




本期将分享近期全球知识图谱相关
行业动态、近期会议、论文推荐
医疗语音AI助手
该平台已处理超1亿分钟医疗对话,被Fast Company评为2025全球最具创新力企业,标志着知识图谱技术在医疗合规AI领域取得关键突破。

工业故障诊断
日本大金与日立公司在大阪堺工厂启动生成式AI诊断系统商业化试验,其核心技术突破包括:1)将工厂设备图纸转化为可计算知识图谱,实现设备拓扑关系的数字化表达;2)融合历史维修记录与操作技术数据训练AI模型,诊断准确率达90%以上;3)现场工程师通过平板设备10秒内即可获取故障原因与解决方案。该系统基于日立Lumada物联网平台构建,此前在滋贺工厂钎焊产线已实现工艺优化验证。
该项目预计2025年9月完成测试,未来将推广至大金全球生产基地,标志着知识图谱技术在工业设备预测性维护领域进入规模化应用阶段。

www2025
自 1989 年万维网发明以来,Web 会议(前身为国际万维网会议,简称 WWW)是一年一度的国际学术会议,主题是万维网的未来发展方向。2025 ACM Web Conference 将于2025年4月28日-5月2日在悉尼举行,本次会议是一场面对面的会议,具有丰富的虚拟组件,包括主题演讲、口头报告、研讨会和教程的直播,以及访问预先录制的演讲视频,以及用于与所有与会者互动的 Whova 平台。

详情访问:https://www2025.thewebconf.org/
ICBAR 2025
第五届大数据、人工智能与风险管理国际学术会议(ICBAR2025)将于2025年5月09-11日在中国成都隆重举行。大会旨在为从事大数据、人工智能与风险管理科技研究的专家学者、工程技术人员、研发人员提供一个共享科研成果和前沿技术,了解学术发展趋势,拓宽研究思路,加强学术研究和探讨,促进学术成果产业化合作的平台。大会诚邀国内外高校、科研机构专家、学者、企业界人士及其他相关人员参会交流。

详情访问:https://www.ais.cn/attendees/index/2QAYBU

本周推荐的是arxiv 2025.3上的论文:Rethinking Graph Structure Learning in the Era of LLMs,作者来自北京科技大学和蚂蚁。

图结构学习 (GSL) 一直是提高图神经网络 (GNN) 性能的关键研究领域,尤其是在处理噪声或不完整的图数据时。 随着大型语言模型 (LLM) 的兴起,出现了一个利用其语言理解能力来增强图表示的机会,特别是对于节点包含丰富文本描述的文本属性图 (TAG)。
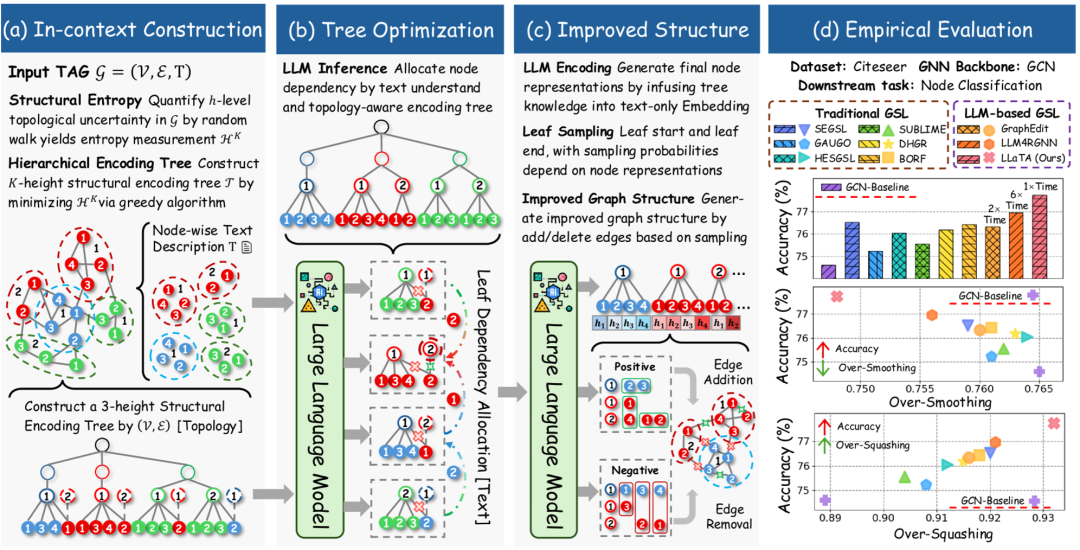
LLaTA 概述图 1:LLaTA 方法的概述,展示了上下文构建、树优化、改进的结构生成和实证评估。
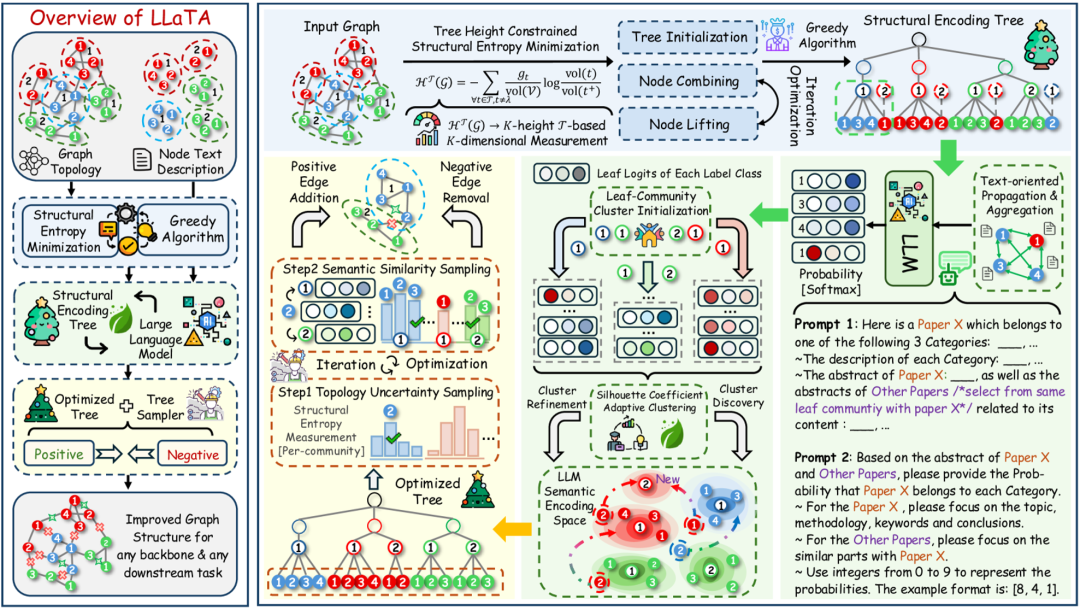
论文“LLM 时代重新思考图结构学习”介绍了 LLaTA(大型语言和树助手),这是一种新颖的方法,它从根本上重新构想了如何通过利用 LLM 的语义理解能力来学习图结构。 LLaTA 没有遵循专注于训练边预测器的传统 GSL 范式,而是提出了一种更高效、解耦且免训练的架构,该架构利用基于树的 LLM 上下文学习。
背景与动机
传统的 GSL 方法通常涉及学习添加、删除或重新加权图中的边,以提高下游任务的性能。 这些方法通常依赖于训练边预测器,以确定节点之间连接的可能性。 虽然有效,但它们在计算上可能很昂贵,并且可能无法充分利用 TAG 中可用的丰富文本信息。
最近将 LLM 集成到图学习中的尝试,例如 GraphEdit 和 LLM4RGNN,已经显示出希望,但仍保持了传统 GSL 范式的复杂性。 它们通常需要大量的微调或复杂的指令数据集,这可能耗费大量资源,并且可能无法充分利用 LLM 的上下文学习能力。
作者确定了研究领域的一个关键差距:需要一种 GSL 框架,该框架可以有效地利用 LLM,同时避免不必要的计算开销。 这推动了 LLaTA 的开发,它将 GSL 目标从训练边预测器重新定义为构建语言感知的树采样器。
LLaTA 方法
LLaTA 通过提出三个关键创新,代表了 GSL 的范式转变:
1. 重新定义 GSL 目标:LLaTA 没有训练边预测器,而是专注于构建一个语言感知的树采样器,该采样器捕获拓扑和语义信息。
2. 解耦且免训练的模型设计:LLaTA 将图学习过程与特定的 GNN 主干分离,使其可以应用于各种下游模型,而无需进行大量的微调。
3. 基于树的 LLM 上下文学习:LLaTA 利用分层编码树为 LLM 提供结构上下文,使其能够更好地理解拓扑和文本关系。
论文、讨论链接:https://www.alphaxiv.org/overview/2503.21223,感兴趣的读者可以关注。
更多链接
内容:袁知秋、程湘婷、王图图

诚邀您加入我们的gStore社区,我们将在群内解决使用问题,分享最新成果~
请在微信公众号图谱学苑发送“社区”入群~

微信社区群:请回复“社区”获取
