




索引是 PostgreSQL 提高查询性能的最有效工具之一,但像任何强大的工具一样,过度使用也会带来真正的问题。
我的同事 Jobin 之前写了一篇关于 PostgreSQL 索引的博客文章,探讨了过度索引的负面影响:《PostgreSQL 索引可能会损害性能:探索负面影响及其成本》。这篇文章从理论角度进行了很好的阐述,并提出了在日常数据库工作中常常被忽视的重要观点。
这一次,我想更进一步。虽然理论很重要,但数字往往更具说服力,可以帮助你决定是否值得花额外的精力重新审视你的数据库架构。我设计了一系列测试,对 PostgreSQL 进行基准测试,以更清晰地了解在比 pgbench 提供的更有意义的工作负载下,过度索引对性能的影响。
关于测试环境
测试环境并非玩具级配置,所有基准测试都在高性能服务器上执行:
-
Dell PowerEdge C6525
- 2 个物理 CPU,每个 64 核(共 128 个虚拟核心)——AMD EPYC 7452 32 核处理器
- 1 TiB DDR4 内存
- 操作系统:Red Hat Enterprise Linux 9.4(代号 Plow)
- PostgreSQL 版本:17.4
我们使用的PostgreSQL 自定义设置
effective_cache_size = '128GB' checkpoint_timeout = '30min' shared_preload_libraries = 'pg_stat_statements' pg_stat_statements.track = 'all' pg_stat_statements.max = '10000' track_io_timing = 'on' max_connections = '200' maintenance_work_mem = '2GB' bgwriter_lru_maxpages = '500' max_wal_size = '200GB' min_wal_size = '50GB' log_autovacuum_min_duration = '60000' shared_buffers = '64GB'
关于测试方法
设计了一套详细且可重复的基准测试方法,以全面评估过度索引的影响。目标是消除噪声和瓶颈,确保性能下降可以可靠地归因于索引开销,而不是数据变化或系统不一致性。
数据架构设计包括多个表、多种数据类型和完整性约束。
数据加载脚本用于填充表,生成数百亿个随机元组,初始数据集大小约为 11 GB。基准测试执行后,数据集增长到大约 200 GB。
为确保测试运行之间的一致性,初始数据加载后生成了转储文件。在每次测试轮次之前,使用此转储文件重新创建数据库,确保不仅初始数据量相同,数据内容也完全一致。
最后,开发了一个自定义事务脚本来模拟真实应用程序的工作负载。该脚本执行了 INSERT、UPDATE 和 SELECT 操作的混合。工作负载由 pgbench 模拟并发用户执行,持续时间分别为 5、15、30、60 和 120 分钟,并在应用了 7、14、21、28 和 39 个索引的情况下重复执行。
数据集设计尽可能地适合内存(或文件系统缓存),以避免任何潜在的 I/O 瓶颈。
在收集结果时重置 bgwriter 指标,以提高准确性。
在每次测试轮次开始前重启数据库,确保释放缓存数据。
换句话说,所有设计都旨在避免任何副作用的干扰,同时最大化地展示过度索引的影响。
您可以在以下 GitHub 仓库中找到所有相关脚本:
https://github.com/psvampa/postgresql_benchmarking_overindexing
基准测试结果
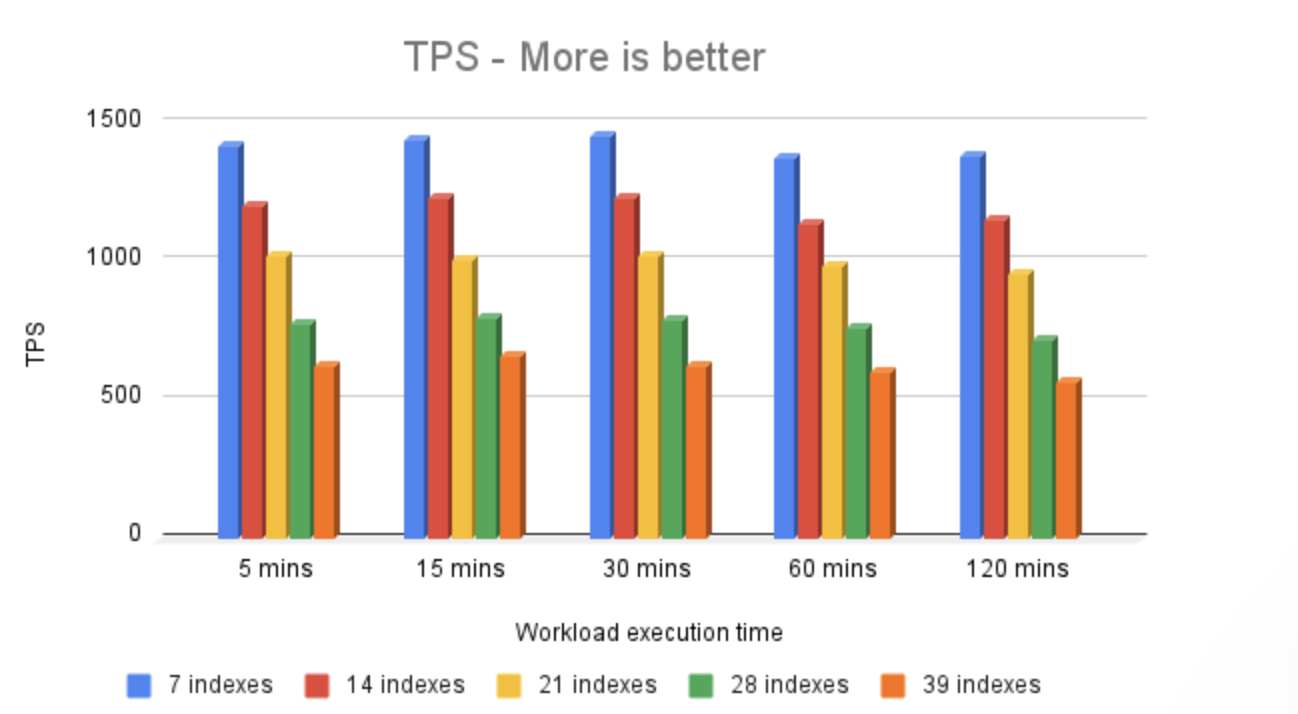
基准测试结果显示,索引数量与性能之间存在明显的相关性:随着索引数量从 7 增加到 39,TPS(每秒事务数)从大约 1400 下降到大约 600。
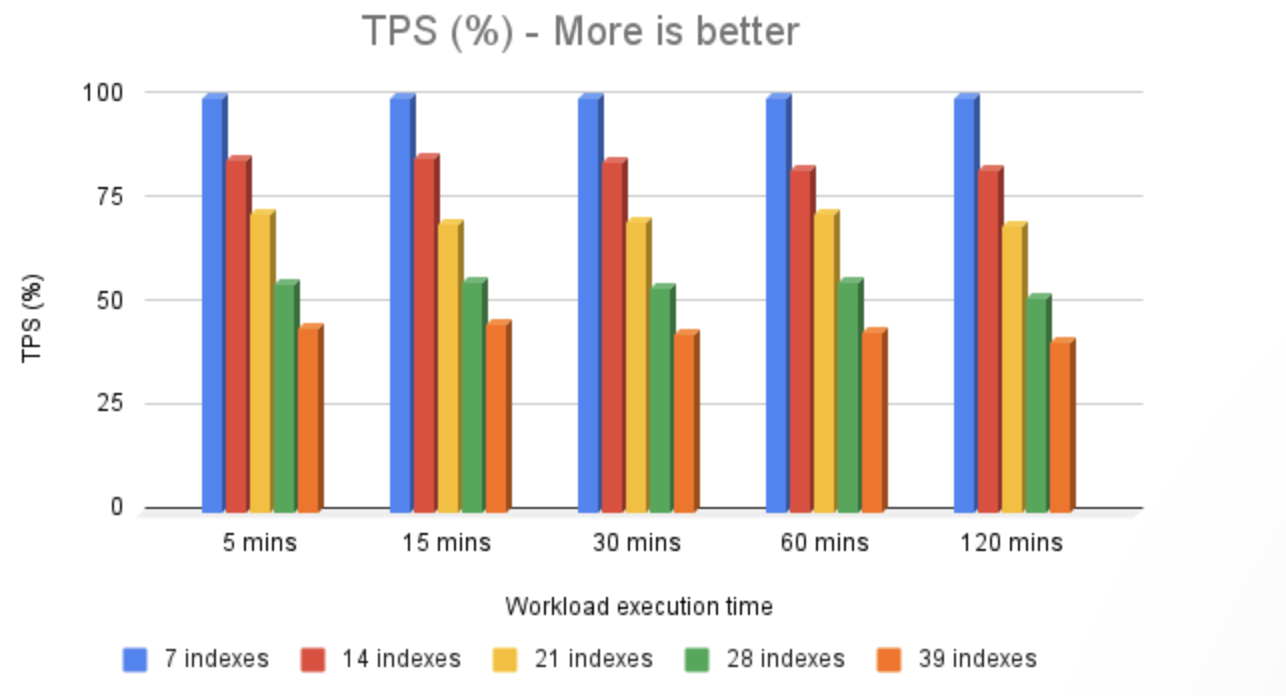
换句话说,将索引数量从 7 增加到 39,性能降低到原始吞吐量的约 42%。这清楚地表明了索引数量与性能之间的反向关系。
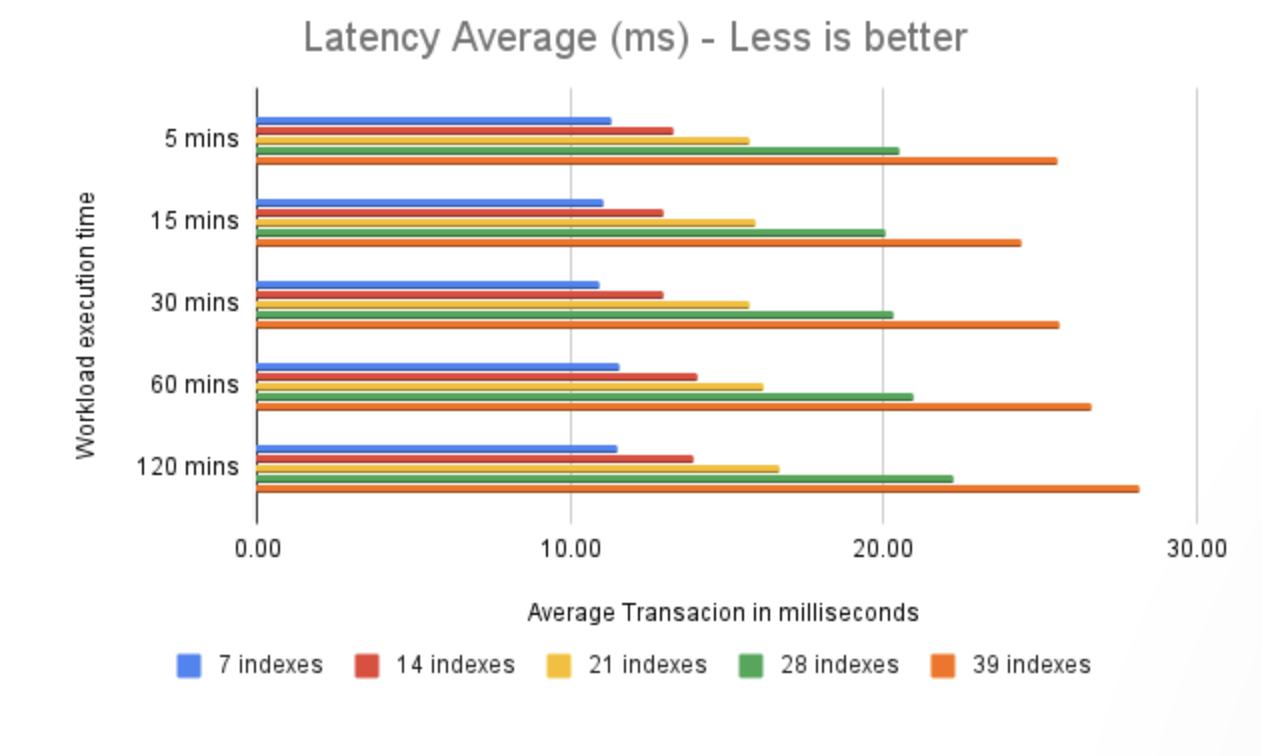
由于我们的基准测试轮次基于固定时间窗口(每轮),每个测试的总 TPS 与每笔事务的速度密切相关;事务完成得越快,在相同时间窗口内可以执行的事务就越多。
在 7 个索引的情况下,平均事务时间为 11 毫秒。而在 39 个索引的情况下,平均事务时间为 26 毫秒。
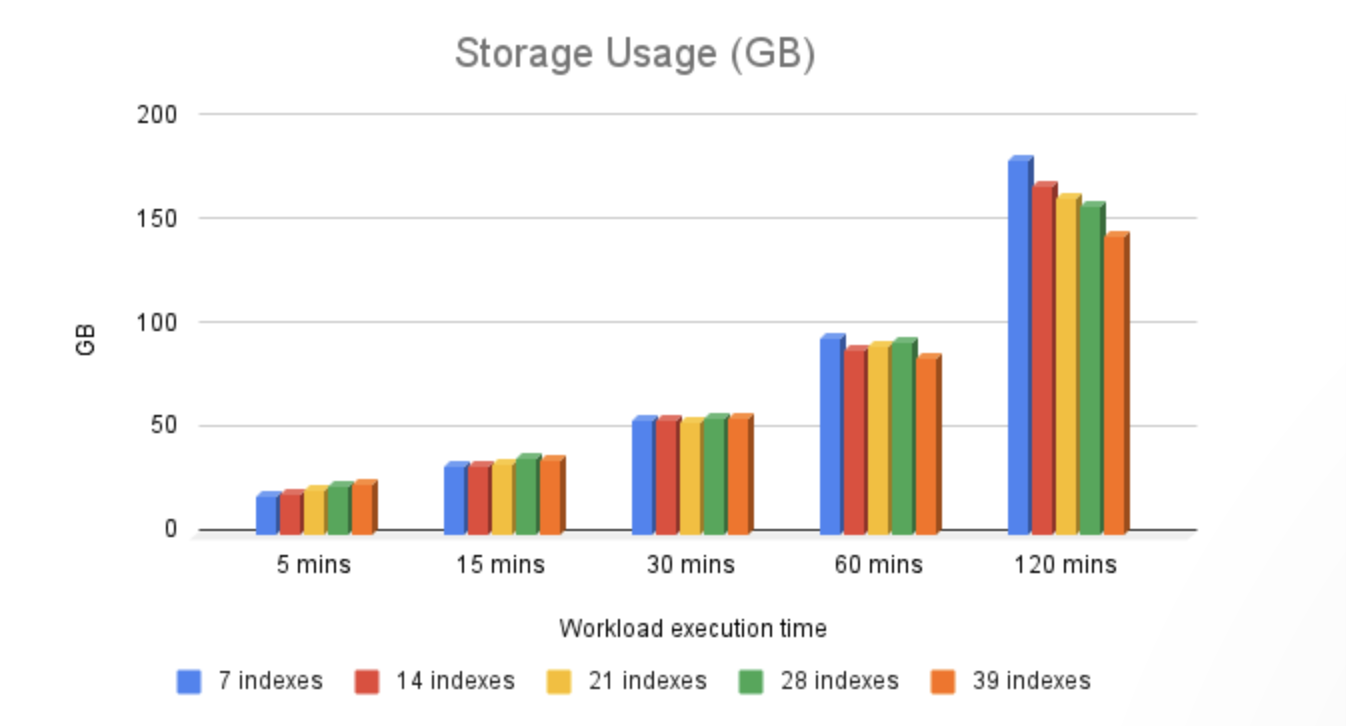
由于我们的工作流持续在架构的表中执行 INSERT 和 UPDATE 操作,因此观察到存储消耗的增长模式是意料之中的,这正是我们在测试中看到的结果。了解存储增长模式以及数据库数据集及其备份的关联成本,强化了制定适当数据保留策略以控制长期增长的必要性。
在最终测试轮次(120 分钟运行)中,索引数量增加而存储使用量减少,这与早期轮次不同,这是一个明显的转折点。由于测试是在固定时间窗口内执行的,额外索引带来的开销导致完成的事务数量减少。因此,在索引数量较多的测试用例中,插入和更新的行数减少,总数据量也相应减少。由于所有索引都是单列的,而表元组通常需要更多存储空间,减少的 DML 操作最终导致整体空间消耗降低。
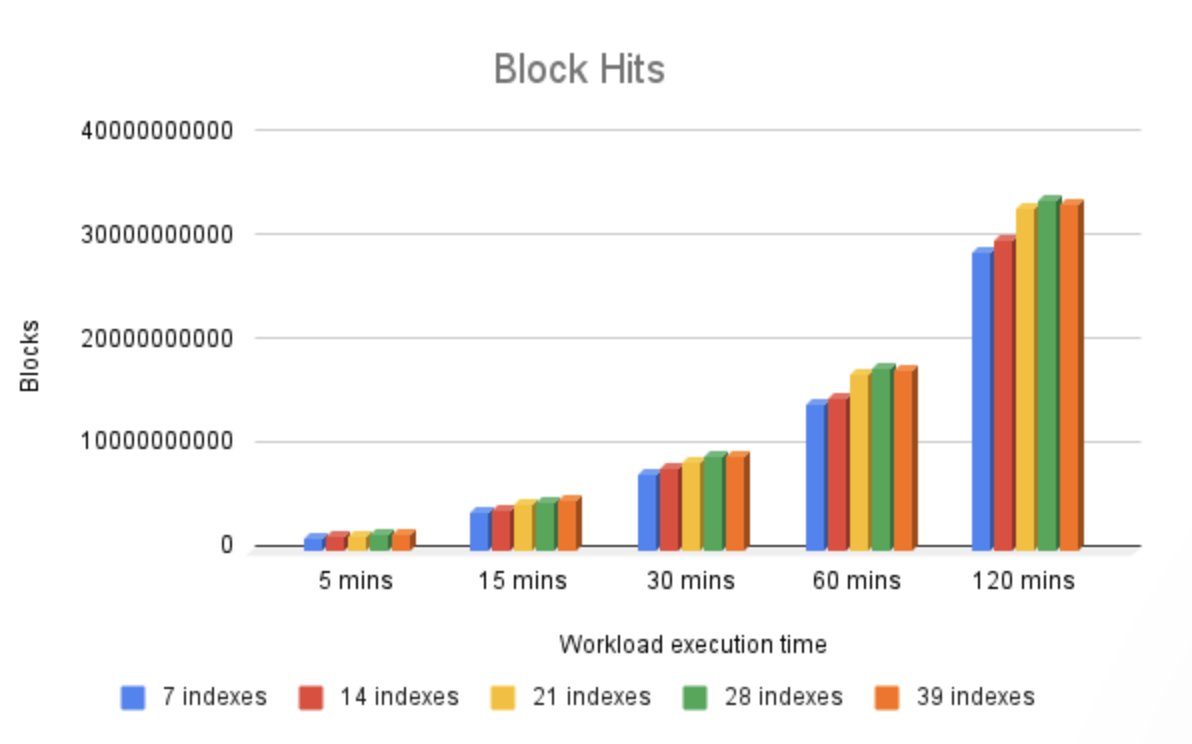
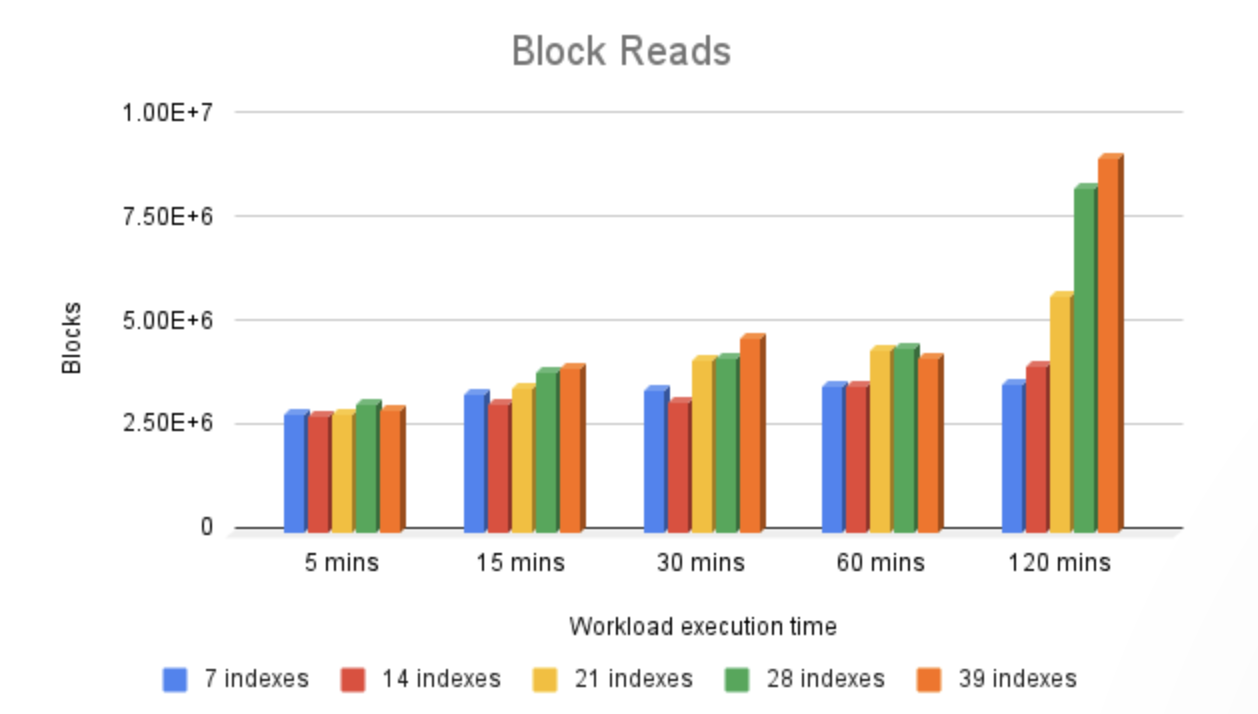
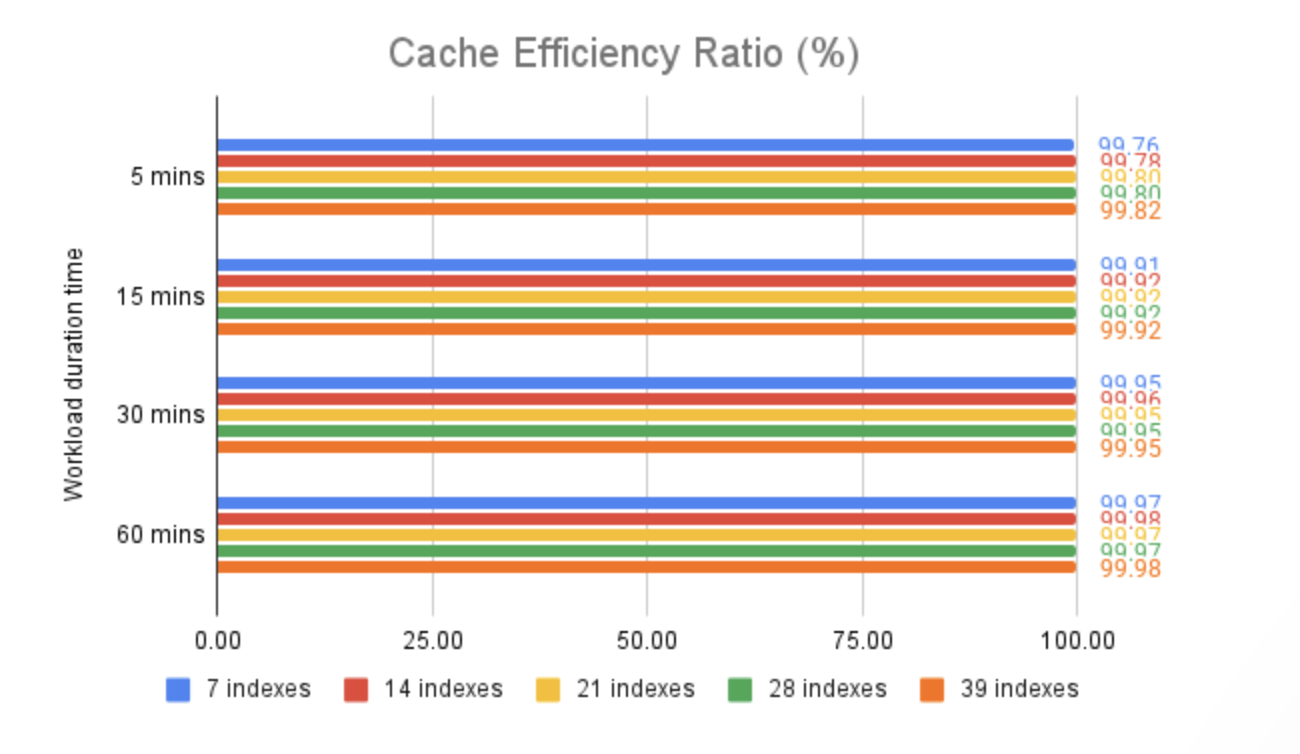
上述三张图表展示了在 PostgreSQL 缓存(shared_buffers)和 I/O 子系统(无论是通过文件系统缓存还是直接从物理磁盘读取)中观察到的 I/O 需求。
如图所示,在我们的基准测试中,PostgreSQL 缓存命中率始终高于 99.7%,这并非巧合。我们的初始数据集、测试轮次、服务器上的可用内存量以及 PostgreSQL 配置参数都经过精心设计,以尽量减少潜在瓶颈,例如读写操作命中物理存储。相反,指标清楚地显示,大多数情况下,数据直接从 PostgreSQL 缓存中提供。
关于 PostgreSQL 基准测试的结论
这个基准测试并不是为了评估 PostgreSQL 的事务能力,也不是为了阻止使用可以为应用程序带来性能优势的索引。索引的优势是众所周知且广泛记录的。
相反,这个基准测试旨在展示在数据修改操作(INSERT、UPDATE、DELETE)期间过度索引或保留未使用的索引所带来的负面影响。这些未使用的索引不仅没有好处,还会引入可测量的性能下降。
这种设置允许进行有意义的同类比较,其中性能偏差主要归因于索引开销。结果显示,尽管索引对于性能至关重要,但过度或不必要的索引可能会显著降低写入吞吐量和事务性能,有时在压力测试下才会明显暴露出来。
这个基准测试还旨在为希望权衡 PostgreSQL 中积极索引策略的开发人员、数据库管理员和架构师提供一个实际参考。这不是关于删除索引,而是关于选择哪些索引真正有价值。
最后,需要指出的是,这些结果反映了在完全受控环境中由于过度索引导致的性能下降,所有变量和配置都经过精心调整,以隔离并展示过度索引的影响。
在生产环境中,你很少会遇到如此有利的条件;你的应用程序可能会引入并发问题,你的数据集可能无法完全放入内存,你的缓存命中率可能会显著降低,所有这些都会放大性能损失。
因此,这个基准测试只提供了一个实际的参考框架,以验证理论已经提示的内容。
你选择 PostgreSQL 是因为它具有灵活性、性能和成本节约的优势——但即使是经验丰富的 IT 领导者也可能在途中遇到可以避免的陷阱。以下是一些需要注意的地方。
原文地址:https://www.percona.com/blog/benchmarking-postgresql-the-hidden-cost-of-over-indexing/
原文作者:Pablo Svampa
