




点击蓝字 关注我们

Oracle 字符集为 ASCII,如果想要同步数据到 Doris,就会出现中文乱码问题。那么出现这个问题该怎么办呢?实际上有办法解决。
解决思路
数据从数据库读取到Source的时候去处理,也就是从ResultSet 里面获取数据的时候,去重新编码
先下载好 2.3.9 版本的 SeaTunnel 源码,进入到seatunnel-connectors-v2
下的connector-jdbc
模块
SeaTunnel 读取数据的流程大致如下:
JdbcSourceFactory 会加载我们的 source 配置参数,构建 JdbcSourceConfig、JdbcDialect,创建 JdbSource。
JdbSource 任务处理
JdbSource 会创建 SourceSplitEnumerator 去拆分任务,然后创建 JdbcSourceReader 根据拆分去执行任务。
JdbcSourceReader 数据处理
JdbcSourceReader 会构建 JdbcInputFormat,走 pollNext 方法去循环处理数据。
pollNext 方法执行步骤
JdbcSourceReader 的 pollNext 方法会先调用 JdbcInputFormat 的 open 方法获取 ParpareStatement 和 ResultSet 等信息,然后调用 JdbcInputFormat 的 nextRecord 方法去处理 ResultSet,把数据格式转换成 SeaTunnel 需要 SeaTunnelRow。
nextRecord 方法处理
JdbcInputFormat 的 nextRecord 会调用 JdbcRowConverter 的 toInternal 方法处理 ResultSet,JdbcRowConverter 的实现类 AbstractJdbcRowConverter,是我们需要修改的(针对于 Oracle 数据库)。
问题及解决思路
进入到 AbstractJdbcRowConverter 的 toInternal 方法,发现在处理 String 类型字段时:它默认是 JdbcFieldTypeUtils.getString (rs, resultSetIndex),这一步拿到的数据就已经乱码了。我们需要修改为 JdbcFieldTypeUtils.getBytes (rs, resultSetIndex),然后根据字节数组去重新编码。
解决方案
下面给出我们的解决方案:
针对于 Oracle 字符集可以存储中文的情况,没有必要先得到字节数组,再重新编码,直接 getString 是可以的
为此我们需要一个开关,来判断是否需要转码
在JdbcInputFormat
类里面,我们加上一个 params 的参数:
private final Map<String, String> params;
在JdbcInputFormat
构造方法里,为这个参数附上值:
public JdbcInputFormat(JdbcSourceConfig config, Map<TablePath, CatalogTable> tables) {this.jdbcDialect = JdbcDialectLoader.load(config.getJdbcConnectionConfig().getUrl(),config.getCompatibleMode());this.chunkSplitter = ChunkSplitter.create(config);this.jdbcRowConverter = jdbcDialect.getRowConverter();this.tables = tables;// 在此处把去得到 properties 的参数信息this.params = config.getJdbcConnectionConfig().getProperties();}
然后在JdbcInputFormat
的nextRecord
方法里的 jdbcRowConverter
的toInternal
方法,增加一个 params 参数:
// 这里比原来多传递了一个 params 参数,用于做是否转码的处理SeaTunnelRow seaTunnelRow = jdbcRowConverter.toInternal(resultSet, splitTableSchema, params);
接着到实现类AbstractJdbcRowConverter
添加一个编码的方法:
public static String convertCharset(byte[] value, String charSet) {if (value == null || value.length == 0) {return null;}log.info("value code is ::::{}", Arrays.toString(value));try {return new String(value, charSet);} catch (UnsupportedEncodingException e) {throw new RuntimeException(e);}}
case STRING:// params 的 sourceCharset 存在且值为 GBK,我才去转码,否则就走默认的 getString()if (params == null || params.isEmpty()) {fields[fieldIndex] = JdbcFieldTypeUtils.getString(rs, resultSetIndex);} else {String sourceCharset = params.get("sourceCharset");if ("GBK".equalsIgnoreCase(sourceCharset)) {fields[fieldIndex] = convertCharset(JdbcFieldTypeUtils.getBytes(rs, resultSetIndex), sourceCharset);} else {fields[fieldIndex] = JdbcFieldTypeUtils.getString(rs, resultSetIndex);}}break;
修改完之后需要把connector-jdbc
重新打包,替换掉 seatunnel 的connectors 目录下的connector-jdbc-2.3.9.jar
,然后重启集群即可。
我们的配置参数脚本:
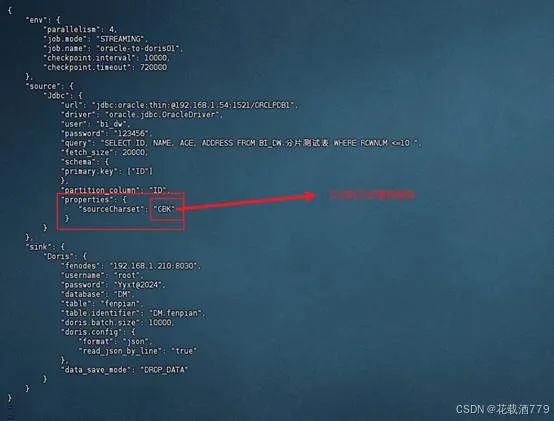
如果 Oracle 不存在乱码的情况,这个properties 就不需要传递
ps:如果您在connector-jdbc
里面打印信息,请到 seatunnel 的 logs 目录下,去查看你的 worker节点日志信息。
转载自花载酒779
原文链接:https://blog.csdn.net/m0_66532138/article/details/146957750
Apache SeaTunnel
Apache SeaTunnel是一个云原生的高性能海量数据集成工具。北京时间 2023 年 6 月1 日,全球最大的开源软件基金会ApacheSoftware Foundation正式宣布Apache SeaTunnel毕业成为Apache顶级项目。目前,SeaTunnel在GitHub上Star数量已达8k+,社区达到6000+人规模。SeaTunnel支持在云数据库、本地数据源、SaaS、大模型等170多种数据源之间进行数据实时和批量同步,支持CDC、DDL变更、整库同步等功能,更是可以和大模型打通,让大模型链接企业内部的数据。
同步Demo
新手入门

最佳实践

测试报告

源码解析
Apache SeaTunnel



