




本篇主要讲一下leveldb的工作原理,leveldb是一个非常有名的KV数据库,像比特币、以太坊等区块链底层的数据库都是leveldb数据库。所以我们需要学习一下leveldb的工作原理,理解在使用leveldb数据库时背后都发生了什么。
如果让你自己设计,你怎么设计呢?
如果让你设计一个KV数据库,你会怎么设计呢? 首先要想一下这个问题,这里需要的是持久化存储的KV数据库,不是内存数据库。既然要持久存储,最终数据肯定是要落盘的,以文件的形式存储在磁盘上,也可以是其他存储介质。我们将key-Value数据写入磁盘后,后面查找的时候可以根据Key将磁盘文件中的Value读出来,这就是一个最最原始的数据库了,但这样后面读的时候是个问题?一般的方法,可以建立索引,我们是以Key来查找对应Value数据的,我们可以维护一个索引文件,里面维护有每个Key对应的Value在那个文件的那个位置上。这样,每次读数据时先在索引文件找Key,再找到Value的位置,再访问数据。但是索引文件中怎么找Key最块呢?问题还有很多,不同Key的Value数据在文件中怎么排列呢?每个文件多大合适呢?是每次写都要立即写入磁盘吗?那样写性能肯定受限。具体上次应用是强调读性能还是写性能?越想问题越多。
leveldb的设计思路
leveldb回答了我们上面碰到的所有问题。最核心的一条,将Key排序,按序存储。排序的目的是为了查找。在内存中,维护一个跳跃链表skiplist,所有数据库的相关操作都先在内存的skiplist中进行处理,当然为了防止突然掉电关机等造成数据丢失,会在内存之外,额外维护一个日志文件,用来在这种情况下对数据进行恢复。那什么时候存入磁盘呢?当内存中的skiplist超过一定的大小后,将数据转为immutable memtable,即只读的memtable。由后台compaction线程负责将immutable memtable dump成sstable文件, 即L0层SST。
但这样是有问题的,因为由immutable memtabledump成的sstable文件,随着不断的Put写操作,会存在多个L0层SST文件,这样就造成了不同L0层SST中的key是存在重叠的,因为相对而言,所有L0层而言,他们都是部分排序,并不是全排序,这样存储的问题是,即浪费存储空间又影响查找效率。所以,要在L0的基础上,继续进行compaction,将L0层的SST文件归并为L1层SST。此时,L1层因为进行了归并排序,key没有重叠。就这样就可以了吗?如果只有两层,那么每次进行归并时,相当于所有数据都要进行归并,数据量过大,对性能影响较大,怎么办呢?可以进行多层SST设计,当每一层的数据达到一定容量后触发向下一层的归并操作,每一层的数据量比上一层成倍增长,这样就即避免了每次参与归并操作的数据量过大,又一定程度上优化了读操作,leveldb最多可以到7层。
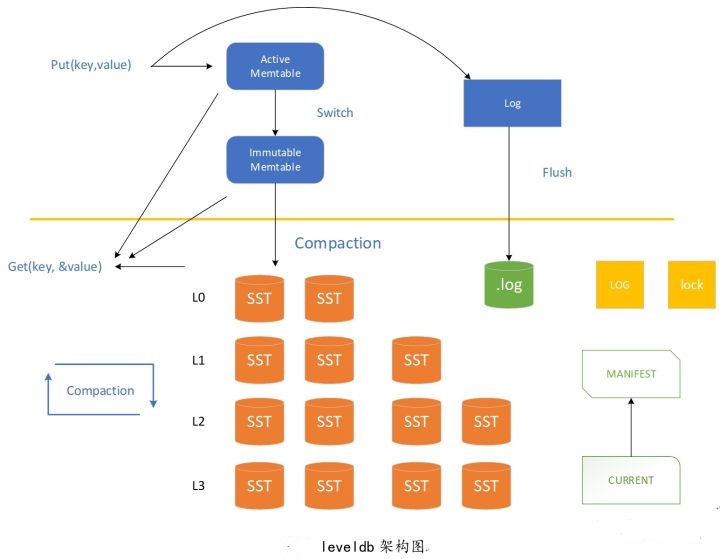
下面我们看一下,leveldb中的读、写、删除具体是怎么做的。最简单的是读,即因为数据的流向是memtable->immutable memtable->SST文件,所以,读的时候,也是这个读顺序,如果memtable中有对应key,则返回value,如果没有,读immutable memtable,同样的,如果immutable memtable中没有,则读SST文件。因为应用时,很多场景都是读取最近操作的数据,这样的场景下,这样的设计效率是非常之高的,相当于做了一层又一层的缓存,由快到慢,由小到大。写和删除有点类似,写操作,如果是之前没有写过的key,比较容易理解,直接写入memtable即跳跃链表中就可以了,超过大小后,会转为immutable memtable,进而转为SST存贮在磁盘上,即使还每来的及写入SST文件宕机了,也可以利用WAL写在log中文件的数据进行恢复,而如果是更新一个已有的key的value或者删除也是类似,leveldb中并不是先查到到key再写入新的value或者删除,而是直接新写入同一key的value到memtable,value的更新或者删除,会在归并时完成。那还没归并完,此时进行读怎么办?因为读的顺序是先从memtable到immutable memtable再到SST,所以,确保了一定可以读到最新的写的值,即使归并没有完成。为什么这么设计呢?因为普通机械磁盘的性质决定的,对于普通机械磁盘顺序写的性能要比随机写大很多,所以,在涉及到数据库具体的存储优化时,要看具体的存储介质的性质进行优化,同时也要看应用的具体场景。
WAL(Write-ahead Log)
WAL机制即先写日志数据,后写用户数据,这样保证了用户数据持久化,在数据库意外宕机时,可以利用WAL进行恢复。
相关源码
DB数据在内存中的存储方式MemTable,内部采用跳跃链表实现。
class MemTable {
public:
// MemTables are reference counted. The initial reference count
// is zero and the caller must call Ref() at least once.
explicit MemTable(const InternalKeyComparator& comparator);
MemTable(const MemTable&) = delete;
MemTable& operator=(const MemTable&) = delete;
// Increase reference count.
void Ref() { ++refs_; }
// Drop reference count. Delete if no more references exist.
void Unref() {
--refs_;
assert(refs_ >= 0);
if (refs_ <= 0) {
delete this;
}
}
// Returns an estimate of the number of bytes of data in use by this
// data structure. It is safe to call when MemTable is being modified.
size_t ApproximateMemoryUsage();
// Return an iterator that yields the contents of the memtable.
//
// The caller must ensure that the underlying MemTable remains live
// while the returned iterator is live. The keys returned by this
// iterator are internal keys encoded by AppendInternalKey in the
// db/format.{h,cc} module.
Iterator* NewIterator();
// Add an entry into memtable that maps key to value at the
// specified sequence number and with the specified type.
// Typically value will be empty if type==kTypeDeletion.
void Add(SequenceNumber seq, ValueType type, const Slice& key,
const Slice& value);
// If memtable contains a value for key, store it in *value and return true.
// If memtable contains a deletion for key, store a NotFound() error
// in *status and return true.
// Else, return false.
bool Get(const LookupKey& key, std::string* value, Status* s);
private:
friend class MemTableIterator;
friend class MemTableBackwardIterator;
struct KeyComparator {
const InternalKeyComparator comparator;
explicit KeyComparator(const InternalKeyComparator& c) : comparator(c) {}
int operator()(const char* a, const char* b) const;
};
typedef SkipList<const char*, KeyComparator> Table; // 跳跃链表实现
~MemTable(); // Private since only Unref() should be used to delete it
KeyComparator comparator_;
int refs_;
Arena arena_;
Table table_;
};
数据库的读写删除等各种操作都是首先在内存中进行处理,然后才是磁盘上的文件。
