




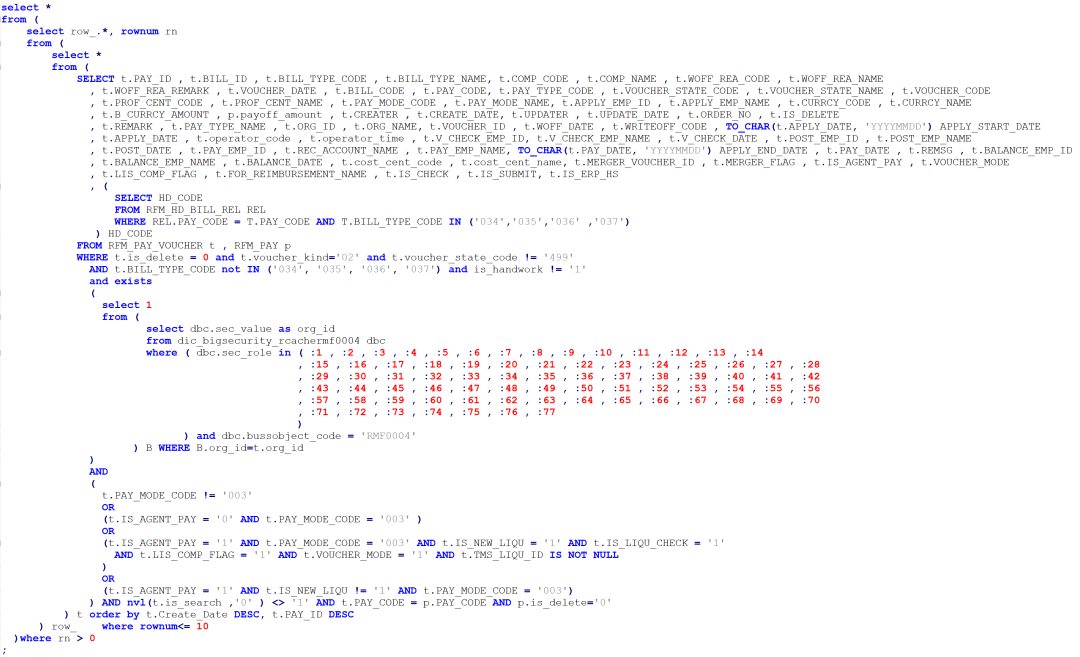
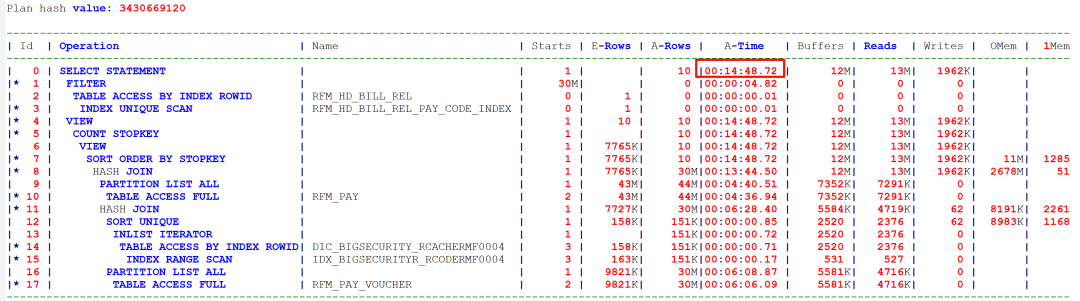
1.把原SQL的标量子查询部分给丢掉了,执行时间快了5分钟也就对上了;
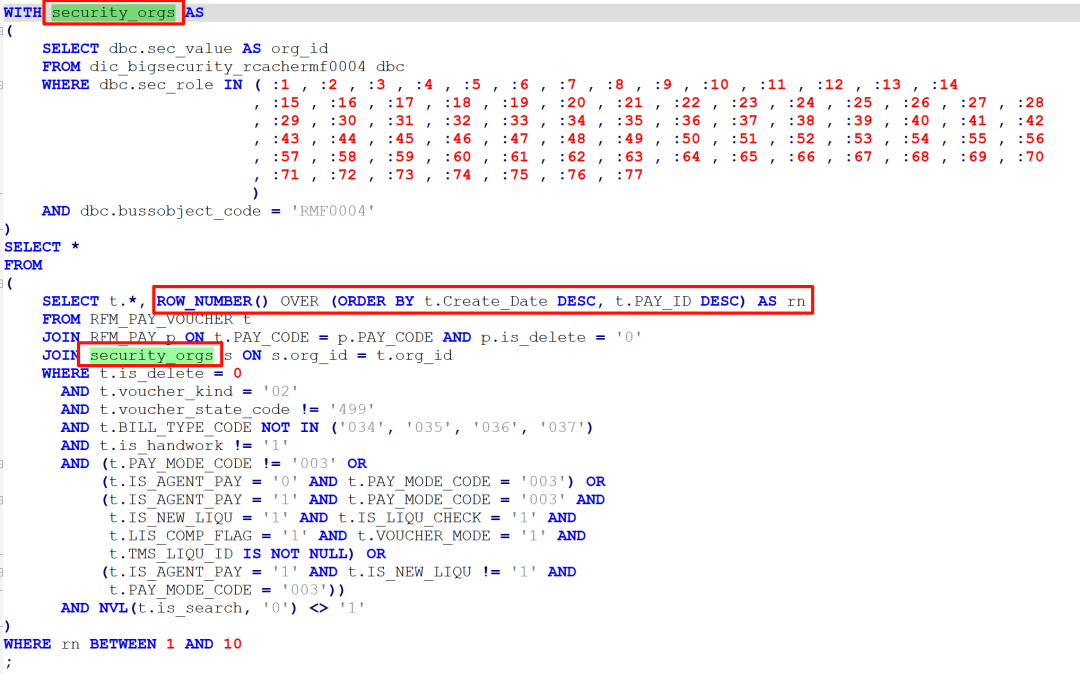
2.把exists用with as改写, 并改成了inner join, 这是不等价的;
3.把原来rownum写法的分页框架,改成了row_number分析函数写法,这个改动没有意义,而且分析函数的写法还要更慢一些.
不知道deepseek的这些改写套路是跟哪个"大师"学的,有点"有病乱投医,医生乱开药方"的感觉.
其实这种分页是有套路的, 当罗老师只发给我SQL text时,我没办法给出优化建议, 当看到执行计划时, 我立即告诉罗老师, 这个SQL可以优化到不到1秒.
为了利用当前表上已经存在的索引, 我给出了下面改写建议:
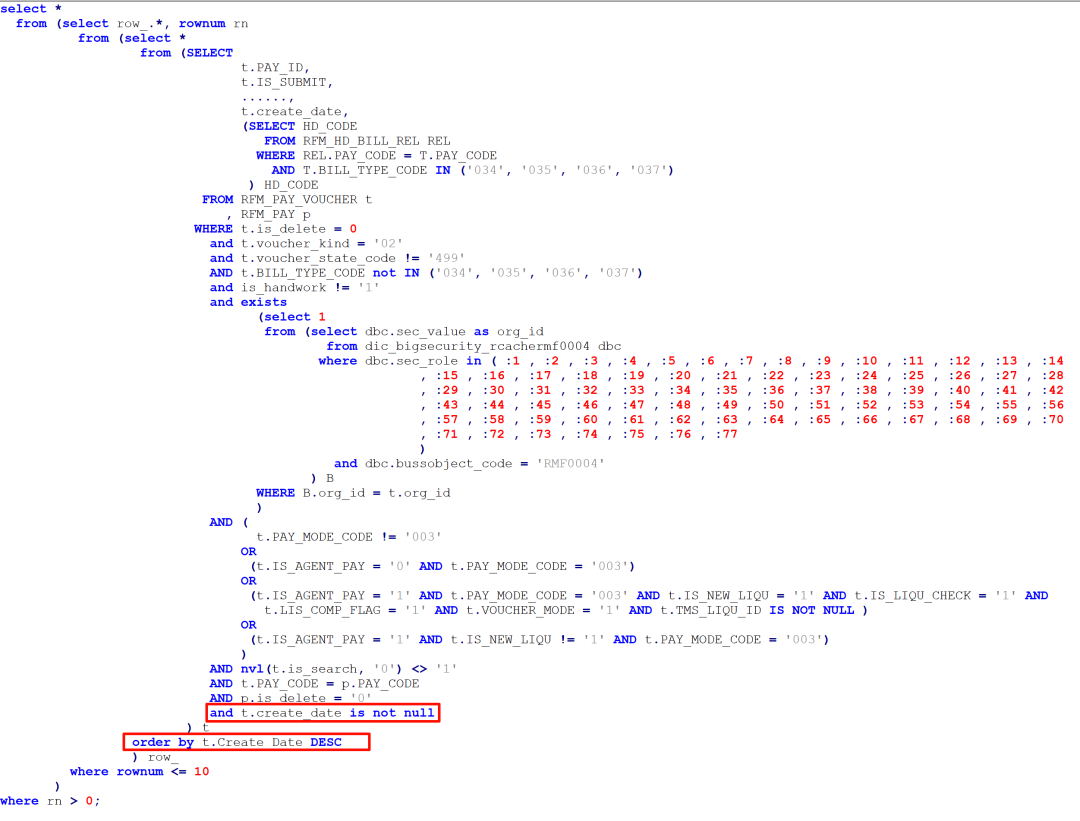
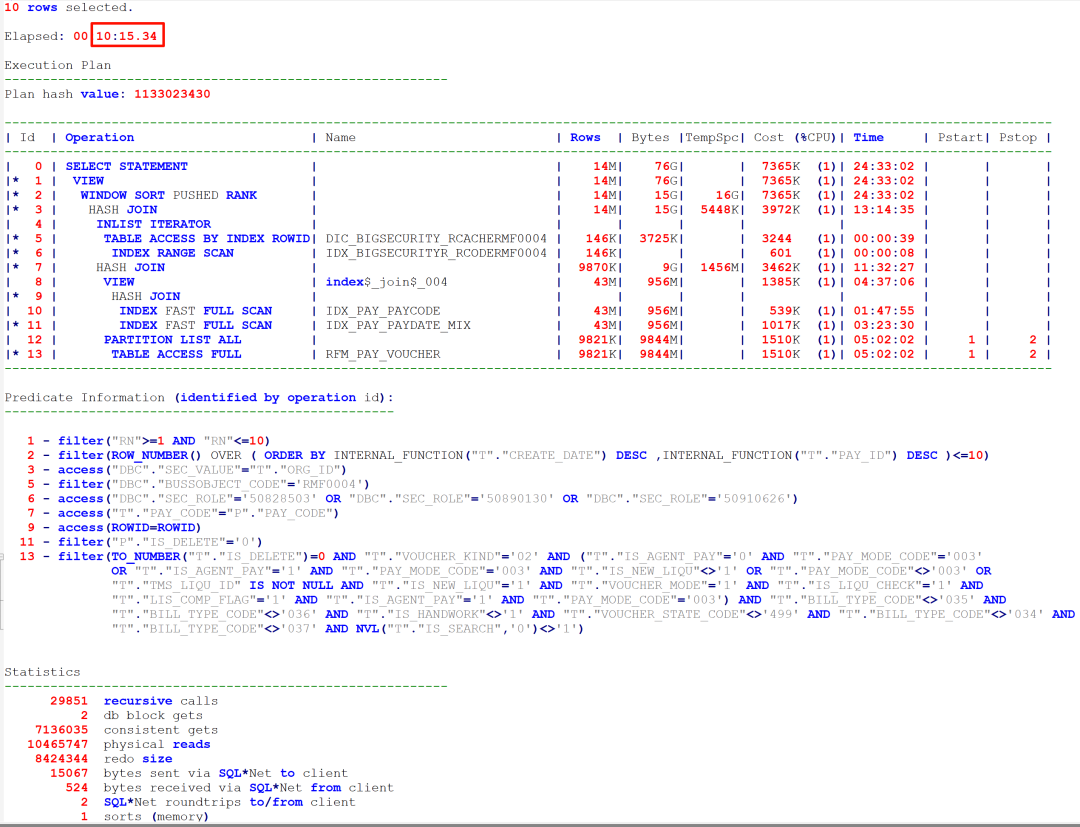
罗老师很快从现场反馈: 执行时间确实不到1秒就返回结果了. 执行计划如下:
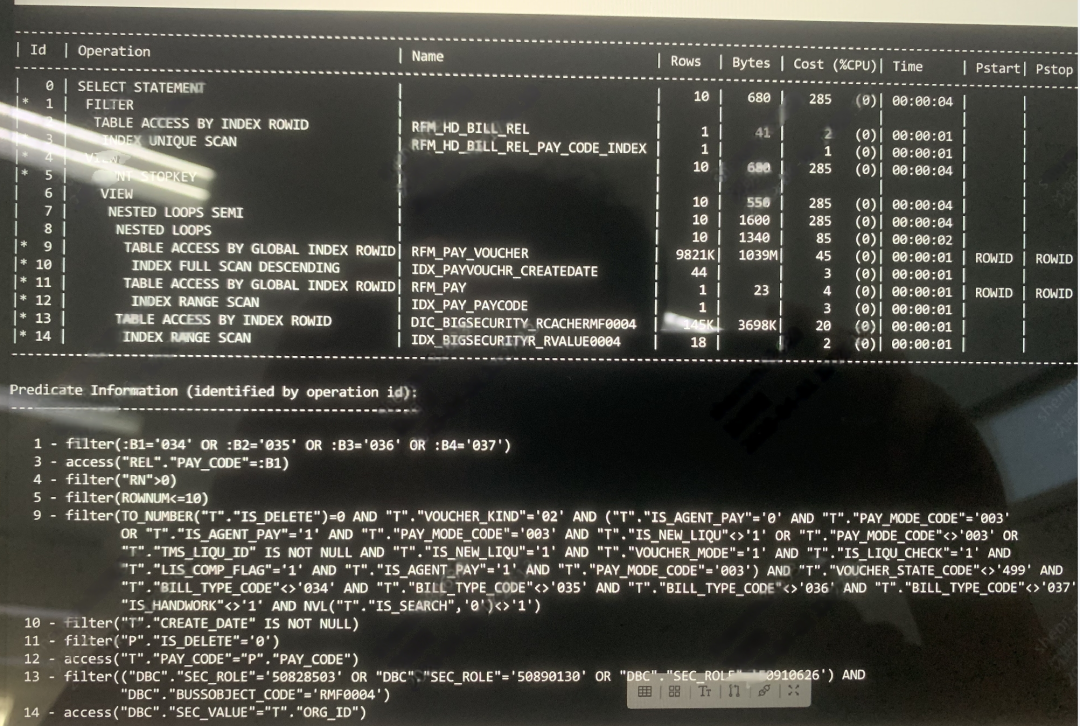
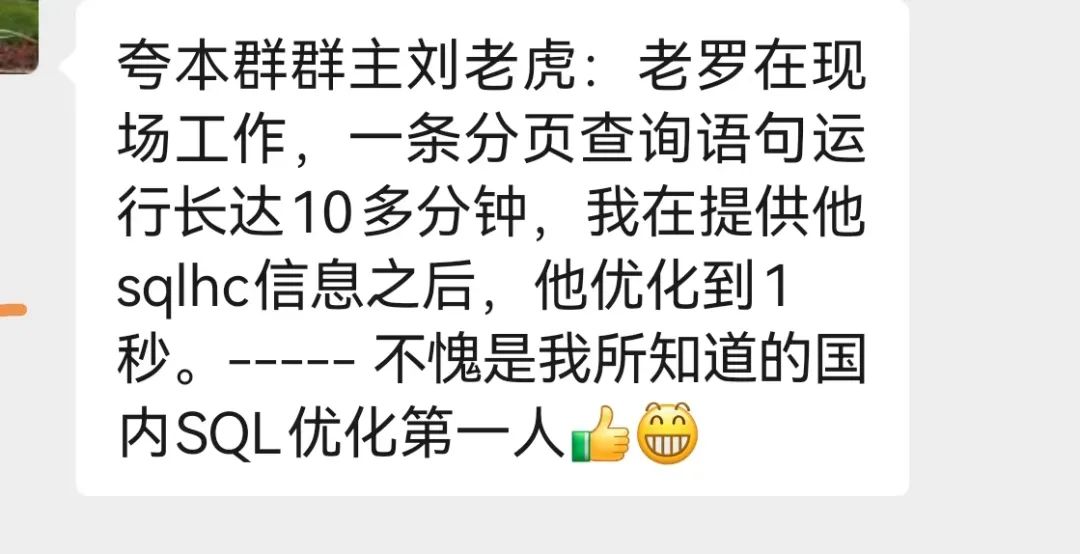
SQL优化就是这么神奇, 从15分钟到不足一秒, 这就是优化师存在的价值. 这个案例, 我拿给参加过<索引专题>培训的学员, 也能给出正确的建议(方法多样,也可以不改写SQL,需要新建索引).
这些单个的SQL优化都是小case, 我了解过很多客户的跑批业务, 执行时间都比较长, 只不过还在能够容忍的范围, 即使无法容忍,很多DBA也是想通过更换更高级的硬件来提速, 这些都不是正道. 做个整体优化, 效果会更好.
全国的数据库系统, 如果都能高效的运行, 我相信生产效率还会大幅提升, 资源的使用会大幅下降.
文章转载自老虎刘谈oracle性能优化,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
