




1、什么是DMDPC
DMDPC是达梦分布计算集群,英文Distributed Processing Cluster的简称。是基于raft协议来实现的分布式一致性数据库架构,具有可扩展、高性能、高可用、高吞吐量等高级特性,适用于OLTP、OLAP以及HTAP场景。
一个基础DPC架构,是需要一个SP节点、一个MP节点、2个BP节点,至少需要两个BP节点才能看出来子任务的各种计划形态和调度。
优点:计算与存储分离、支持PB级的数据存储、实现动态伸缩、不依赖监视器、更适应两地三中心的部署需求。
缺点:复杂度比较高、需要的资源更庞大、本身不具备开机自启动的能力需要配置dem来拉起、对网络要求比较高、使用相对繁琐。
2、DPC的架构
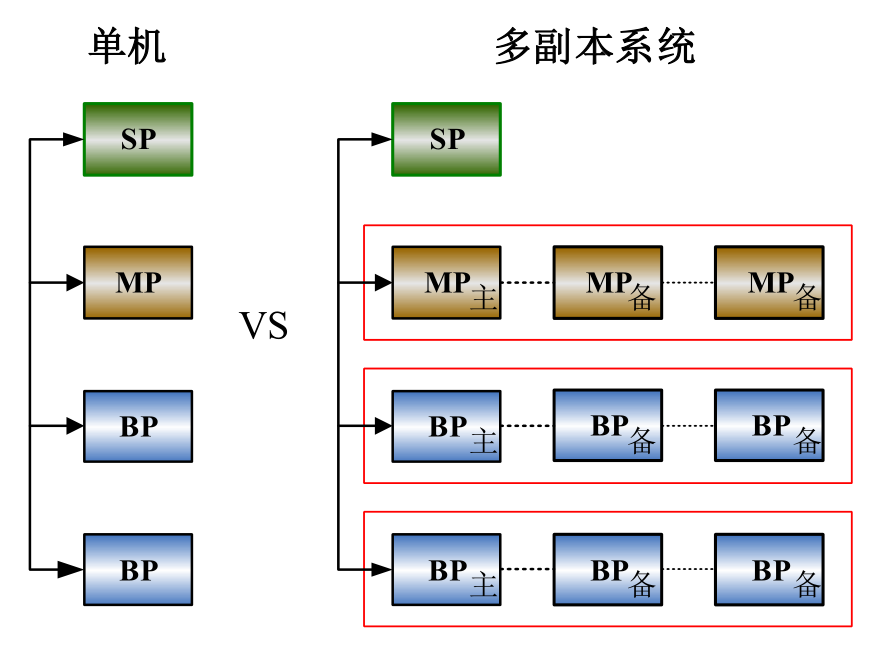
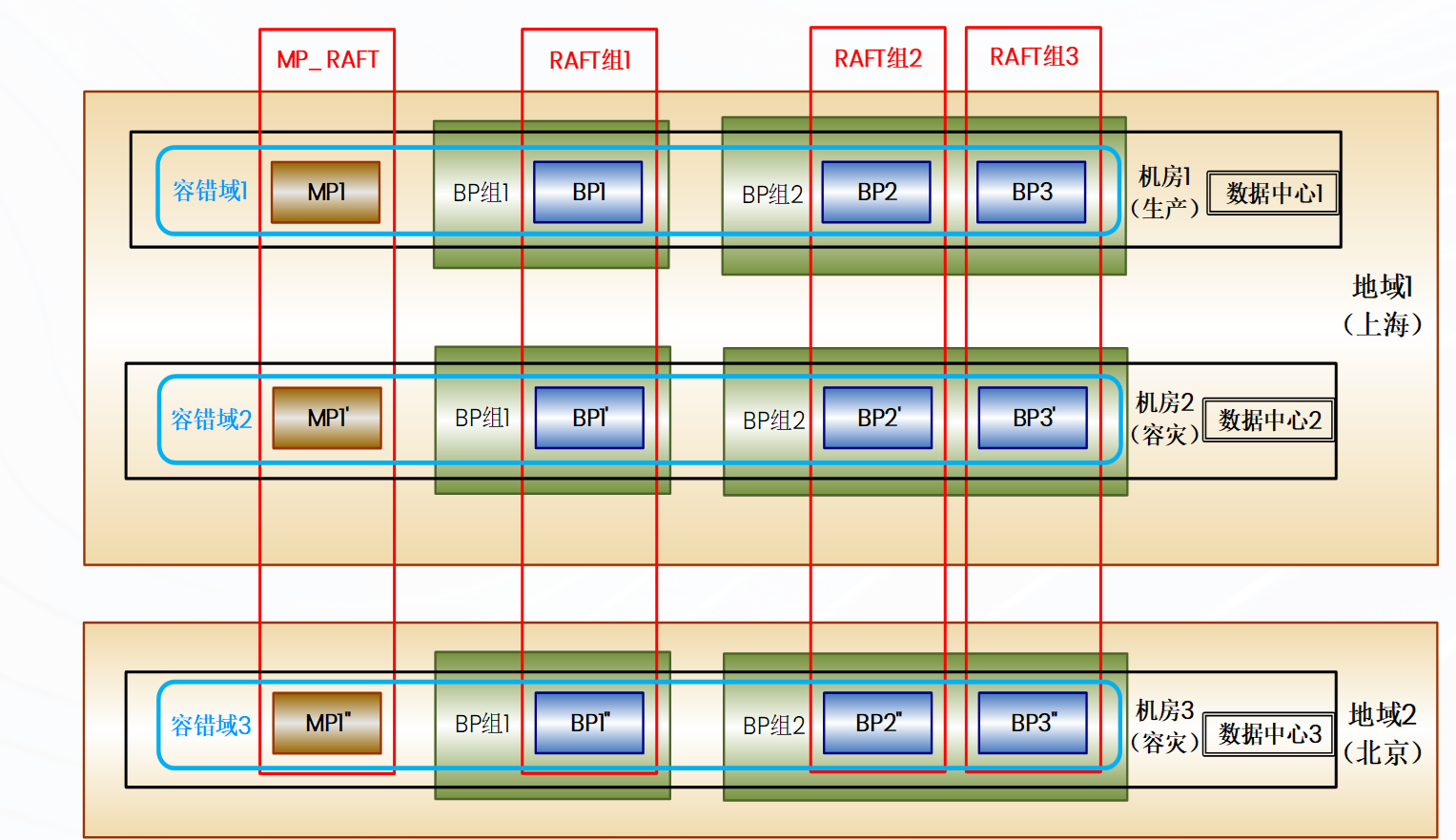
SP:对外提供数据库服务的节点,不存储数据,只负责接收用户请求并生成计划、划分子计划、按照一定规则计算并行度并调度各个子计划,并最终将执行结果返回给用户,也就是说用户可以登录到任意一个 SP 节点,获得完整的服务。
BP:数据实际存储的节点,负责存储数据和接收 SP 的子任务调度指令,执行子任务,并返回结果给 SP。
MP:提供元数据服务的节点。所有 DDL 请求都会经过 SP 转发给 MP 执行,元数据信息全部存储在 MP。
SP作为计算节点不存储数据,所以不需要特别高的存储和IO,因其需要做大量的计算,所以对CPU有一定的要求,最好选择具有高主频和多核心的处理器;BP节点存储实际数据,所以需要具有快速读写和低延迟的存储设备,每个节点需要大量的内存来缓存数据和索引来减少磁盘IO操作,MP节点存储并提供元数据信息服务所以对资源需求不是高,SP、BP节点理论上可以无限扩张,所以作为单节点的MP可能会成为性能瓶颈,所以如果是一个大型系统建议提高MP节点资源。最后是网络要求,因为分布式架构需要高速的网络连接来确保MAL通信顺畅,建议使用万兆以太网,当然具体的硬件配置应根据实际情况进行调整,例如数据量、并发用户数、业务类型等。
3、DPC的使用和管理
3.1 表空间管理
DMDPC的分布式存储就是依赖于创建分区表时指定表空间,实现的节点间数据分片从而实现数据重分布等功能。
创建存储在 RAFT_1 的普通表空间 TS_1 和存储在 RAFT_2 上的混合表空间 TS_2。
CREATE TABLESPACE TS_1 DATAFILE 'TS_1.DBF' SIZE 128 STORAGE( ON RAFT_1);
CREATE TABLESPACE TS_2 DATAFILE 'TS_2.DBF' SIZE 128 WITH HUGE PATH '/dmdata/data/dpc_data/bp2/DAMENG/hts' STORAGE( ON RAFT_2);
表空间组是一组表空间的集合。表空间组对象存储在系统表 SYSTSGROUPS 中,表空间组通过系统过程进行管理。
-- 创建一个表空间组 TSG_1。
SP_TS_GROUP_CREATE('TSG_1', 'tablespace group1');
-- 删除表空间组 TSG_1。
SP_TS_GROUP_DROP('TSG_1');
-- 向表空间组 TSG_1 中添加表空间 TS_1。
SP_TS_GROUP_ADD_TS('TSG_1', 'TS_1');
-- 删除表空间组 TSG_1 中的表空间 TS_1。
SP_TS_GROUP_REMOVE_TS('TSG_1', 'TS_1');3.2 用户管理
用户可以指定和修改默认表空间/表空间组。指定表空间和单机一致。
-- 创建一个指定默认表空间组的用户。
CREATE USER USER_1 IDENTIFIED BY USER1_psd DEFAULT TABLESPACE GROUP TSG_1;
-- 修改用户的默认表空间组。
ALTER USER USER_1 DEFAULT TABLESPACE GROUP TSG_1;3.3 分区表管理
DMDPC 创建表语法和单机类似。不同分区指定不同表空间实现分布式存储的功能。
create table test1(c1 int, c2 int) PARTITION BY RANGE(c1)(
PARTITION p1 VALUES LESS THAN (10) storage (on TS_1),
PARTITION p2 VALUES LESS THAN (20) storage (on TS_2),
PARTITION p3 VALUES EQU OR LESS THAN(MAXVALUE) storage (on TS_3));3.4 分区组管理
分区组(Partition Group,PG)是 DMDPC 为了简化水平分区表建表操作而提供的一项新功能。它是将多个表的分区规则统一提取成一个独立的逻辑概念,然后创建分区表时就可以基于此分区组来创建,达到一个简化建表的操作。分区表和分区组是一对多的关系。同时相同分区方式两张表的对应分区始终在同一BP中,减少跨机事务和连接时数据交换开销,提升事务处理的性能。
-- 创建一个分区列类型是整型的范围分区组 PG1,指定每个分区的存储表空间。
create partition group PG1 partition by range(int)
(
partition p1 values less than(10) storage (on TS_2),
partition p2 values less than(40) storage (on TS_1),
partition p3 values less than(80) storage (on TS_2)) ;
-- 创建分区列类型是 varchar(100)的 HASH 分区组,32 个子表存储位置均匀分布在 TS_1,TS_2 上。
create partition group PG2 partition by hash(varchar(100)) partitions 32 storage (on TS_1,TS_2);
-- 创建一个二级分区组,一级分区为 HASH,二级分区为 RANGE。所有叶子表的存储位置将从 TS_1,TS_2 中挑选。
create partition group PG5
partition by hash(int)
subpartition by range(int)
(
partition "part_1" (subpartition p11 values less than(1), subpartition p12 values less than(10)) ,
partition "part_2" (subpartition p21 values less than(0) , subpartition p22 values less than(10)) ,
partition "part_3" (subpartition p31 values less than(50) , subpartition p32 values less than(60))
) storage (on TS_1,TS_2);create table DPC_T1(c int) using partition group PG1 by(c);
create table DPC_T2(c varchar(100)) using partition group PG2 by(c);
create table T_XQ64 (c int, c2 int, c3 int) using partition group PG5 by (c)
SUBPARTITION by (c3);
-- 查看每个子表的存储位置。
select(select x.name from sysobjects x where x.id = y.pid) tname, groupid as ts_id, (select name from dpc_tablespace where ts_id = groupid) as ts_name from sysobjects y, sysindexes z where z.id = y.id and pid in (select id from sysobjects where name like 'T_XQ64%' and subtype$='UTAB' and name not like '%AUX') and subtype$='INDEX' and schid = (select id from sysobjects where type$='SCH' and name = 'SYSDBA') order by tname asc;
//查询结果如下:
行号 TNAME TS_ID TS_NAME
---------- ----------------- ----------- -------
1 T_XQ64 7 TS_1
2 T_XQ64_part_1 8 TS_2
3 T_XQ64_part_1_P11 7 TS_1
4 T_XQ64_part_1_P12 8 TS_2
5 T_XQ64_part_2 7 TS_1
6 T_XQ64_part_2_P21 7 TS_1
7 T_XQ64_part_2_P22 8 TS_2
8 T_XQ64_part_3 8 TS_2
9 T_XQ64_part_3_P31 7 TS_1DROP PARTITION GROUP <分区组名> [FORCE]分区组被使用后无法直接删除,此时可指定 FORCE 选项强制删除分区组,基于该分区组创建的表对象不会被删除,但是表的 DDL 属性会发生变化,不再依附于分区组。
3.5 DPC参数
- DPC_TRX_TIMEOUT:表示事务等待超时时间。取值范围 0~604800。单位秒,默认10,动态,会话级
- RLOG_RAFT_NEED_WAIT:默认3,任意归档状态有效的备库存在日志堆积,根据 RLOG_RAFT_WAIT_TIME 暂缓日志包发送。
- RLOG_RAFT_WAIT_TIME:备库出现堆积后,RAFT 主库延迟发送等待时间,取值范围 0~3600000,单位 MS,默认1000。仅RAFT 主库生效,动态,系统级。
- SQC_GI_NUM_PER_TAB:每个表拆分的扫描单元个数。取值范围 1~1024。 扫描表对象时,每个表可以被拆分成多个单元以提升并行性能。参数值表示拆分的单元个数,每个单元可以独立用于工作线程的扫描任务。例如:需要扫描一个子表且子表数据量较大,为充分利用工作线程资源,可以调大此参数以使用分区内并行。默认1,不拆分。
- STAT_CACHE_FLAG:SP 是否缓存表行数。默认1,SP 缓存表行数,而不是每次都向 MP 请求表行数。
- STAT_CACHE_CAPACITY:SP 缓存表行数的缓存容量。取值范围 100~100000000,单位为缓存表的个数;默认1000。
- REDOS_BUF_SIZE:待重演日志堆积的内存限制,堆积的日志缓冲区占用内存超过此限制,则新的日志将会被延迟加入重演队列,等待重演释放部分内存后再加入。单位 MB,默认1024。
- REDOS_BUF_NUM:待重演日志缓冲区允许堆积的数目限制,超过限制则新的日志将会被延迟加入重演队列,等待堆积数减少后再加入。以个数为单位,默认4096。
- RLOG_PKG_SEND_NUM :默认1,主库启动异步恢复时,连续发送设定值个日志包以后需要等待备库响应。取值范围1~200。缺省值1表示每发送一个日志包就要等待一次响应。如果主备库之间存在比较大的网络延迟,可以通过调大此参数以提升主库的日志发送速度。动态,系统级。
- RAFT_HB_INTERVAL:主库广播心跳消息的间隔时间。单位 MS
- XMAL_HB_INTERVAL:节点间通信检测间隔。单位 S
- RAFT_VOTE_INTERVAL:选举超时时间。这个配置值需要保证至少是 RAFT_HB_INTERVAL的 2 倍大小,确保在选举超时时间内能够收到主库的心跳消息,避免误判主库故障发起无效选举。建议各实例配置为不同的值,以便能够快速选举出主库。
3.6 常用的系统函数
- SP_RAFT_SUSPEND_THREAD 挂起主库
- SP_RAFT_SWITCHOVER 备库启动一轮特殊选举,使备库选为新leader
- SP_RAFT_TO_SINGLE: 将集群中的一个副本节点强制降为单节点,直连对应节点执行。
- SP_SET_RAFT_ELECT(0); 如果哪个节点不需要参与选举,可以关闭当前 RAFT 库节点的选举开关。
3.7 常用视图和系统表
select * from DPC_BP_RAFT;select * from DPC_INSTANCE;select * from DPC_TABLESPACE;select * from V$DPC_MP_CFG;select * from V$RLOG_RAFT_INFO;select * from V$TABLE_ROWCNT_CACHE;select * from V$DPC_TS_MOVE;select * from V$DPC_ESITE;4、一条查询SQL的处理流程
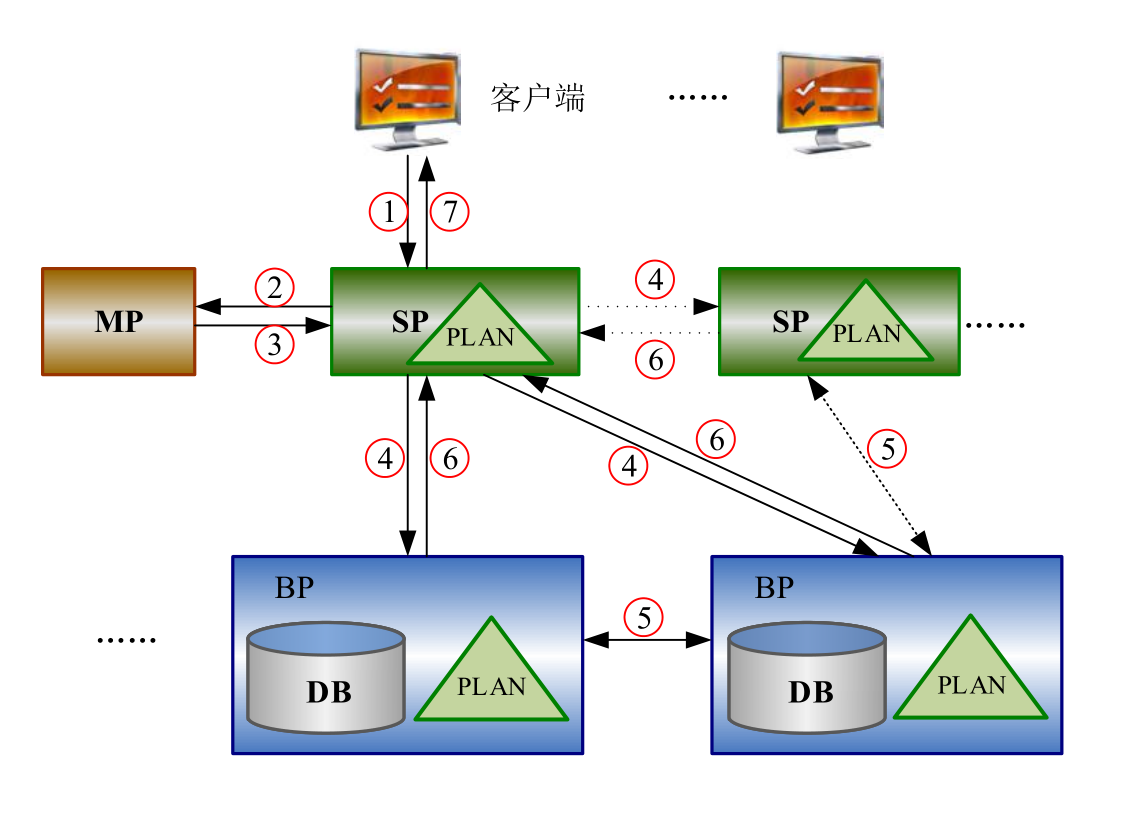
4、SP生成执行计划并拆分执行计划,需要提取数据的子计划发送给BP(主),需要计算的子计划由一个或多个SP节点共同计算。
5、BP接受到子计划并执行,不同主BP之间如果需要数据交互,就会做一下数据交换。
5、raft一致性协议
5.1 raft角色
1、领导者(leader):可以理解是主节点、负责接收并处理来自客户端的请求,决定数据的更新,并将这些更新发送给其他节点。
2、跟随者(follower):可以理解为从节点,接收并执行领导者的指令。跟随者不会自己做决定,只是服从领导者
3、候选者(candidate):当领导者失效或者是要选举新的领导者时,节点会成为候选者,它会发起投票请求,试图成为新的领导者。
集群刚刚启动时, 所有结点都是 follower, 当 follower 收不到主结点发来的心跳时, 就会转变为 candidate, 发起 leader 选举流程。 当一个 candidate 收集了集群中半数以上结点的选票后, 就能变成 leader。 一个 leader 会持续运行直到自己宕机或者发现其他拥有更高任期 (term) 的 leader。
5.2 term
- 每一个服务器都会存储一个 current_term 的变量, 该变量允许被增大,不允许被减小。
- Raft 集群内每一个服务器对外发送请求的时候, 请求中都会携带 current_term 变量的值
- 每个服务器 S 在收到任意请求时, 会先比较自己保存的 current_term 和收到的请求中携带的 current_term'的大小
5.3 RPC
RPC(remote procedure call)是raft集群中用于服务器之间的通信,一是用来竞选过程中 candidates 发起调用, 用于收集选票;二是由 leader 发起调用, 将指令分发到各台服务器上或者作为心跳通知使用。为了提高性能,RPC调用是可以并行去发送的。
一台服务器只要能够收到来自 leader 或者 candidate 发来的 RPC 调用就会保持自己的 follower 身份。 Leader 会向所有的 follower 定时发送心跳来维持自己的权威。如果一个 follower 在一段时间后一直没有收到任何 RPC 调用请求, 它就会认为当前集群没有有效的 leader , 发起一轮新的选举。
一个 follower 的发起选举,首先将自己的 current_term + 1将自己的身份转变为 candidate,然后给自己投一票, 并向集群中所有其他服务器发起 RPC 并发调用,最后就会有三种情况,一种是成功获得了选举,第二种有其他服务器当选 leader , 自己竞选失败,最后就是大部分服务器都宕机了,谁都没有竞选成功。
5.4 raft归档
多副本模式是采用raft归档的方式来进行主备同步的,与实时归档不同的是,主库再redo包写入联机日志文件之前传送给备库,不需要等待备库给出信号主库正常继续往下执行,备库收到日志包加入自己的重演队列进行重演,日志刷盘后会给主库一个信号,主库根据消息来确定是否需要推进 C_SEQNO 和C_LSN(C_SEQNO是已经提交的日志包序号,C_LSN 是已经提交的日志包中的最大 LSN),包括主库自己超过半数节点刷盘后,主库就会将此日志包的序号和LSN设置为C_SEQNO和 C_LSN,主库会在下次日志包和心跳消息中附加当前的 C_SEQNO 和 C_LSN 发送给备库,备库收到后,根据此信息推进自己本地的 C_SEQNO 和 C_LSN 值。如果其中一个备库未发送消息给主库,主库超过一定时间就会断定该备库失联,将其归档状态设置为失效,不再向故障备库同步数据。
6、故障恢复
1、主库故障
主库故障后很快恢复(数据库重启、网络重启),这种类似短暂失联,其他备库还未来得及发起选票或者发起选票但是还没有竞选成功,老主库会重新成为leader,直接将其切换为 Open 状态即可。
如果主库故障恢复后,有备库竞选为新主会自动将老主库切换为备库重新集群。如果老主库有未提交的日志,而新主上没有该日志,为了保持一致性,需要对该日志做截断处理。
2、备库故障
多数情况下,一个或少数备库故障不会影响集群,恢复后自动重加入集群即可,恢复后当前主库会自动向其发起异步恢复流程,直到和主库数据完全一致后,将其归档状态设置为有效状态,然后再次回到正常的数据同步当中。(如果恢复失败就重做备库)
极端情况下,大多数备库集体失联了,超过一定时间,主库会变成只读状态,直到大多数节点恢复了,主库会自动变为open状态。

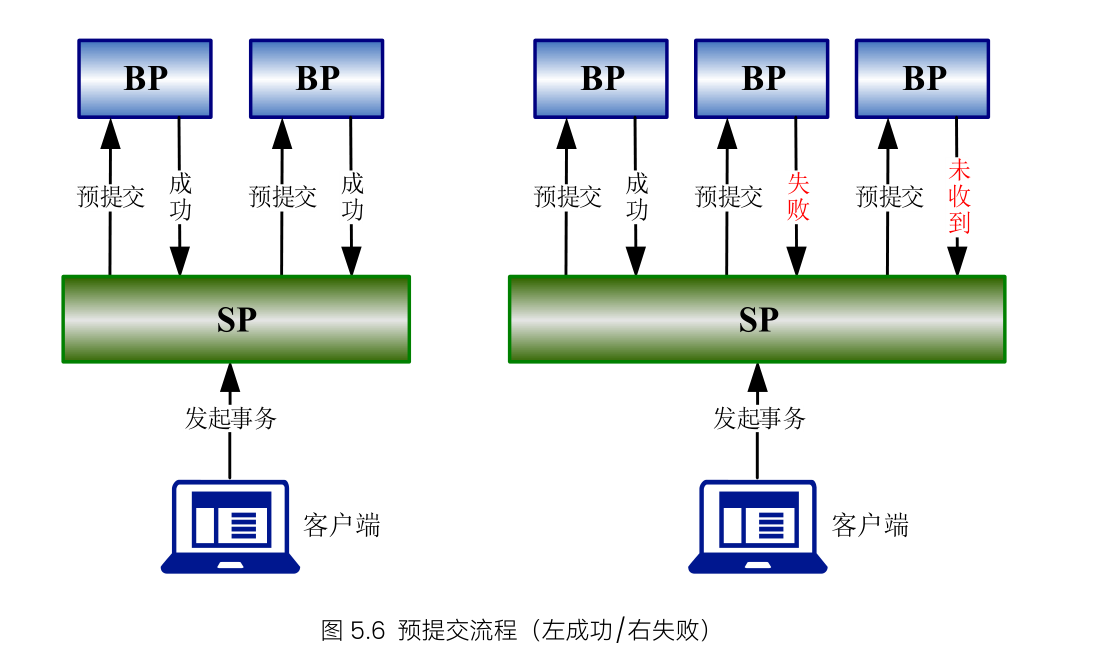
7、两阶段提交
DMDPC这里的两阶段提交是说的SP和BP。保证多个BP分布式事务一致性,SP作为全局的协调者,客户端发送请求到SP,SP进入预提交阶段通常称为prepare阶段,分发请求到BP等待BP响应,BP接受到分发的命令写入日志并响应SP,只有所有BP均Commit SP才可以进入第二阶段提交。否则所有BP进行回滚,SP返回客户端“事务提交失败”。
8、动态增删节点
一是横向增删 SP 或 BP 节点。二是纵向增删 MP 或 BP 多副本系统中的副本节点。
8.1 增删SP节点
新增
第一步,为SP创建一个新的RAFT组,名称为RAFT_SP1
SP_CREATE_DPC_RAFT('SP', 'RAFT_SP3');
第二步,在RAFT_SP1内注册SP实例,名称为SP_1。此处的实例SP_1是提前初始化好的
SP_CREATE_DPC_INSTANCE('RAFT_SP3', 'SP_3', 'SP', 6010, 5239, '192.168.126.128', '','NORMAL', 2, 'SP instance');
第三步 将MP.INI文件拷贝到SP的库目录DAMENG下删除
第一步 移除SP实例
SP_DROP_DPC_INSTANCE('SP_3');
第二步 删除RAFT组
SP_DROP_DPC_BP_RAFT('RAFT_SP');8.2 增删BP节点
新增
//第一步 创建一个新的RAFT组,名称为RAFT_1
SP_CREATE_DPC_RAFT('BP', 'RAFT_3');
//第二步 注册一个BP实例,名称为BP31。此处的实例BP31要提前初始化好
SP_CREATE_DPC_INSTANCE('RAFT_3', 'BP31', 'BP', 6011, 5250, '192.168.126.128', '','NORMAL', 1, 'BP instance');
//第三步 创建一个新的BP组,名称为BG_1
SP_CREATE_DPC_BP_GROUP('BG_1', 'bp group1');
//在BP组内添加RAFT组
SP_BP_GROUP_ADD_RAFT('BG_1', 'RAFT_3');
//第四步 将MP.INI文件拷贝到BP的库目录DAMENG下删除
//第一步 移除BP实例
SP_DROP_DPC_INSTANCE('BP_3');
//第二步 删除RAFT组
SP_DROP_DPC_BP_RAFT('RAFT_3');
//第三步 删除BP组
SP_DROP_DPC_BP_GROUP('BG_1');8.3 增删BP副本
新增
第一步初始化俩实例
dminit XXXXX
第二步将新初始化的节点注册进待新增节点的RAFT_1组中
SP_CREATE_DPC_INSTANCE('RAFT_1', 'BP4', 'BP', 6606, 5242, '192.168.126.128', 'STANDBY', 0, 'BP instance');
第三步修改配置文件
dm.ini的归档打开
dmarch.ini参考其他节点本地归档写自己,raft归档写其他节点
mp.ini 与本集群的其他节点 mp.ini 文件内容一致
第四步,迁移数据
此处省略
第五步,启动节点,执行加入集群操作(主节点执行)
//将BP4,BP5以learner节点的方式加入集群,从而在不影响集群使用条件下向新节点同步日志
SP_ADD_RAFT_LEARNER('BP4','192.168.126.128',6606,4);
SP_ADD_RAFT_LEARNER('BP5','192.168.126.128',6607,5);
//将新节点加入集群
SP_ALTER_RAFT_NODE('BP1/BP2/BP3/BP4/BP5');删除
第一步,再主节点上执行移除操作
SP_ALTER_RAFT_NODE('BP1/BP2/BP3');
或
SP_DELETE_RAFT_NODE('BP4/BP5');
第二步,MP 移除 BP 实例
SP_DROP_DPC_INSTANCE('BP4');
SP_DROP_DPC_INSTANCE('BP5');
注意:如果是单副本系统要想增加副本,需要修改实例的系统模式为PRIMARY。
SP_ALTER_DPC_INSTANCE('BP1','PRIMARY',4,1);8.4 增删MP副本
新增
第一步初始化俩实例
dminit XXXXX
第二步将新初始化的节点注册进待新增节点的RAFT_1组中
SP_CREATE_DPC_INSTANCE('', 'MP4', 'MP', 10625, 5242, '192.168.1.68', 'STANDBY', 0, 'MP instance');
SP_CREATE_DPC_INSTANCE('', 'MP5', 'MP', 10626, 5243, '192.168.1.68', 'STANDBY', 0, 'MP instance');
第三步修改配置文件
dm.ini的归档打开
dmarch.ini参考其他节点本地归档写自己,raft归档写其他节点
mp.ini 加入MP4、MP5
[MP4]
mp_host = 192.168.1.68
mp_port = 10625
[MP5]
mp_host = 192.168.1.68
mp_port = 10626
同时同步到本集群的其他节点的 mp.ini 文件内容要一致
第四步,迁移数据
省略
第五步,启动节点,执行加入集群操作(主节点执行)
//将BP4,BP5以learner节点的方式加入集群,从而在不影响集群使用条件下向新节点同步日志
SP_ADD_RAFT_LEARNER('MP4','192.168.1.68',10624,4);
SP_ADD_RAFT_LEARNER('MP5','192.168.1.68',10625,5);
//将新节点加入集群
SP_ALTER_RAFT_NODE('MP1/MP2/MP3/MP4/MP5');删除
第一步,再主节点上执行移除操作
SP_ALTER_RAFT_NODE('MP1/MP2/MP3');
或
SP_DELETE_RAFT_NODE('MP4/MP5');
第二步,MP 移除 MP 实例
SP_DROP_DPC_INSTANCE('MP4');
SP_DROP_DPC_INSTANCE('MP5');
第三步修改mp.ini文件去掉MP45的配置。横向增删SP、BP节点可以灵活应对业务变化,新增SP节点可以分摊子计划的执行,新增BP节点可以分担存储压力,添加BP节点一种是存储后续数据,另一种就是将其他raft组的表空间迁移过来。
9、表空间联机迁移
表空间迁移是将整个表空间从一个 RAFT 组迁移到另外一个 RAFT 组,相比于库迁移和表迁移,表空间联机迁移效率更高,对系统正常运行影响更小。
-- 将表空间 TS_01 迁移到 RAFT_2 上,默认是只读模式,not read only指定读写方式
alter tablespace ts_01 move to raft_2 not read only;只读方式在表空间迁移的过程中,用户只能对表空间包含的表进行读操作,不能进行写操作。读写方式在迁移的过程中,用户大部分时间,比如在文件拷贝的过程中仍然能对表空间进行写操作,只在最后切换节点的短时间内写操作会被阻塞。读写方式对迁移过程中新修改的数据,通过重演日志的方式完成修改,这样对系统的影响更小,对用户更友好。
10、执行计划
DPC的分发可以通过操作符ESEND/ERECV来划分,ERECV用于接受数据,ESEND用于发送数据,其中发送操作符的sites:站点的 RAFT ID 和并行度值,例如(1:3,2:4)表示 RAFT ID 1 的并行度为 3,RAFT ID 2 的并行度为 4。
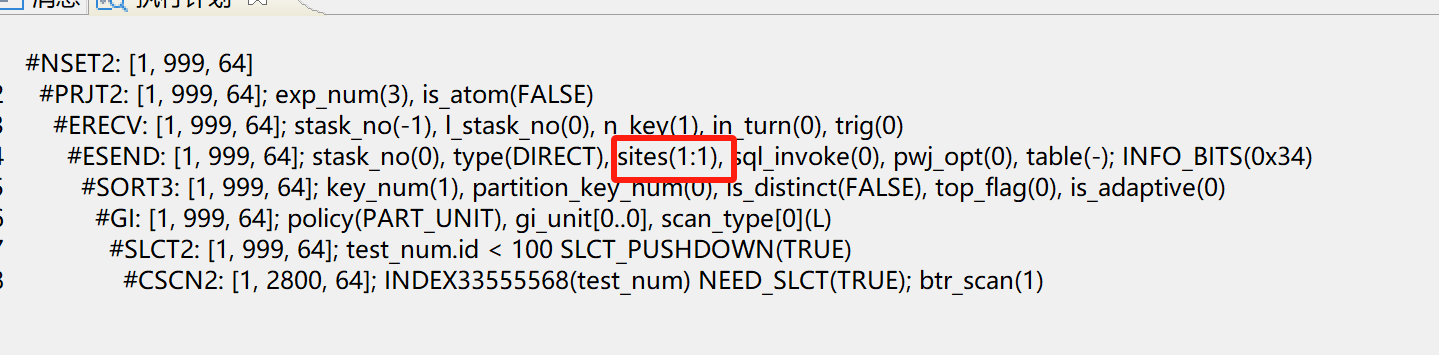
DMDPC 环境下提供了一种对指定的连接、分组、排序、去重操作符数据分发方式进行人工干预的优化器提示。该优化器提示被采纳的前提是指定的分发路径有效,因为代价原因没有被优化器选中。
其中分发方式探测序号可以在 10053 trace event 生成的 TRACE 文件中查看到,以nth_try 标示。分发方式字符串:分组、排序、去重等用一元操作符;连接、集合运算用二元操作符。
ALTER INDEX IDX_A REBUILD SHARE ASYNCHRONOUS 16;11、影子库
是多副本集群中的特殊节点,不修改数据文件,没有数据,但正常参与选举和事务提交,仅提供 V$动态视图查询的节点。只有在用户存储资源不足的时候,可以部署少量影子库来代替 RAFT 库。
