





引言
传统RAG方案的不足
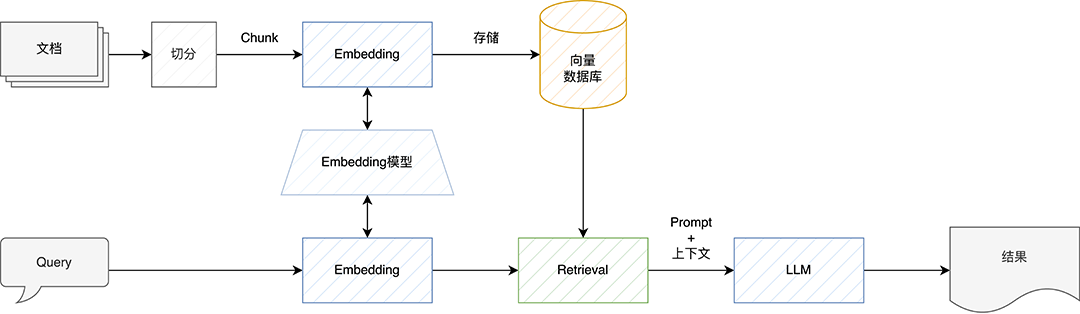
索引:利用 Embedding 模型将文档分块转化为向量,并存储在向量数据库中。 检索:将查询转化为向量,通过相似性算法在向量数据库中查找相关上下文文档。 生成:将查询和检索到的上下文文档输入到大型模型中,以生成高质量的结果。
上下文理解不足:难以深度理解文本中实体间的复杂关系,影响回答的准确性。 信息筛选不佳:难以区分关键信息与冗余信息,导致使用无效内容或噪声。 查询意图不明确:查询过于笼统或含歧义时,影响向量和模型的准确性。
基于 Qwen3+AnalyticDB+Dify on DMS
构建一站式GraphRAG服务
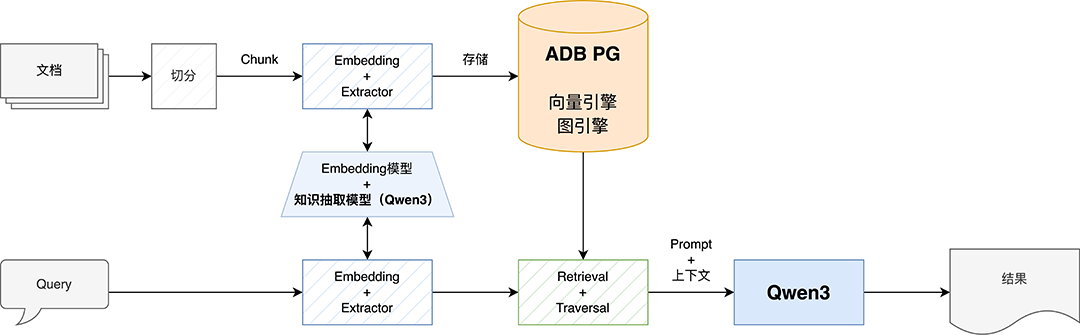

阿里云瑶池 DMS+AnalyticDB 支持私域部署大模型,Dify+Qwen3模型在同一专有网络(VPC)内部署,通过客户自购资源部署和专有网络联通使用,数据不出域,安全有保障,服务更稳定!通过结合 Dify on DMS + Qwen3 + AnalyticDB PostgreSQL,可以实现高效安全的 GraphRAG 业务应用。
知识图谱理解与抽取
GraphRAG 引擎
Data Agent LLMOps 平台
案例介绍:某头部新零售客户

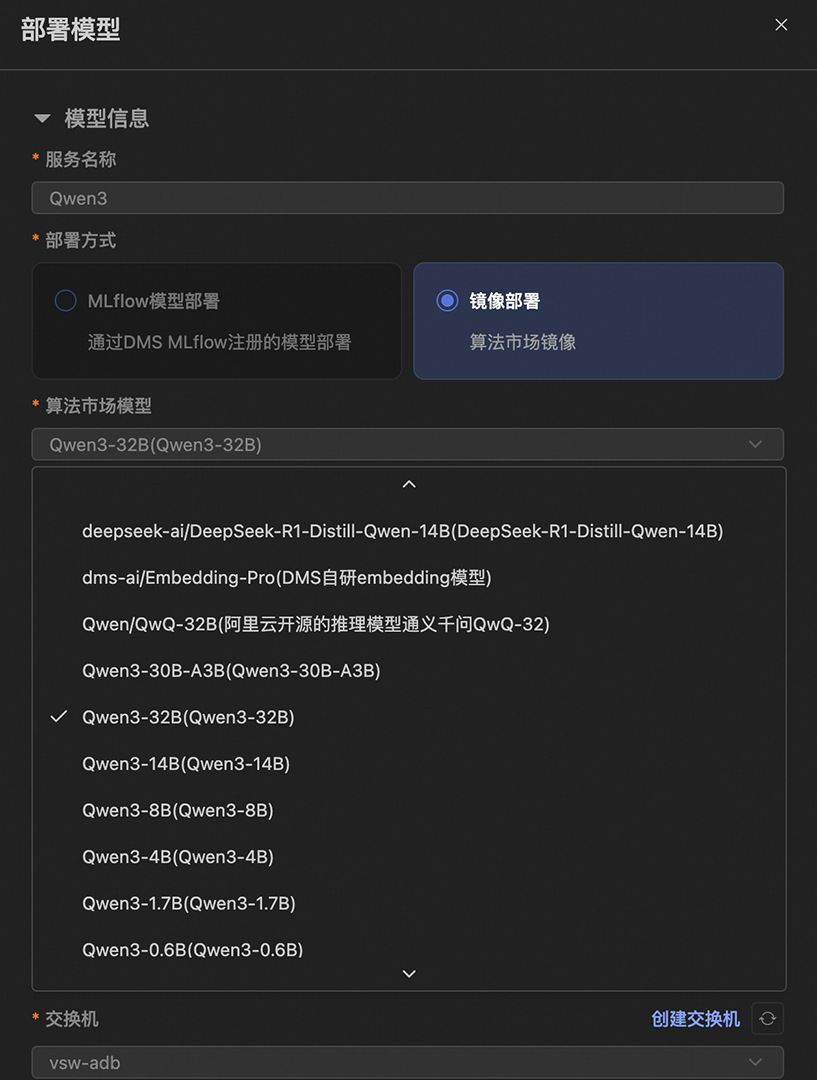
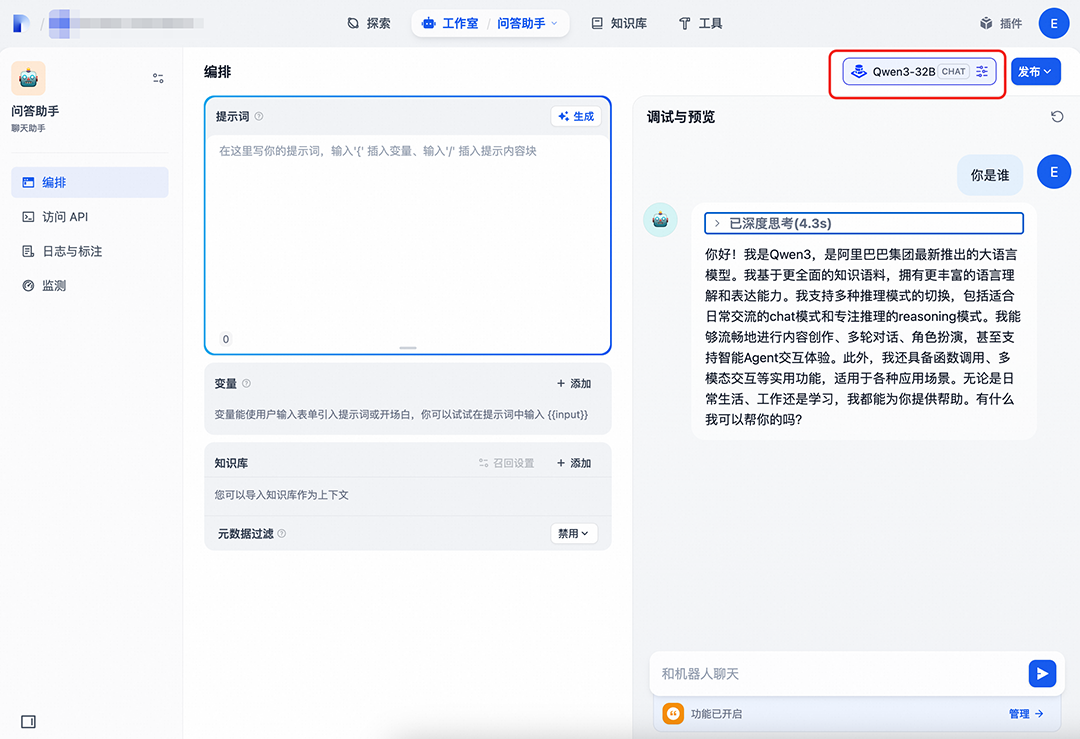
如何部署Qwen3
详细部署步骤请参考👇
https://developer.aliyun.com/article/1656021
点击文末「阅读原文」即可开通
总结



点击阅读原文一键部署Qwen3(PC端打开体验更佳)

文章转载自阿里云瑶池数据库,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
