




本文对华东师范大学蔡鹏教授团队、PingCAP刘奇、唐刘等人联合编写的2024 VLDB论文《AutoTQA: Towards Autonomous Tabular Question Answering through Multi-Agent Large Language Models》进行解读,全文共8238字,预计阅读需要15至25分钟。
随着数据分析日益重要,许多研究致力于从表格中为用户的自然语言问题提供精确答案,这一任务被称为表格问答(Tabular Question Answering,TQA)。现有最先进的TQA方法主要只能处理单表问题。然而,现实世界中的TQA问题往往非常复杂,涉及多个表格,这使得现有的单表TQA方法难以直接扩展,根本原因在于其大多缺乏良好的可扩展性。本文提出了AutoTQA,一个新型的自主式表格问答框架,它基于多智能体大语言模型(multi-agent LLMs),支持跨多种系统(如TiDB、BigQuery)处理多个表格。AutoTQA由五个智能体组成:User(接收用户的自然语言问题);Planner(为问题制定执行计划);Engineer(按步骤执行该计划);Executor(提供多种执行环境以完成指定的任务);Critic(判断任务是否完成,并识别当前结果与原始目标之间的差距)。
为促进不同智能体之间的协作,作者还设计了智能体调度算法。此外开发了开源可视化低代码工具LinguFlow,以加速构建和调试基于LLM的应用程序,便于外部工具与执行环境的快速创建。文章还实现了一系列数据连接器,使AutoTQA能够访问来自多系统的表格。
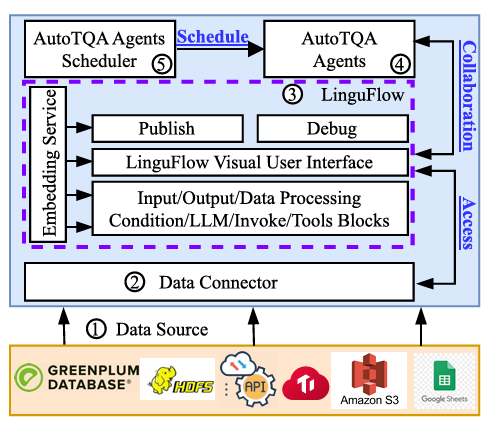
AutoTQA架构
1.研究背景与动机
1.1大语言模型给表格问答任务带来的可能性和挑战
表格问答(TQA)是数据分析中的关键任务,其目标是对用户的自然语言查询,从表格中提供精准答案。实际应用中,表格常用于财报、统计报告等场景。处理这类任务通常需要具备数据分析专业知识,但TQA的出现使用户无需精通自然语言处理或数据分析即可获得答案。
在现实中,表格形态复杂,包括关系型数据库(RDB)表(结构化表)与网页表格(半结构化)。此外,TQA任务常常涉及多个表之间的操作,例如关联(Join)、集合操作(Set operations)等。构建一个可适用于各种TQA场景的统一框架,是当前数据分析与自然语言处理领域的研究热点。
大语言模型(LLMs)如ChatGPT、BLOOM、LLaMA等近年来快速发展,具备强大的零样本(zero-shot)语言理解能力。然而,在数据分析等领域,由于缺乏领域训练,它们可能产生不准确答案,无法被完全依赖。大语言模型的出现给予表格问答任务更多的可能性和挑战。
1.2现阶段表格问答方法的局限性
目前研究中先进的TQA方法具有以下的局限性:
缺乏多表TQA的有效解决方案:现有方法多聚焦于单表处理,只能够从单个表格中就行特定的数据分析。无法完成需要关联多个表的信息检索任务。
未充分挖掘LLM潜力:一些研究如ReAcTable结合了Chain-of-Thought和ReAct的LLM范式来解决TQA,但仍存在空答案难判别、处理大表困难等问题,且对LLM的对话学习能力未加以利用。
缺乏多系统多表处理能力:现如今的TQA方法对于同时处理结构化表格和半结构化表格时具有挑战性。现实中表格可能来自MySQL、S3、API等多个来源,现有方法依赖繁琐的ETL预处理流程,增加了操作复杂性与资源开销。
1.3提出AutoTQA的动机
为了解决上述TQA方法的局限性,首先对于LLM中的TQA方法具有以下关键技术挑战:
如何设计统一框架,处理单表与多表 TQA?
如何充分挖掘 LLM 的能力以验证并生成正确答案?
如何高效管理多个系统中的不同表格?
基于上述挑战,作者提出了AutoTQA,一个基于多智能体LLM的自主式表格问答框架。为前两个个挑战构建了多智能体架构,包括:User(接收问题);Planner(制定计划);Engineer(执行计划);Executor(调用LLM应用);Critic(判断任务是否完成并回溯)。同时设计了三种智能体调度算法,以提升任务协调精度;为第3个挑战,AutoTQA基于Trino实现了多系统数据连接器,允许使用单查询来访问多个来源表格。
为了解决因快速构建和调试基于LLM的应用程序而带来的挑战,作者还构建了LinguFlow,作为一款开源低代码开发工具,便于开发者快速构建、调试和部署LLM用。
2.1表格问答任务
表格问答(Tabular Question Answering,简称TQA):是自然语言处理(NLP)与数据库领域数据分析中的重要研究方向。通常,数据分析员或用户需要探索一系列表格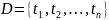 ,其中
,其中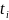 表示存储在任意位置的表格。随后,数据分析员需对特定表格执行一系列数据转换操作
表示存储在任意位置的表格。随后,数据分析员需对特定表格执行一系列数据转换操作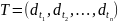 ,其中
,其中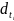 表示一次数据转换操作。
表示一次数据转换操作。
在每次数据转换之后,分析员需要判断是否继续执行下一步转换,或者当前结果是否已经能回答用户的问题。如果是,则探索过程终止。
在数据转换过程中,分析员通常会使用诸如Python或SQL等数据处理工具,因此需要具备一定的Python或SQL编程能力。
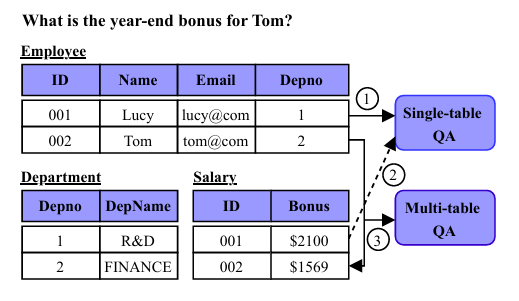
TQA任务示例
举例来说,当用户提出问题“Tom的年终奖金是多少?”时,数据分析员首先识别出需要从Employee表和Salary表中提取相关答案。随后,分析员在两张表之间执行连接(join)操作,即join(Employee, Salary),然后判断查询结果是否能够解答问题。
在更复杂的TQA场景中,可能还需要进行集合操作(Set)、嵌套查询(Nested Queries)、正则表达式(Regex)处理等复杂的数据转换步骤。即使在单个查询中,也常常需要执行多轮复杂操作才能得出正确答案。TQA任务的最终的输出形式多种多样,可以直接将表格中提取的结果返回给用户,如:单一数值(即单行单列表);表格形式(多行多列表);或者从表格中抽取结果并用自然语言进行理解与描述。此外,还可以根据预定义的答案格式,让数据分析员根据特定格式将结果填充至特定表单,再返回给用户。
2.2大语言模型
(1)大语言模型(LLMs):是通过海量文本数据训练而成的先进人工智能系统,旨在理解和生成类人语言。许多主流LLM(如ChatGPT、BLOOM、LLaMA)基于深度神经网络构建。其中一个关键技术是注意力机制(Attention Mechanism),它使得模型在生成输出时能够聚焦于输入文本的不同部分,对输入序列的不同部分赋予不同权重,显著增强模型对上下文和关系的捕捉能力。模型的架构通常包含多层互联神经元,通过训练过程不断调整连接权重与偏置,以最小化预测值与真实输出值之间的差异。
(2)LLM 提示工程(Prompting):提示是一种灵活技术,通过在输入中添加提示信息,引导LLM给出定制化响应,无需重新训练模型。提示可以手动设计,也可以通过数据自动学习获得。常见的提示技术包括:零样本提示、小样本提示、小样本提示等方法。
(3)LLM 智能体(LLM Agent):LLM智能体是将LLM与关键模块(如规划与记忆)结合,执行复杂任务的应用系统。在这种设计中,LLM担任智能体的“控制器”或者“大脑”,以掌管任务执行的各个步骤与流程或者响应用户的请求。LLM智能体主要通过整合LLM与策略性组件(如规划与记忆组件)来执行复杂任务。
AutoTQA架构
3.1 AutoTQA 的整体架构
根据AutoTQA的整体架构图可以看出,其核心组成部分主要有以下几块:
(1)数据源(Data Source):在AutoTQA中,对表格数据来源不做限制,无论是分布式数据库(如TiDB、Greenplum),分布式文件系统(如HDFS),还是电子表格(如Google Sheets)格式的存储。在PingCAP的实际应用中,部分表存储在BigQuery和TiDB,而一些实时数据则通过API直接访问。如果将所有数据迁移到统一系统,其代价高昂且不可行。因此,AutoTQA保持了所有表格数据的原始存储位置,通过数据连接器展现各数据源的元数据,以及抽象了多系统交互的复杂性。
(2)数据连接器(Data Connector):数据连接器作为关键组件,使得不同数据源的无缝整合,充当基于LLM应用(或执行环境)与数据源之间的中间层。这些连接器支持多种数据源,如TiDB、PostgreSQL、本地文件、Google Sheets、Apache Thrift 及各种API。其核心功能是简化不同存储系统的数据交互流程,同时为用户提供统一接口,从而轻松操作并整合多源数据,增强异构环境下的数据互操作性与分析处理能力。
(3)LinguFlow:AutoTQA采用了ReAct范式,需要与外部工具(例如text-to-SQL)交互以完成Engineer分配的任务。因此,AutoTQA提出了LinguFlow作为一款开源的可视化低代码开发工具,旨在加速基于LLM应用的开发、调试与部署。LinguFlow的核心是低代码架构,开发者可以通过基于有向无环图(DAG)的消息流方式组织业务逻辑,大幅降低LLM应用开发门槛。此外,LinguFlow内置了嵌入式服务,通过少样本提示技术优化LLM应用的准确性与正确率。
(4)AutoTQA智能体(AutoTQA Agents):AutoTQA中的LLM智能体承担特定职责,包括五个不同的智能体,即User、Planner、Engineer、Executor和Critic。每个智能体在TQA任务中都有各自的角色,它们的协作对于完成任务至关重要。它们也被称为“数字员工小组”。
(5)AutoTQA智能体调度器(AutoTQA Agents Scheduler):AutoTQA在TQA任务中的有效性高度依赖于智能体调度机制。系统为智能体交互设置了最大轮次数限制,达到阈值时终止交互。为优化智能体协作效率,文章中设计了三种调度器:基于循环滚动的调度器(Circular Rolling-based Scheduler);基于LLM理解功能描述的调度器(LLM-based Scheduler);基于有限状态机的调度器(Finite-State Machine-based Scheduler)。不同调度器在任务分配方式与性能表现上有所差异,直接影响任务准确率与执行开销。
3.2 AutoTQA 的执行流程

AutoTQA的一个执行流程
如图展示了AutoTQA如何通过Planner和Engineer制定执行计划,并如何通过Executor调用外部LLM应用完成任务,同时Critic负责评估任务完成度。主要有以下步骤:
1. User提交问题。如提交“分析2024年1月10日用户Eugene的账单记录。”这个问题。
2. Planner根据用户输入制定初步执行计划,确定该任务共包含九个子步骤(图中➀所示)。考虑到PingCAP业务场景的复杂,User在输入中引入了部分标准操作流程(SOP),帮Planner制定合理计划。
3.计划通过内嵌的基于有限状态机的调度器分配给Engineer。
4. Engineer按步骤执行计划,细化每个子步骤,并指定需调用的外部应用,随后将任务交由Executor执行。
5. Executor调用指定工具,执行Engineer分配的任务。当需要撰写SQL/Python代码或进行数值计算时,Engineer将具体任务委派给Executor,避免直接与外部工具绑定,从而便于各部分独立调试与优化。
在PingCAP实践中,为了完成计划,主要步骤如下:
1. Engineer与Executor之间会进行多轮交互以完成计划(图中➁所示),同时调度器指挥Critic评估任务完成情况。
2.若Critic判定任务未完成,则根据当前执行上下文与初始任务描述,识别差距GAP与未完成任务(图中➂所示),并指派Planner修正执行计划(图中➃所示)。
3.新的执行计划将继续由Engineer和Executor依次执行,并且调度器动态选择合适的下一个智能体(图中➄所示)。
4.最终由Critic总结结果并返回给用户,形成完整闭环(图中➅所示)。
在实际应用中,任务通常涉及多轮迭代。在PingCAP实践中根据精度与成本权衡设置了最大交互轮次限制。值得注意的是,交互轮数越多,LLM理解长上下文的错误概率也会上升。
4.1数据连接器
为了支持TQA任务中跨多表操作,核心组件是数据连接器。数据连接器的主要功能是将任意外部数据源注册到Trino中。在具体实现中,为了获取实时数据更新,AutoTQA直接通过API抽取数据,并将其注册到一个统一接口中,选择Trino作为中间统一格式。
接口实现包括以下五个部分:
ListSchemaNames:注册数据库列表。
ListTables:注册指定数据库的表的列表。
GetTableMetadata:注册表格的特定元数据,如列名、数据类型和索引键。
GetSplit:根据查询需求检索若干数据块(split),用于后续按块提取完整行数据。
GetRows:根据指定split提取所有行数据。
对于存储在其他系统或文件中的表格,TQA任务用户只需实现上述五个接口,即可自定义数据连接器,大大降低了ETL成本。通过实现这五个接口,可以屏蔽不同数据源间的差异,使得在单次查询中方便地操作多种表格。同时,在Executor调用text-to-SQL应用时,会自动生成Trino SQL,以抽象底层系统的复杂性。总结来说,数据连接器的将所有必要的表格元数据映射到一个统一的Trino接口,从而支持跨多个系统、跨多个表格的单次查询操作。
4.2 LinguFlow:一款基于LLM应用的低代码工具的开发
有向无环图DAG是LinguFlow中消息流的抽象,代表了应用的业务逻辑,由节点与边组成。在LinguFlow中,每个节点代表一个实例化的模块,是一个核心单元。节点用于将复杂的LLM应用拆解为可复用模块,使开发者可以根据业务逻辑自由选取与组织这些模块。遵循开发规范的模块会被注册到模块注册中心中;开发者可以快速理解各模块的输入/输出与功能定义,并将其迅速实例化为DAG中的节点。
LinguFlow支持六种模块类型:输入/输出模块、数据处理模块、条件判断模块、LLMs模块、外部应用调用模块和工具模块。使用LinguFlow开发的应用可一键部署至云端,同时支持在线运行与调试功能。最终,AutoTQA可以通过URL直接调用云端部署的外部应用。
LinguFlow还集成了嵌入式服务(Embedding Service),以提升少样本提示(Few-shot Prompting)下的LLM应用性能。为了达到这个目的,嵌入式服务通过不同场景使用namespace来隔离语料库,并支持upsert操作新增或更新示例,能够通过embedding查询返回top-k相关数据,并支持根据唯一ID删除数据。嵌入式服务还提供了选择少样本示例的灵活性。
4.3 AutoTQA 智能体与调度器
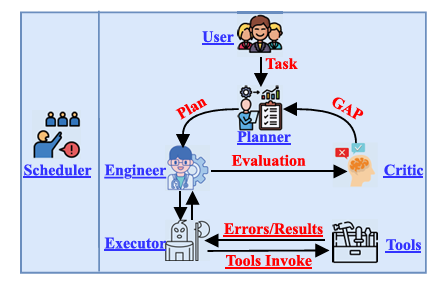
AutoTQA的五个智能体和一个调度器
AutoTQA的中心组件是智能体(Agent),用于保障用户提问的准确应答。各智能体按功能分工协同工作。其中,AutoTQA包括以下五个智能体:
User:接收用户自然语言任务描述;
Planner:将任务拆解为可执行的细粒度子任务;
Engineer:基于上下文细化并逐步执行子任务;
Executor:执行与外部应用的交互,并与Engineer之间会进行多轮交互以完成计划;
Critic:评估任务是否完成,发现差距(GAP),报告给Planner就行新的任务修订。
根据图中所示,智能体交互的初步执行流程为:
1.用户提交问题后,Planner根据任务制定执行计划;
2. Engineer 接收子任务并逐步实现,并调用外部应用时委派给Executor;
3. Executor 完成后将结果返回给Engineer;
4. Critic 评估当前任务完成情况,若存在GAP,重新反馈给Planner修正。
AutoTQA中的智能体调度器旨在有效调度不同的智能体,最小化成本的同时能够最大化TQA任务的准确率,其中包含三种调度算法:
循环滚动调度器:使用静态调度序列,调度器分配代理以按照给定的顺序执行各自的任务。在算法中,生成了一个专用的调度队列。其中,排除User对调度器至关重要,因为它负责提交用户指定的问题。随后,如果当前任务仍然未完成并且该回合没有超过最大限制,使用循环滚动机制从调度队列中选next_agent。但是,这种调度算法不能在指定的最大循环次数内达到正确的结果。AutoTQA不能依赖于静态序列来实现正确的代理调度。
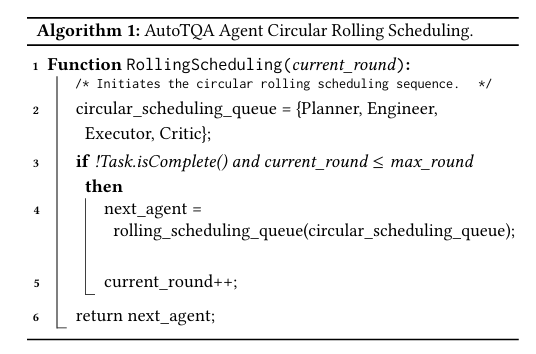
循环滚动调度器
基于LLM理解功能描述的调度器:这是一种动态调度算法,依据智能体功能描述与对话上下文动态选择下一步智能体。基于LLM的调度器在一定程度上会生成不符合预期的调度序列。这主要是由于对会话上下文的误解。

基于LLM理解功能描述的调度器
有限状态机(FSM-based)调度器:算法中,将各智能体建模为有限状态机FSM中的状态,通过定义转移规则,以确保智能调度。当条件满足时,它触发FSM中的进入动作。当动作完成时,AutoTQA从一个智能体切换到另一个智能体。这里,每个智能体的职能将作为过渡条件(或事件)。当当前任务需要具有特定职责的代理时,该算法将智能体的调度信息与智能体的职能相分离。
基于有限状态机的调度算法减少了根据会话上下文推断next_agent的开销,在AutoTQA设计的智能体函数的基础上,建立predecessor和successor智能体的关系,并定义它们之间的调度,保证了调度过程的高效和准确。

AutoTQA的基于有限状态机的调度器
4.4讨论
(1)异常处理与重试机制:当Engineer将SQL或Python编程任务交由Executor执行时,Executor会初始化相应代码执行环境,并通过数据连接器分发SQL操作至底层系统。在此过程中,需特别处理两类异常情况:
执行器返回错误:错误常因表或列信息召回错误引发,需要启动重试机制;
执行器返回空值:空值不一定意味着结果为空,可能由于查询条件问题。在此情况下,系统会收集类似错误信息并反馈给 Engineer,作为通用知识积累,以便在重试中进一步优化查询。
本章节通过四个具有代表性的基准数据集,对AutoTQA的设计进行系统性实证评估,主要关注以下研究问题:
RQ1:AutoTQA在单表TQA任务中的准确率相比现有方法表现如何?
RQ2:AutoTQA 在多表TQA任务(以企业数据集为代表)中的准确率表现如何?
RQ3:AutoTQA中不同智能体调度算法对TQA任务准确率有何影响?
RQ4:嵌入式服务(few-shot prompting)对准确率有何影响?
5.1实验设置
5.1.1大语言模型(LLMs)
本实验中使用的LLM包括:
GPT-4-0613(简称GPT-4);
GPT-4-1106-preview(简称GPT-4-turbo);
GPT-3.5-turbo-16k(简称GPT-3.5-turbo)。
所有模型统一将温度参数设为0,以优先保证可复现性。在实验中,AutoTQA的最大交互轮次数、被设置为50轮,使用FSM-based(有限状态机)智能体调度器。
5.1.2数据集
本实验使用了四个数据集,包括三个公开数据集和一个来自PingCAP真实业务的数据集:
WiKiTQ:单表TQA的代表性数据集,包含18,496个复杂问题,需多步推理及各种数据操作(比较、聚合、算术计算等);
FeTaQA:源自维基百科,自由形式回答,包含9,329个问题-答案对;
TabFact:大规模手工标注数据集,关系被分类为true或false,主要用于评估结构化数据上的语言推理能力,使用小规模测试集(1,998个问题);
企业数据集:来自PingCAP真实业务场景。
5.1.3评价指标
实验中对于四个数据集,将以下度量统称为准确性:
对于WikiTQ,指标是Accuracy;
对于FeTaQA,使用ROUGE-1,ROUGE-2和ROUGE-L指标;
对于TabFact,评估指标是字符串匹配;
对于企业数据集,标准度量是结果准确性。
5.1.4基线
实验中采用以下基线与AutoTQA进行对比:Codex,Binder,Dater,ReAcTable,ReAcTable(GPT-3.5-turbo),ReAcTable (GPT-4),ReAcTable(GPT-4-turbo),AutoTQA(GPT-3.5-turbo),AutoTQA(GPT-4),和AutoTQA(GPT-4-turbo)。
5.2单表任务评估
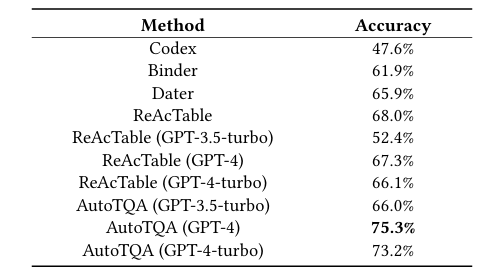
在WikiTQ数据集上的结果
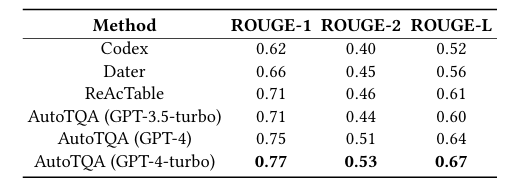
在FeTaQA数据集上的结果
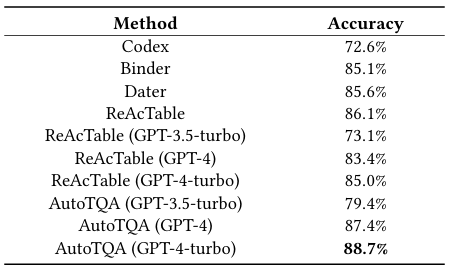
在TabFact数据集上的结果
为回答RQ1,实验在WiKiTQ、FeTaQA和TabFact三个单表基准数据集上,评估不同方法在TQA单表任务中的表现。可以看出,在三种数据集上,AutoTQA都优于其他的所有基线。其中,在WiKiTQ上,AutoTQA(GPT-4-turbo)相比ReAcTable(GPT-4-turbo)有5.2%的准确率提升;在FeTaQA上,AutoTQA(GPT-4-turbo)在ROUGE指标上全面优于ReAcTable;在TabFact上,AutoTQA(GPT-4-turbo)准确率达到88.7%,超越所有对比方法。这主要是由于,使用更强推理能力(如GPT-4/GPT-4-turbo)的基础模型,能更好发挥AutoTQA的智能体协作能力。同时AutoTQA通过智能体循环调度与错误重试机制,显著提升了推理深度与准确率。
*Finding:与其他基于LLM的方法相比,AutoTQA通过利用强大的GPT-4和GPT-4-turbo模型获得了卓越的性能。这主要是由于AutoTQA的代理设计(例如代理调度和重试机制),它充分利用了LLM从对话上下文中推理和学习的能力。同时,它还可以利用强大的外部应用程序。
5.3多表任务评估
为回答RQ2,实验在本节中使用PingCAP的企业数据集,来评估AutoTQA在多表TQA任务中的准确率表现。由于Binder、Dater和ReAcTable等方法不支持多表操作,因此实验中仅评估AutoTQA(基于不同LLM)的情况。

在企业数据集上的结果
实验结果表明,AutoTQA(GPT-4-turbo)的准确率为80.0%,AutoTQA(GPT-4)为85.0%,AutoTQA(GPT-3.5-turbo)仅为45.0%。这主要是因为,工业数据集涉及复杂表间连接(Join)、规整(Normalization)等操作,GPT-4相比GPT-3.5-turbo拥有更强推理与复杂任务处理能力。同时,AutoTQA的智能体设计(尤其是计划生成与错误回溯机制)有效提升了多表任务表现。
*Finding:在要求严格的多表TQA任务的实际场景中,AutoTQA表现出了显著的性能。这突显了AutoTQA在各种TQA场景中实现最佳性能的能力。在处理复杂的企业TQA任务时,配置了GPT-4-turbo的AutoTQA可以达到更佳的精度水平,还为企业提供了更具成本效益的解决方案。
5.4调度算法对准确率的影响
为回答RQ3,本节实验在企业数据集上,评估不同智能体调度算法对AutoTQA准确率的影响。
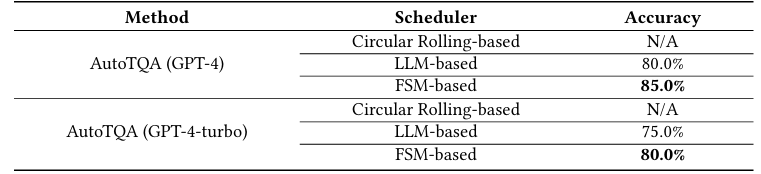
调度算法对准确率的影响结果
实验发现,采用循环滚动调度时,无论GPT-4还是GPT-4-turbo,均无法在最大轮次数内给出正确答案;而采用LLM-based调度和FSM-based调度时,性能显著提升,并且使用FSM-based调度更好。LLM-based调度器比FSM-based调度器准确率要低约5%。这是由于FSM-based调度通过显式定义状态转移关系,减少了推理错误,收敛速度更快。实验结果还表明,使用FSM-based调度器,AutoTQA在相同任务下平均轮次数降低至原LLM-based调度器的1/1.6。
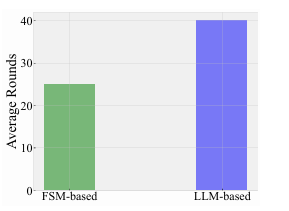
在企业数据集下的平均轮次
*Finding:AutoTQA的其性能取决于代理调度算法。值得注意的是,基于循环滚动的调度器表现出最差的性能。基于FSM的调度算法实现了最佳性能,同时减少了调度轮次,这有助于更快的收敛,从而显著增强用户体验。
5.5嵌入式服务对准确率的影响
为回答RQ4,实验在本节探讨嵌入式服务(Few-shot Prompting)对AutoTQA(GPT-4-turbo)准确率的提升作用。

嵌入式服务对准确率的影响
实验结果表明,引入少量few-shot示例(如5个),即可将准确率从60.0%提升到80.0%。随着few-shot示例数量增加,准确率先上升后趋于稳定。这说明选择高质量的few-shot示例对提升准确率尤为关键,数量过多反而可能带来负面影响。由此可见,Few-shot示例对AutoTQA性能有重要影响;适量引入少量示例,可以显著提升系统整体准确率。
*Finding:AutoTQA在精度方面的性能取决于少样本示例。通过适度增加示例数量,可以提高AutoTQA性能。
6.1表格问答
目前已有若干先进的方法用于处理单表的表格问答(TQA)任务。这些方法大致可以分为以下两大类:
基于微调的表格问答方法:主要有Table-BERT、TaPas、TAPEX、SaMoE、PASTA、TaCube、OmniTab、MultiTabQA等;
基于大语言模型的表格问答方法:主要有Binder、Dater、ReAcTable等。
6.2大语言模型智能体
针对基于LLM的智能体研究,目前比较代表性项目有Voyager,它在Minecraft游戏环境中,持续探索世界的LLM驱动自主学习智能体;同时,Generative Agents模拟人类行为的智能体,能够根据环境变化动态适应;BOLAA提出了多智能体协作策略,以提升智能体在复杂任务中的动作交互能力。此外,AgentVerse项目开放了一个多智能体协作框架,促进LLM智能体在复杂推理与执行任务上的广泛应用。其他的研究还有ChatDev、CAMEL、D-Bot等等。
6.3基于LLM的可视化编程工具
近年来,随着LLM的迅猛发展,出现了多种利用LLM进行可视化编程(Visual Programming)的工具与系统。代表性工作包括:LangFLow、Rivet、Prompt Flow、PromptChainer等。
在本文中,作者提出了AutoTQA,一个自主式表格问答(TQA)框架,基于多智能体大语言模型协作工作。AutoTQA包含五种智能体,它们通过协作来完成用户指定的任务。同时还提出了智能体调度算法,以协调各智能体之间的互动。此外,通过引入ReAct范式,AutoTQA能够与外部应用进行交互,从而增强其处理复杂TQA任务的能力。最后,作者进一步开发了一个开源的、可视化的低代码工具LinguFlow,极大地加速了基于LLM应用的开发、调试与部署流程。大量实验结果表明,AutoTQA在四个具有代表性的数据集上均取得了优异的准确率表现。
论文解读联系人:
刘思源
13691032906(微信同号)
liusiyuan@caict.ac.cn





