




点击上方“IT那活儿”公众号--专注于企业全栈运维技术分享,不管IT什么活儿,干就完了!!!
问题现象
在安装部署Kubernetes 1.26版本时,通过kubeadm初始化集群后,发现执行kubectl命令报以下错误:

问题排查
查看kubelet状态是否正常,发现无法连接apiserver的6443端口:

进而查看apiserver容器的状态,由于是基于containerd作为容器运行时,此时kubectl不可用的情况下,使用crictl ps -a命令可以查看所有容器的情况:
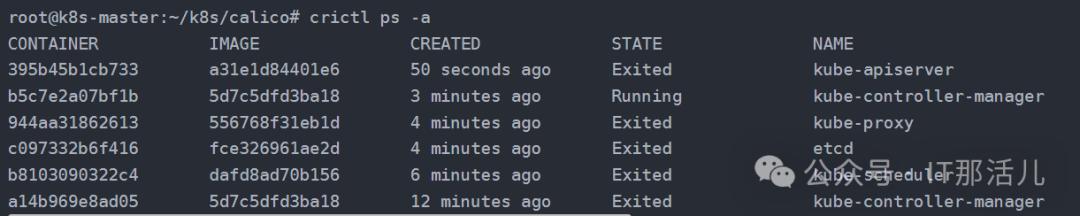
发现此时kube-apiserver容器已经退出,查看容器日志是否有异常信息。
通过日志信息发现是kube-apiserver无法连接etcd的2379端口,那么问题应该是出在etcd了:
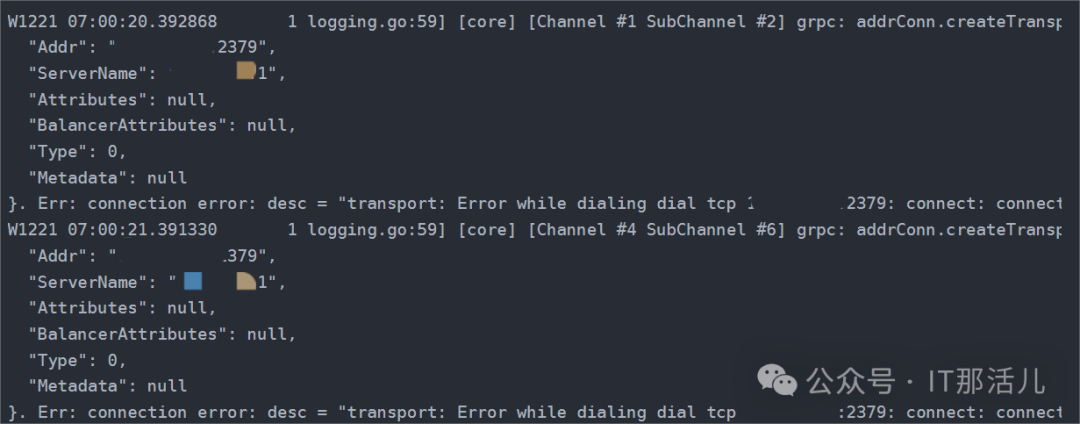
此时etcd容器也在不断地重启,查看其日志发现没有错误级别的信息:
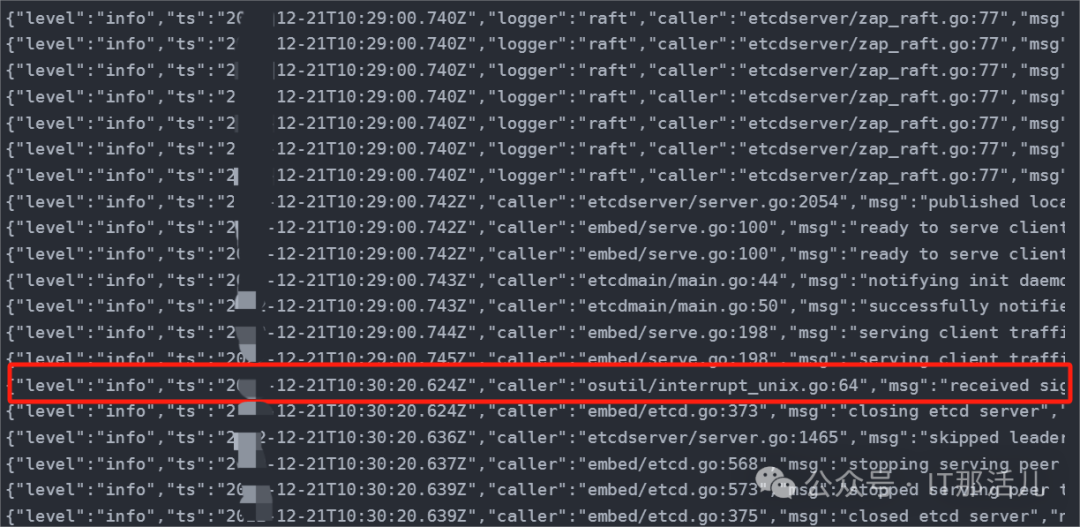
但是,其中一行日志信息表示etcd收到了关闭的信号,并不是异常退出的:
{"level":"info","ts":"20XX-12-21T10:30:20.624Z","caller":"osutil/interrupt_unix.go:64","msg":"received signal; shutting down","signal":"terminated"}
问题处理
该问题为未正确设置cgroups导致,在containerd的配置文件/etc/containerd/config.toml中,修改SystemdCgroup配置为true:
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
BinaryName = ""
CriuImagePath = ""
CriuPath = ""
CriuWorkPath = ""
IoGid = 0
IoUid = 0
NoNewKeyring = false
NoPivotRoot = false
Root = ""
ShimCgroup = ""
SystemdCgroup = true
重启containerd服务或docker服务:
systemctl restart containerd
etcd容器不再重启,其他容器也恢复正常,问题解决。
本文作者:张志彪(上海新炬中北团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
