




点击上方“IT那活儿”公众号--专注于企业全栈运维技术分享,不管IT什么活儿,干就完了!!!


通过合理配置和使用 Liveness Probe 和 Readiness Probe,可以显著提高 Kubernetes 集群中应用的可靠性和可用性。遵循本文介绍的最佳实践,可以帮助开发者和运维人员更好地管理应用的生命周期,确保应用在各种情况下都能稳定运行。
健康检测的基本概念
Kubernetes 提供了两种主要的健康检测探针:
Liveness Probe(存活探针)
用于判断容器是否正在运行。如果存活探针失败,Kubernetes 会自动重启容器。
Readiness Probe(就绪探针)
用于判断容器是否已经准备好接受流量。如果就绪探针失败,Kubernetes 会将该 Pod 从服务的负载均衡池中移除,直到探针再次成功。
Liveness Probe(存活探针)最佳实践
2.1 探针类型选择
HTTP GET
适用于大多数 Web 应用。通过向容器内的指定端点发送 HTTP GET 请求,根据返回的状态码判断容器是否健康。
TCP Socket
适用于需要监听特定端口的服务。通过尝试与容器内的指定端口建立 TCP 连接,根据连接的成功与否判断容器状态。
Exec Command
适用于需要执行复杂逻辑的场景。在容器内部执行一个命令,根据命令的退出状态码判断容器健康状况。
2.2 参数配置
initialDelaySeconds(启动延时)
容器启动后等待多长时间开始第一次健康检查。应根据应用的启动时间合理设置。
periodSeconds(间隔时间)
健康检查的频率(秒)。频繁的检查可能会增加系统负担,但可以更快地发现问题。
timeoutSeconds(响应延时)
每次健康检查的超时时间(秒)。应根据应用的响应时间合理设置。
successThreshold(健康阈值)
健康检查成功的阈值。连续成功多少次才认为容器是健康的。
failureThreshold(不健康阈值)
健康检查失败的阈值。连续失败多少次才认为容器不健康并触发重启。
2.3 实践案例
假设我们有一个 tomcat 应用,我们可以分别通过HTTP GET、TCP Socket、Exec Command方式配置存活探针,然后分别模拟删除目的路径页面文件或kill主进程模拟应用运行异常,查看Liveness Probe(存活探针)触发情况。
2.3.1 HTTP GET方式
配置参数信息:

故障模拟:
进入容器pod后台,删除tomcat项目目录下的index.jsp文件,可以看到在删除index.jsp文件后,在短时间内容器pod内的服务进程以及服务端口都还在正常运行:
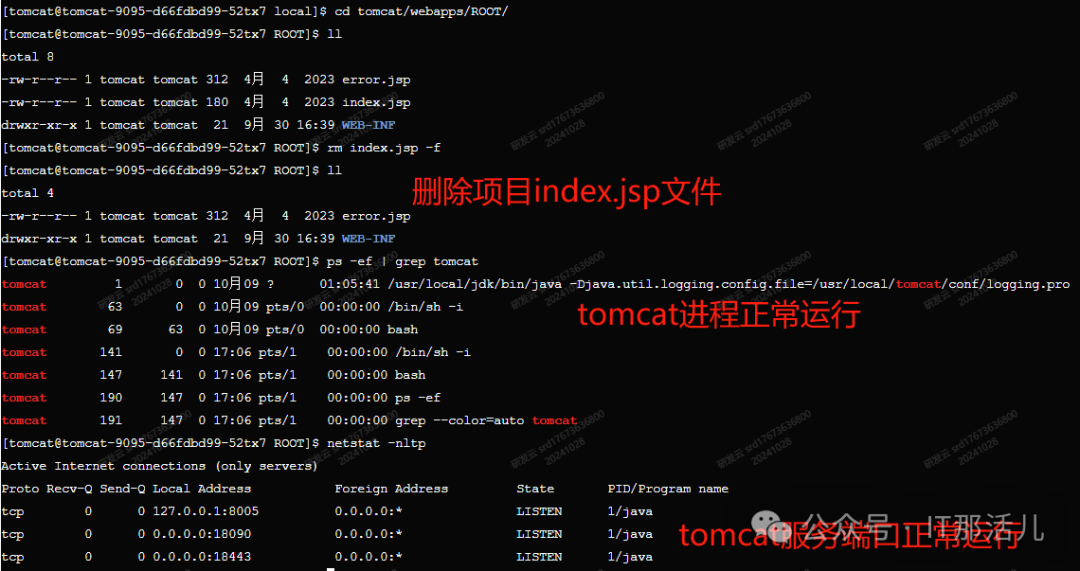
容器事件和状态:
检查容器事件,可以看到删除index.jsp文件后,容器事件出现了404的Unhealthy信息,当非健康状态连续出现配置的3次不健康阈值后,k8s会kill异常pod,然后重启pod:

总结:
通过HTTP Get方式,检查配置的路径或页面文件是否可以正常访问,当出现访问异常(一般为http状态码非200)时,会触发k8s的Unhealthy事件信息,并在unhealthy达到指定的不健康阈值次数时,将会kill掉异常pod并重启pod,以保障应用的连续稳定运行。
2.3.2 TCP Socket方式(一般不推荐使用)
配置参数信息:

故障模拟:
因为tomcat应用运行时的进程PID为1,如果直接kill掉PID 1,则会导致配置的Liveness或Readiness探针检查容器的健康状态失效,直接触发Pod的重启,暂不能模拟。
容器事件和状态:
采用TCP Socket方式时,如果配置的端口在存活探针检查下不通过,容器事件出现了Unhealthy信息,当非健康状态连续出现配置的3次不健康阈值后,k8s会kill异常pod,然后重启pod:
2.3.3 Exec Command方式
配置参数信息:
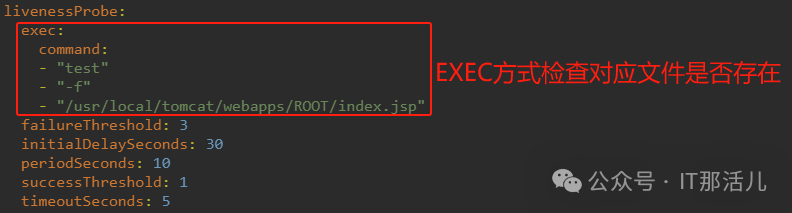
故障模拟:
此EXEC方式是检查/usr/local/tomcat/webapps/ROOT/index.jsp文件是否存在,与HTTP GET方式一样通过删除index.jsp文件模拟,不同的是HTTP Get方式是通过http状态码的方式检测容器,当删除后HTTP状态码会变为404,而EXEC方式是直接检查文件是否存在;
进入容器pod后台,删除tomcat项目目录下的index.jsp文件,可以看到在删除index.jsp文件后,在短时间内容器pod内的服务进程以及服务端口都还在正常运行:
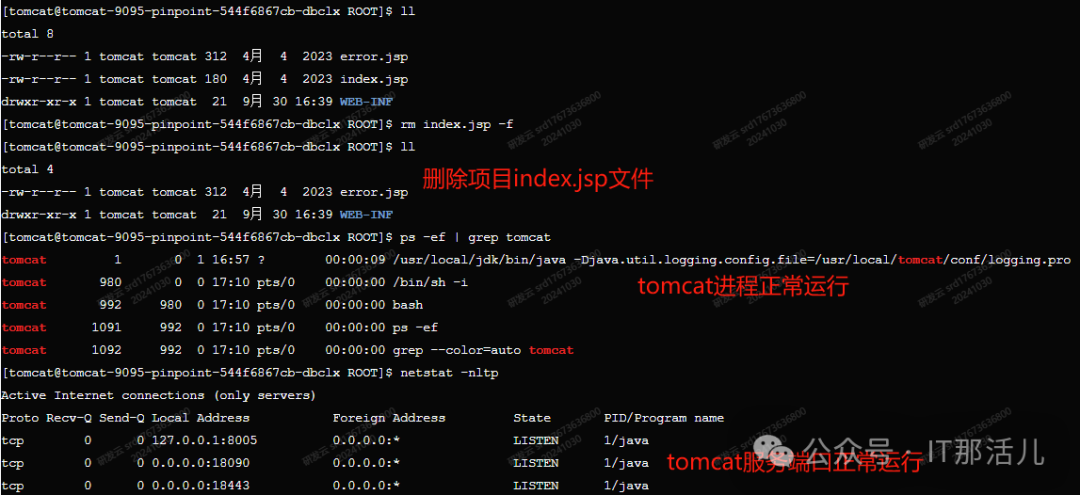
容器事件和状态:
检查容器事件,可以看到删除index.jsp文件后,容器事件出现了不同于HTTP GET方式404的Unhealthy信息,当非健康状态连续出现配置的3次不健康阈值后,k8s会kill异常pod,然后重启pod:
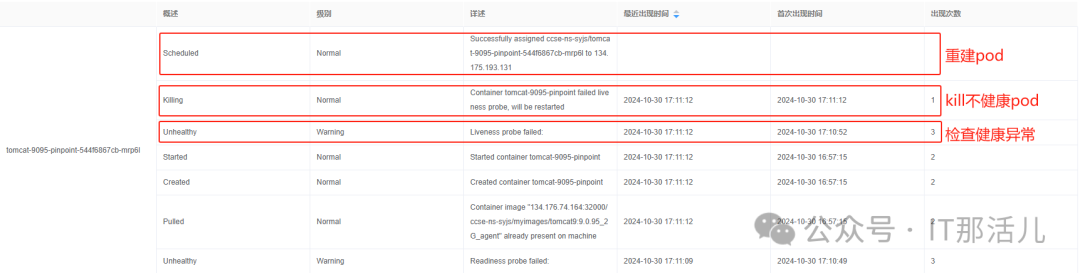
总结:
EXEC Command方式不同于HTTP GET方式和TCP Socket方式,它具有多种灵活的配置策略,例如:
1)检查文件是否存在
命令:
test -f /path/to/file

2)检查目录是否存在
命令:
test -d path/to/directory

3)执行自定义脚本
命令:
/path/to/script.sh

4)检查进程是否在运行
命令:
pgrep -x process-name

5)检查文件内容
命令:
grep -q "expected-content" /path/to/file

以上exec命令在配置时,一定要注意不要所有命令直接配置在同一行,要多行配置,除以上常见方式外,还可以根据自身应用的特性需要自定义配置。
配置的一个总的原则就是:不要出现应用进程和端口运行正常,而应用服务却已中断的情况!
Readiness Probe(就绪探针)最佳实践
Readiness Probe(就绪探针)的探针类型以及各类型的参数配置,与Liveness Probe(存活探针)完全相同,基本无区别。
要配置和使用以及说明,参考第2部分“Liveness Probe(存活探针)最佳实践”即可。
综合建议
4.1 合理配置
根据应用的具体需求调整探针的参数,确保探针能够准确反映应用的状态,在实际生产环境中:
首选推荐使用HTTP GET方式,因为它能最为准确的检查业务是否发生中断行为,若应用无HTTP接口,则次之选择EXEC Command方式,要注意使用合理的检测命令,不能简单的只检测进程是否存在和端口是否存在,因为在实际生产中,会出现进程和应用端口都在正常运行,但实际业务已经发生了中断,例如应用连接数据问题等等。
4.2 测试与监控
在实际部署前,应对探针进行充分的测试,确保它们能正确工作。同时,结合监控工具收集探针的执行结果,以便及时发现和解决问题。
4.3 文档化
记录每种服务的健康检查策略及其理由,这有助于团队成员理解和维护。
本文作者:李 林(上海新炬中北团队)
本文来源:“IT那活儿”公众号

