




数据库分布式锁的实现与应用:解锁高并发的“救命稻草”
在现代互联网应用中,我们经常遇到这种情形:多个请求同时尝试访问或修改数据库中的某一资源,比如用户余额、订单状态等。如果没有合适的机制来处理这种竞争请求,那么就可能导致数据不一致、丢失或者重复操作的问题。这时候,数据库分布式锁就成了我们解决高并发问题的“救命稻草”。
什么是数据库分布式锁?
数据库分布式锁是一种跨多个服务器或应用实例的锁机制,目的是确保在分布式系统中,只有一个线程可以在任意时刻访问某个共享资源。它是由数据库提供的一种锁定机制,通常用于协调不同进程、节点或服务器之间的资源访问。
想象一下,如果你和你的朋友都想抢购同一款限量版的鞋子,而系统没有正确的锁定机制,就可能出现“多个人同时购买”的情况。此时,数据库分布式锁就可以确保每次只有一个人能够成功购买。
分布式锁的实现方式
实现分布式锁的方式有多种,常见的方式包括:
基于数据库的分布式锁
这是最常见的一种实现方式。通过在数据库中设置一个锁表,利用数据库的原子操作来模拟锁机制。具体实现时,每个请求尝试往这个锁表中插入一条记录,如果插入成功,则表示获取到锁;如果插入失败,则说明锁已被其他请求占用,当前请求需要等待或重试。
优点:实现简单,利用现有数据库机制,不需要引入额外的中间件。
缺点:性能较差,数据库的锁会成为瓶颈,尤其是在高并发场景下,可能会导致锁争用严重,甚至阻塞其他操作。
实现步骤:
代码示例:
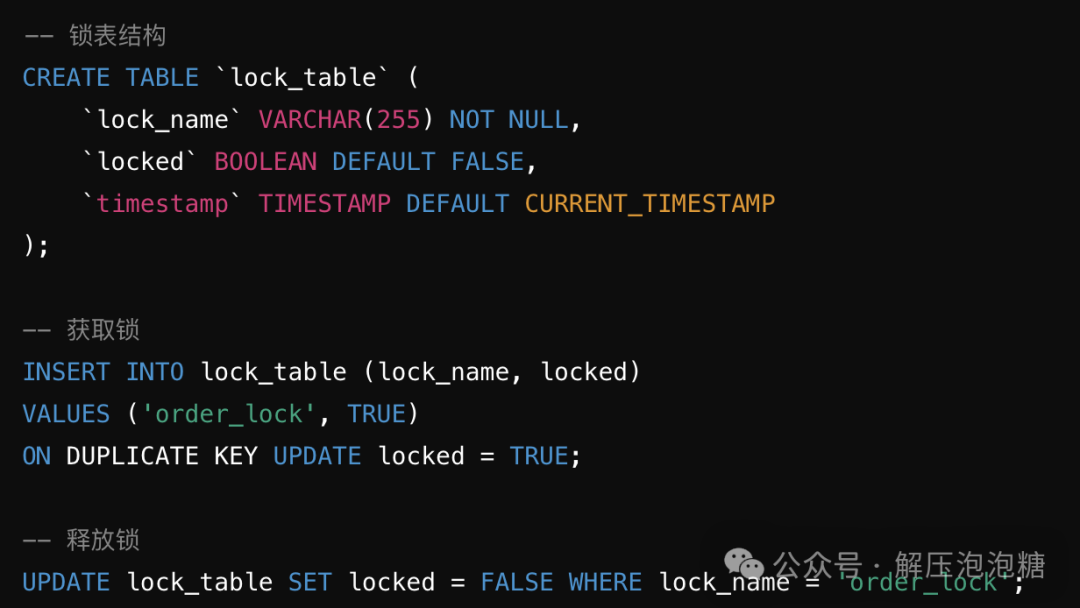
创建一个锁表,表中包含锁的唯一标识(如锁的名称)和锁的状态(是否被占用)。 获取锁时,通过 INSERT
或UPDATE
语句检查锁的状态。释放锁时,更新锁表的状态或删除记录。 基于Redis的分布式锁
Redis作为一个高性能的内存数据存储系统,非常适合用来实现分布式锁。通过
SETNX
命令,Redis可以非常高效地实现分布式锁的功能。SETNX
(Set if Not Exists)命令用于在Redis中设置键值对,只有在键不存在时才会成功设置。这样就能确保在多个客户端之间只有一个客户端能够设置锁。优点:性能高,Redis是内存数据库,读写速度极快。适合高并发的场景。
缺点:依赖外部的Redis服务,可能出现网络延迟或Redis服务不可用的风险。
实现步骤:
代码示例:
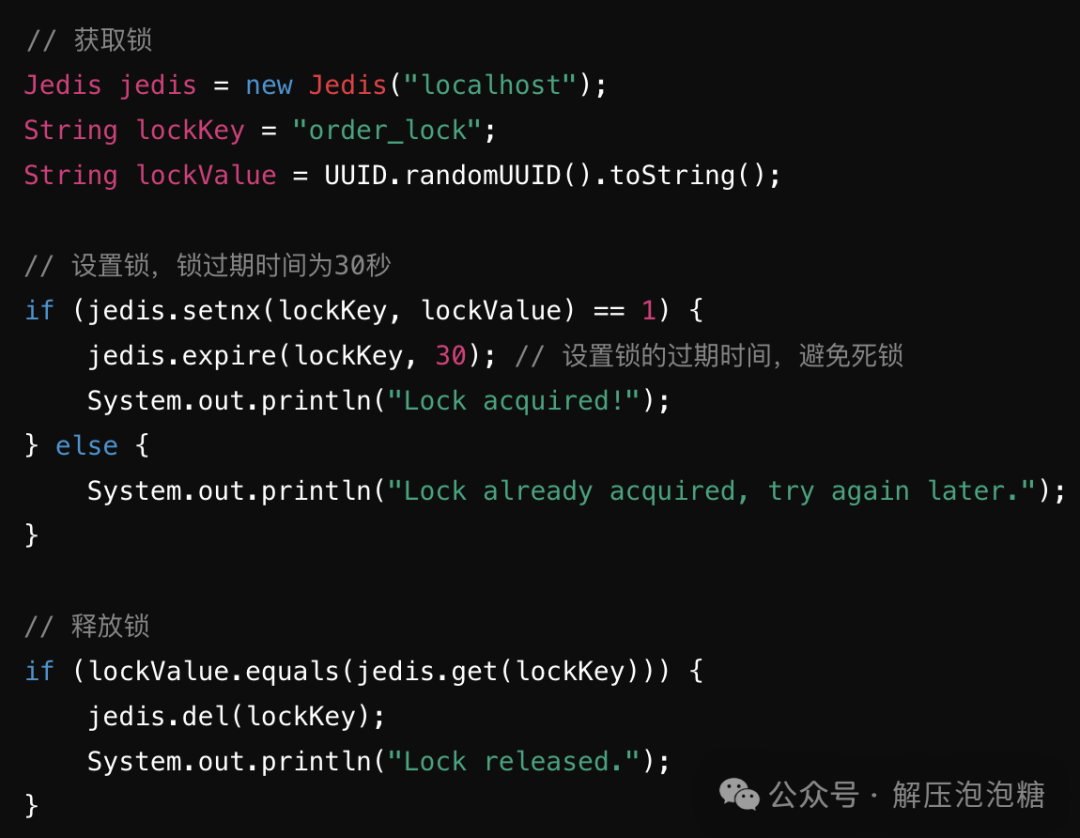
使用 SETNX
命令将锁存入Redis中,表示获取锁。使用 GET
命令检查锁的状态。设置锁的过期时间,防止因故障等原因导致锁无法释放。 基于ZooKeeper的分布式锁
ZooKeeper是一个分布式协调框架,常用于管理分布式系统中的元数据和配置。它的
临时顺序节点
特性非常适合用来实现分布式锁。优点:ZooKeeper具有强一致性保证,适合用来做分布式协调。
缺点:ZooKeeper本身比较复杂,需要维护ZooKeeper集群,并且性能相对较低。
实现步骤:
创建一个锁的临时顺序节点。 判断自己是否是最小的节点,如果是则获得锁,否则监听前一个节点,直到前一个节点被删除。 释放锁时,删除临时节点。
应用场景:分布式锁如何解决实际问题
限流控制
在高并发场景下,分布式锁常常用于限制对某一资源的并发访问。例如,电商平台秒杀活动时,使用分布式锁来确保每个用户只能抢到一件商品。
防止重复消费
在分布式系统中,某个请求可能会被多个实例处理,导致多次执行相同的操作。比如,支付系统中,重复扣款问题就是典型的场景。通过分布式锁,可以确保某个请求只被处理一次,避免重复消费。
任务调度
对于定时任务的调度,可以使用分布式锁来确保任务不会被重复执行。例如,分布式爬虫或者批量数据同步时,分布式锁可以保证同一时刻只有一个任务在执行。
如何优化分布式锁?
设置合理的过期时间:锁的过期时间应该根据具体业务的执行时间来设置,防止锁长时间占用,导致其他请求无法获取锁。
避免死锁:特别是在数据库和Redis中,要确保获取锁和释放锁的操作是原子性的,避免出现死锁。
考虑使用轻量级的锁:对于一些简单的任务,可以考虑采用更轻量的锁机制,比如基于乐观锁或CAS(Compare And Set)来避免不必要的锁竞争。
减少锁的粒度:尽可能将锁的粒度控制在细小的范围内,避免大范围锁定,提升并发能力。
通过分布式锁的实现和优化,我们不仅能够解决高并发问题,还能提升系统的可靠性与可扩展性。在分布式环境中,锁机制就是系统能否平稳运行的“基石”。掌握分布式锁的技巧,能让你在处理大规模流量时更加游刃有余!
