




点击上方 蓝字 关注一臻数据👆
免费领取 DeepSeek➕数字AI知识库 🔗 一起共建共进
❝数据ETL流程刮来了一阵极简风...
曾几何时,数据同步与处理意味着N+1行代码、2N+1天开发时间和N-1的专业人员投入。
现在,这些工作可以在5分钟内完成,而且只需3个动作:拖-拉-拽,并且支持Doris、MySQL、Oracle、Kafka等数据源。
今天👇借5.1闲暇之余一起来瞧瞧这个神奇的可视化拖拽式大数据平台。

从代码到拖拉拽
大数据领域从事十余年,见证过从最原始的纯写代码,到使用FlinkCDC、Canal这类专业工具的演进。
每一次技术变革都降低了门槛,但真正让数据处理"平民化
"的拐点,正是这类拖拽式数据流引擎的出现:
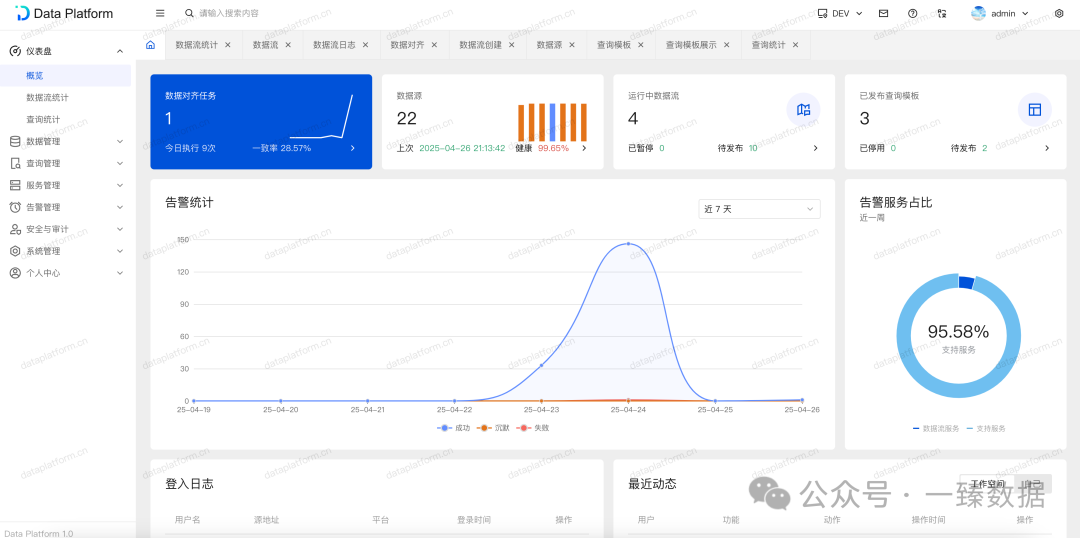
使用传统方法,一个简单的数据同步工作流程是这样的:
开发人员需要先了解源数据结构,编写查询代码提取数据,设计过滤逻辑,然后构建目标数据写入程序,最后部署定时任务实现自动化。
整个流程至少需要一个工作日,且必须由中高级开发人员参与完成。
可视化数据流平台正在改变这一切。
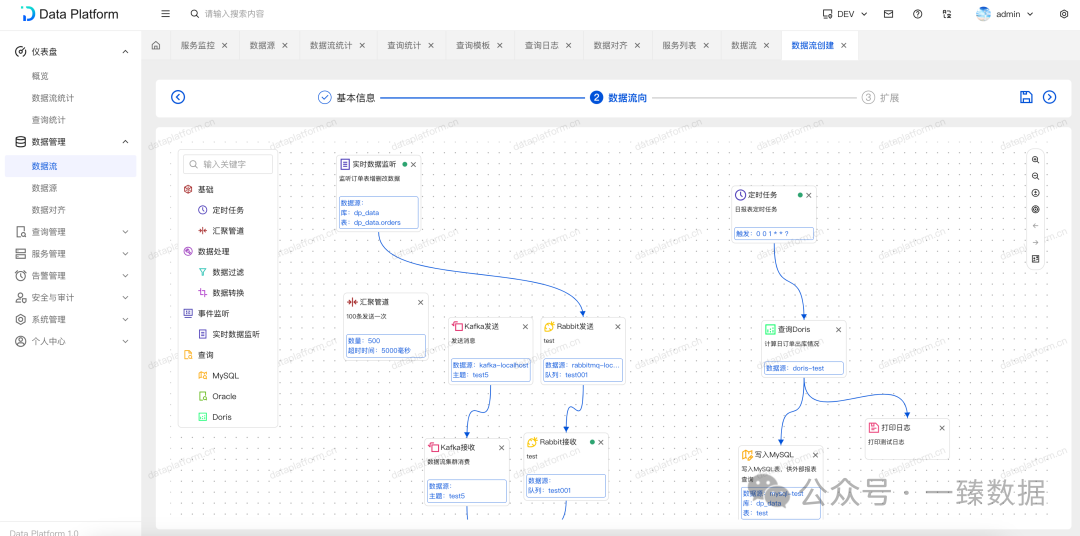
平台提供了直观的画布界面,用户只需在画布上拖拽节点,连接数据流向,几分钟内即可完成原本需要一整天的工作。不仅如此,这项工作现在连初级运维人员也能胜任。
某电商平台的数据团队曾面临双十一大促前的困境:
需要在48小时内完成300张新表的数据同步配置。使用传统方法,这需要至少6位开发人员连续加班。而采用可视化数据流平台后,仅2位初级人员在一个工作日内便完成了全部配置!
可视化背后的引擎创新
这种效率提升并非偶然。
可视化数据流平台shaiwz
集成了多项创新功能和完备的功能模块。
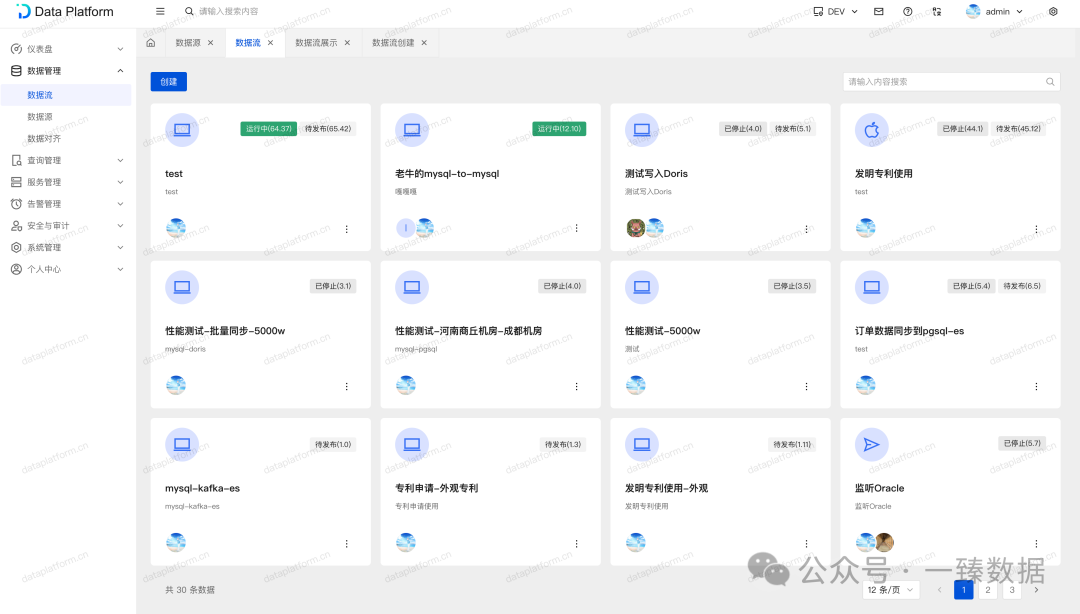
一、任务可控
提供全套日志、监控、告警、权限和版本控制。
二、数据一致性检查
支持配置何时触发,以及策略对齐策略:数量一致、内容一致、随机数量。
并且包含时间范围等等配置,甚至允许自动补齐、更新。
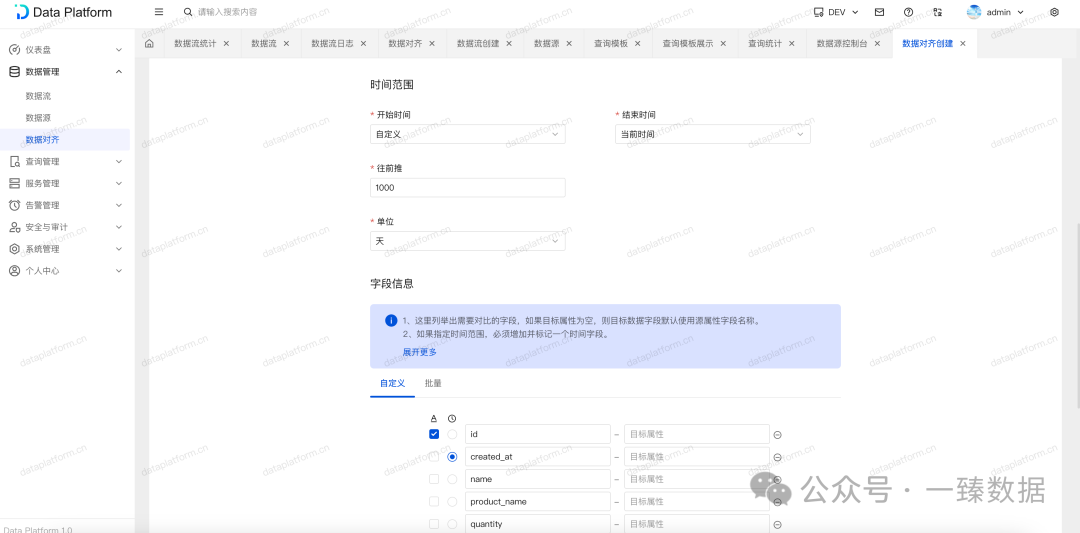
当出现数据不一致时,会进行告警,并提供运行日志以及差异数据展示。
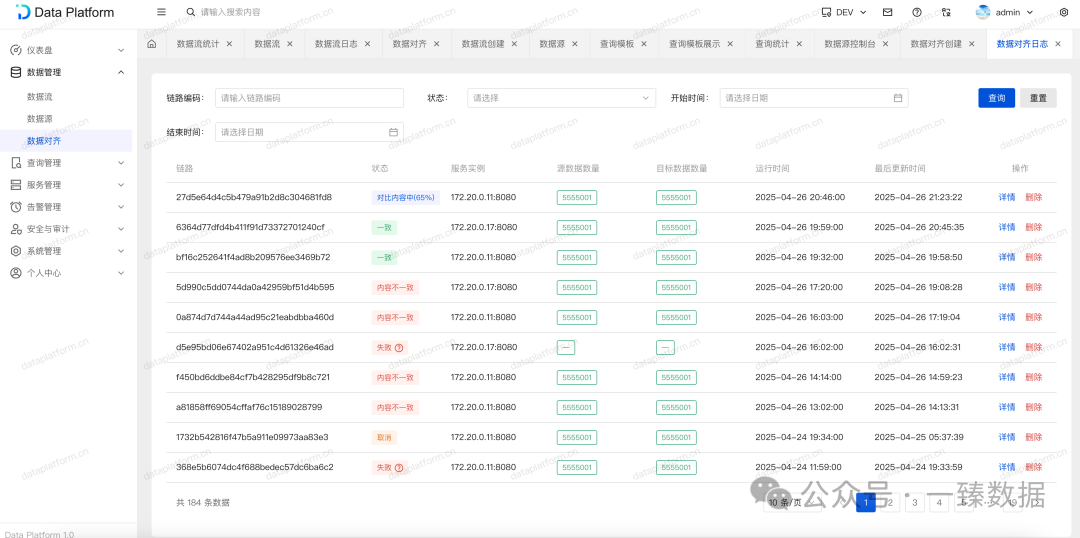
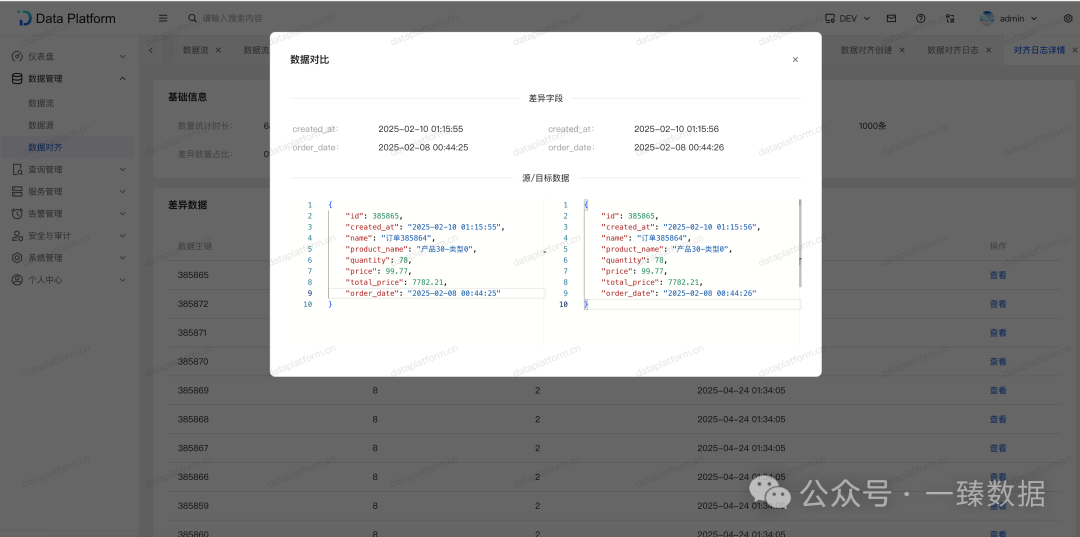
如果出现差异时,则可以查询差异数据,以及差异的具体字段明细。
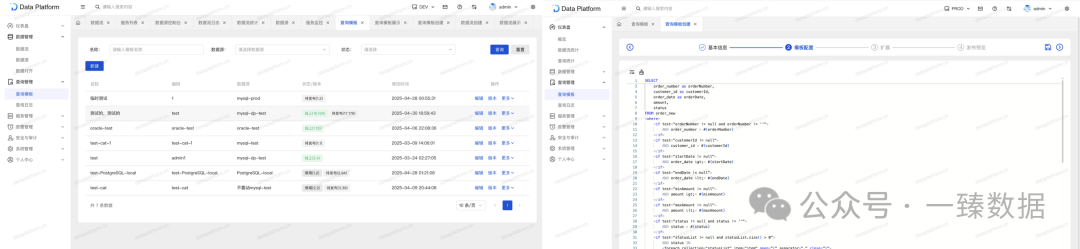
三、查询模板
除此之外,平台提供了查询模板功能,支持密钥、权限、版本控制、限流、缓存、日志等。
当对外提供接口,出报表接口等再也不用手写后端代码了,用户只需要关注具体查询SQL即可(模板配置如下,支持分表算法以及动态SQL
)。
四、动态扩缩容
尤其值得一提的是,平台支持任意节点的缩扩容,服务压力大时自动增加节点提高吞吐量,闲时则减少节点节约成本。
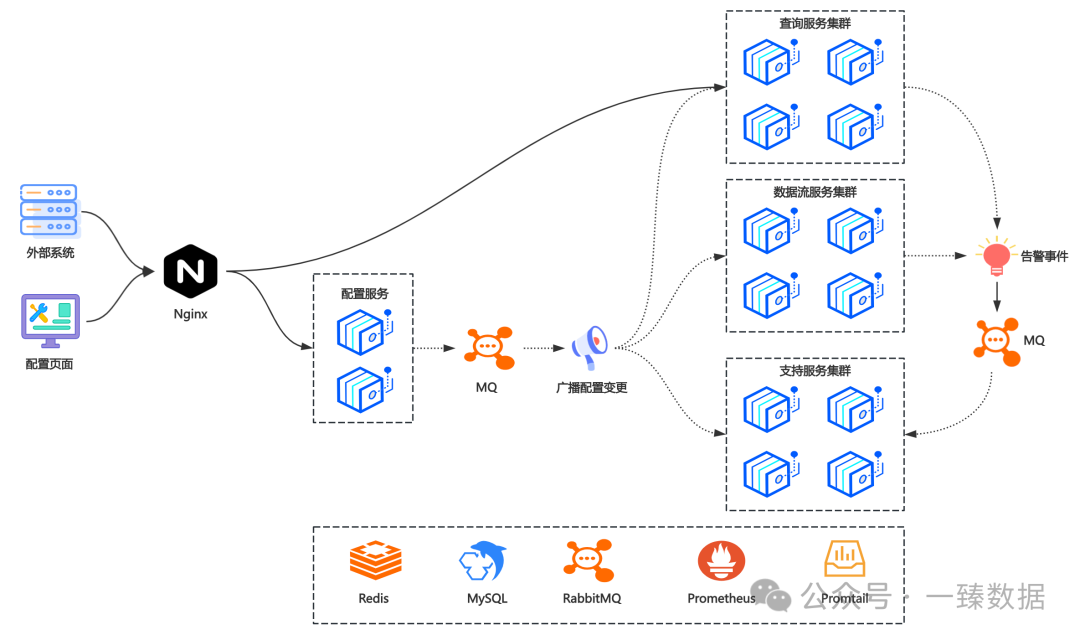
且提供多种数据源支持,包括Doris、MySQL、Oracle、Kafka及ElasticSearch等数据源。插件式的架构设计使其能轻松扩展支持更多数据源类型。
还有更多的玩法和使用指南,可以通过如下入口进行学习👇
🔗 官网:https://shaiwz.com/home
🔗 产品首页:http://dataplatform.cn/login
🔗 开源地址:https://gitee.com/aizuda/data-platform-open
结语
当我们从"写代码"到"拖拉拽",我们释放了创造力,也重新定义了效率。
如果传统ETL是"手工作坊
",那这款平台就是"现代工厂
"——标准化、自动化、可视化。
不只是让技术变简单了,也让业务增添了更多的可能性。
也许,这就是shaiwz
的使命:让复杂变简单,让专业变普及。

完
