么,微调对普通人真的可以操作吗?当然可以,比起从头预训练一个模型,微调需要的数据量和训练成本非常低,相当于太阳和月亮的区别。
同样,在技术难度上,也有许多开源框架在不断降低普通人使用的门槛。技术发展的一个趋势,那就是工具越来越傻瓜。毕竟,即使是天才也追求高效,何必将精力浪费在不必要的细节上?
那这些工具所有人都能用,普通人又如何与其他人拉开差距?很简单,先使用,先积累,先占位,先迭代。这世界的本质,就是巨大的信息差,只不过是谁的草台班子先搭起来的区别。
微调的流程并不难理解:收集特定的语料并清洗,选择合适的基础模型和参数进行训练,最后验收测试。每个环节,也有许多开源工具问世。
当然,AI领域还处在鱼龙混杂的创业期,许多视频网站上有许多教程。但要发现最好的工具,最有效率的学习方式,没有专业的经验,仍然是个罗生门。
但我们相信,技术不应是少数人的专利。
本周日北京,AI线下工作坊二期:RAG 和 三期:微调大模型 即将开课(线上线下同步):
🕘 上午:学习如何通过 RAG 减少模型“幻觉”,提升生成内容的准确性。
🕑 下午:深入探索风格微调,手把手教学,帮助你真正掌握微调技巧。
通过 AI线下工作坊,我们希望帮助更多人轻松掌握这些关键技术。无论你是想优化AI的准确性,还是希望定制化AI的风格,我们的课程都能为你提供实战经验。不用担心那些实操中的各种细节,我们已经提前为你踩好了坑,你只需要带好电脑,跟着操作即可。

往期工作坊现场👆🏻
那你可以直接点击「阅读原文」,即刻报名!(添加小鱼儿企微,两期联报更优惠!)

