






关于雍正荐书
DeepSeek 火爆出圈给全民普及了一场AI应用的教育,现在DeepSeek正被各行各业的企业拿来进行本地化部署,希望与自身的业务相结合,打造出一套高效的数据体系,推动业务快速发展。
对于企业来说,首先要深入梳理自身业务流程,明确每个流程节点所产生的数据及其对业务决策的价值。然后,制定详细的数据收集计划,确保数据的准确性、完整性和及时性。
在数据收集过程中,要注重数据质量的把控,对异常数据进行清洗和修正。接下来,利用DeepSeek这样的大模型搭建数据存储和管理平台,根据业务需求对数据进行分类存储和索引,方便后续查询和调用。
在数据分析阶段,根据企业业务目标和问题,选择合适的分析模型和算法,用DeepSeek对数据进行深度挖掘,提取有价值的信息。企业还需要建立数据更新机制,不断更新和完善数据体系,确保其始终能为企业业务提供有效的支持。
那么对于企业来说,要实现上述过程的一个关键问题就是:部署完 DeepSeek 之后,到底要怎么用好它?
《大模型工程化:AI驱动下的数据体系》这本书就提供了一套完整的大模型工程化实践方法,并基于游戏经营分析场景,完整阐述如何利用大模型实现数据体系建设,给其他企业提供了极有价值的借鉴。

▼点击下方,即可购书
万丈高楼平地起,我们先来探讨大模型解决方案的核心技术有哪些。
大模型解决方案的核心技术
不少企业在信息化方面已经做了大量工作,会针对自身的业务特点构建一套经典数据中台,这对于沉淀好的已知需求的支撑性较好,尤其是大部分已经承载在数据应用系统中的需求,用户能够很方便地应用。
但对于业务创新类的需求,则需要通过大模型的能力更好地支撑业务对于数据明细、数据挖掘、数据归因和干预类的需求。要想将大模型与现有数据体系结合并发挥出强大效用,就要实现五项关键技术。
● 湖仓一体技术:采用湖仓一体架构,运用数据实时接入、虚拟数仓、冷热分层等技术,能够针对大模型生成的实时明细数据,高效执行分析探索类的SQL查询语句。通过资产整合、物化视图等方式,能够低成本、高效率地使用数据。
● 数据资产技术:将语义资产技术和实体资产技术结合。语义资产技术可以对知识和信息进行语义建模,提高资产的可维护性、可理解性和可应用性;通过实体资产技术,实现语义资产智能地转换为实体资产、实体资产智能地改写语义资产,快速地实现用户的需求。
● 资产推荐技术:根据场景和用户的需求,通过数据分析和机器学习算法向用户推荐合适的数据资产。向用户推荐的资产既要满足用户直接使用的需求,更要适应大模型的使用要求,确保人能够理解,AI也能理解。
● 智能引擎技术:通过工程化的机制将大模型的能力、资产推荐能力、工具能力和Agent能力进行智能集成和调度,实现不同应用场景下的灵活适配,最终用户可以无感地通过AI解决数据需求。
● 智能运营技术:根据预设的规则和算法,对运营过程中的问题和需求进行识别、分析和决策,并自动执行相应的操作和调整。将治理问题转换成技术问题,通过采取低成本的迭代策略,让系统越用越好用。
上述五项关键技术的实现和落地,就是全新的大模型解决方案的核心。

本书作者团队成员来自腾讯游戏数据团队,他们在大模型兴起之后积极地探索研究,实施并落地了基于AI与湖仓一体技术的数据资产方案,从而达成了在AI驱动下构建数据体系的目标。
我们来认识一下这些技术过硬、实践经验丰富的作者们。
张凯
腾讯专家工程师,主要从事游戏的大数据分析工作。具有10多年的互联网从业经验,先后负责游戏安全对抗、反欺诈对抗、游戏大数据应用等项目。曾主编3本畅销图书,荣获异步社区“2023 年度影响力作者奖”。
司书强
腾讯资深专家工程师,负责游戏业务的数据工程、数据分析等工作。在大数据技术工程、数据分析、商务智能、企业级数据治理等领域有10年以上的实践积累,主导并落地多个大型企业数据体系建设。
刘岩
腾讯资深专家工程师,曾任三一重工智能制造研究院院长。目前负责腾讯游戏AI驱动下的数据体系建设工作,曾负责全球“灯塔工厂”建设。在数据驱动业务、业务流程重构、数据智能应用等领域有20年以上的工作经验,主导并落地多个大型企业数字化转型项目。
张昱
腾讯资深工程师,主要从事游戏大模型、大数据应用等工作。具有10年大数据、数仓技术和数据分析领域从业经验,曾先后负责云产品研发、大数据治理、湖仓一体和大模型应用等项目。
戴诗峰
腾讯资深工程师,主要从事游戏的数据治理规划与架构工作。具有近20年的数据领域工作经验,参与多个领域大数据平台和数据治理的咨询与交付工作,擅长数据资产体系、数据资产持续运营、数据治理标准等方面的规划与设计。
谢思发
腾讯资深工程师,主要从事游戏行业的算法研究工作。具有8年以上的大数据搜索推荐实战经验,曾先后负责游戏用户画像建设、推荐系统建设及游戏知识图谱(游谱)系统的建设与应用。曾发表多篇学术论文和专利,在OGB挑战赛等国际赛事中获得佳绩。
李飞宏
腾讯专家工程师,主要从事游戏的大数据平台研发及治理工作。具有10多年的大数据行业从业经验,曾先后负责游戏大数据分析平台、游戏数据治理平台、游戏大数据应用等项目,主编并参与多个腾讯数据治理标准的编写工作。
看到业界对大模型应用的热切期盼,作者团队决定将自己的实践经验编撰成书,通过介绍项目中积累的技术体系与方法论,助力读者构建起体系化的思维模式,使读者可以具备全局化视野,提出系统化的解决方案。
我们现在来学习大模型工程化的实践之道。
大模型工程化要这样做
本书系统呈现了在实际场景中有效利用大模型构建数据体系的方法,推动AI技术落地应用。书中内容分为6个部分,从理论到实践,层层递进,读者可循序渐进地学习,筑牢基础,学以致用。
第一部分:大模型技术的发展与应用
该部分详细阐述大模型的发展历程、市场规模,以及通用大模型、领域大模型的应用现状。同时,将大模型与数据体系紧密联系起来,探讨业务对数据体系的需求,以及经典数据中台解决方案的优劣,进而提出大模型带来的新机遇和全新的解决方案。
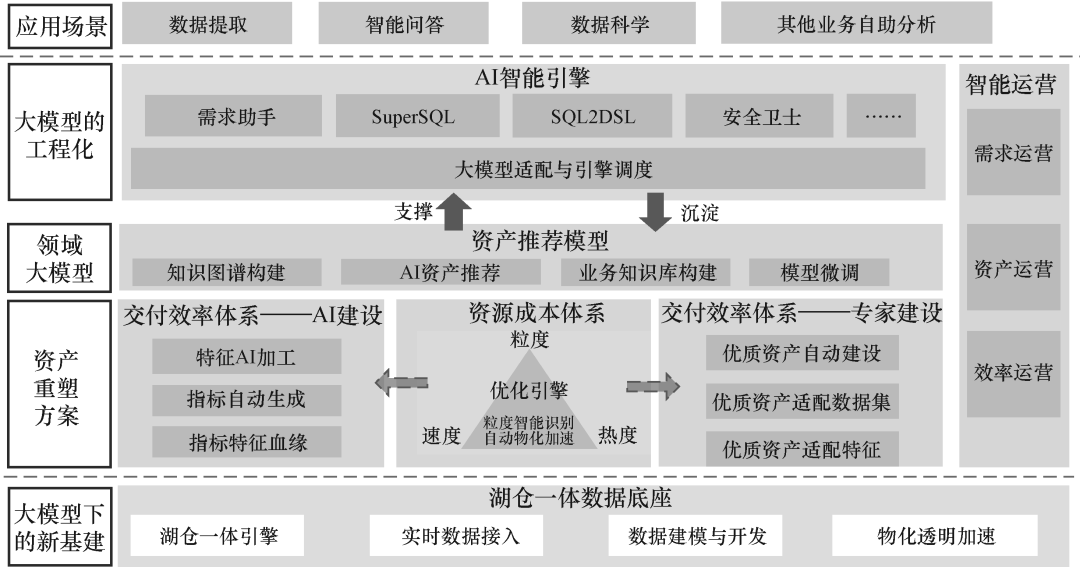
▲全新的大模型解决方案架构
第二部:大模型下的关键基础设施
湖仓一体引擎是核心内容之一,它融合了数据湖和数据仓库的优势,通过存储计算分离、数据冷热分层和湖仓一体化等关键技术,实现了高效的数据处理与存储。还介绍了实时数据写入和高效数据分析技术,为数据的快速处理和分析提供了有力支持。
第三部分:大模型下的数据资产
该部分详细分析了数据资产方案的现状,指出存在的核心挑战,如非结构化标准缺失、建设和治理成本高、运营目标不一致等。
针对这些问题,提出了重塑数据资产的思路,并深入介绍了需求资产、特征资产和库表资产的标准、建设及运营方法,让数据资产能够更好地服务于业务。
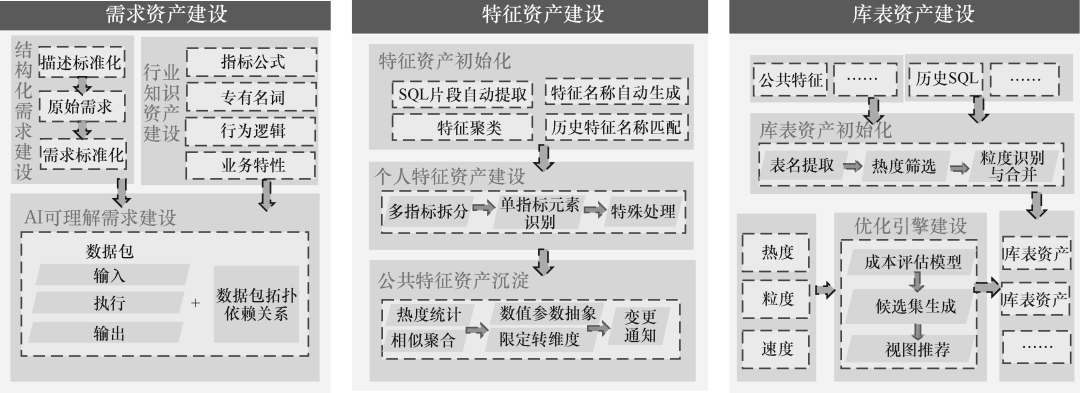
▲数据资产建设的整体流程
第四部分:自研领域大模型的技术原理
该部分从通用大模型的局限性和领域大模型的优势出发,探讨了领域大模型的构建方案、模型选型等。对需求理解、需求匹配和需求转译算法进行了深入研究,这些算法能够让大模型更精准地理解用户需求,实现从需求到数据资产和查询的高效转化。
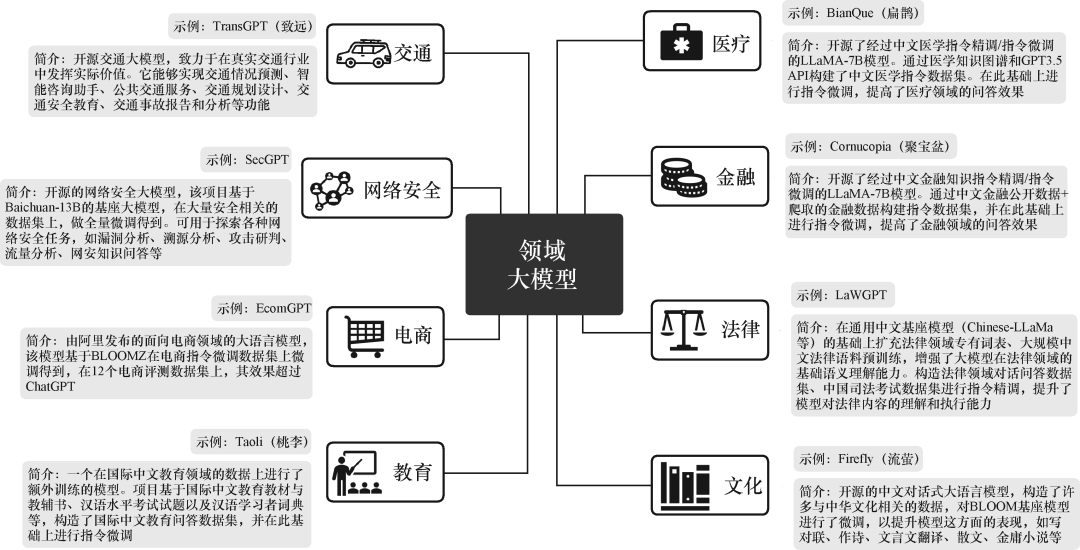
▲各行业领域大模型
第五部分:大模型的工程化原理
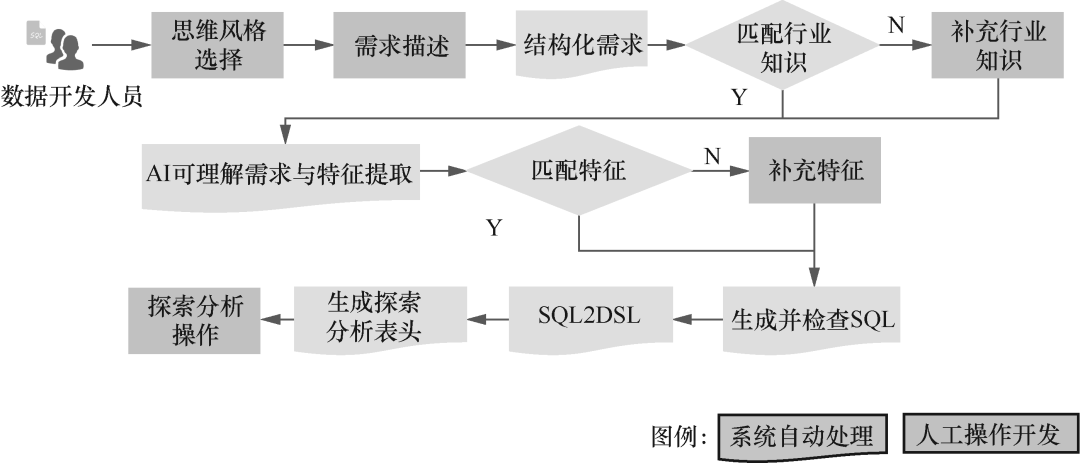
该部分介绍工程化的背景、定义和理念,明确工程化的核心与建设思路。详细讲述技术筹备工作,包括技术调研评估、大模型应用框架、提示词工程和开发环境准备。还对工程化建设要点和安全策略进行了深入探讨,确保大模型工程化的顺利实施和系统的安全稳定运行。

▲大模型工程化建设的业务流程
第六部分:游戏领域应用案例
该部分展示了大模型在实际业务中的应用。通过介绍游戏经营分析的背景,详细阐述智能助手系统架构,以及代码生成应用和探索分析应用的实践,让读者更加直观地了解大模型在具体行业中的价值和实现方式。
读者将这6个部分扎实掌握,一定能够在工作中游刃有余,做好大模型工程化的开发与应用。
结语
《大模型工程化:AI驱动下的数据体系》围绕大模型在数据体系建设中的应用展开,从基础概念和技术原理,逐步深入解决方案,为读者提供了宝贵的一手实践经验。
本书一大特点是内容系统全面,涵盖大模型技术的发展、关键基础设施、数据资产、领域大模型技术原理、工程化原理以及游戏领域应用案例等多个方面,具有完整的知识体系。

▲精彩书摘
另一大特点是聚焦实战应用,基于游戏经营分析场景,以实际案例为导向,详细阐述如何利用大模型构建数据体系,使理论知识紧密结合实践,为读者提供可落地的解决方案,助力解决实际工作中的问题。

本书突出AI在数据体系建设中的核心作用,从数据资产重塑、需求理解与匹配算法,到工程化全流程,充分展示了AI技术提升企业数据体系的效能和价值。
对于数据工程师、软件开发者、企业决策者来说,都能从书中汲取有价值的信息,在大模型时代更好地开展相关工作,推动AI技术与业务的深度融合。

小编口水都说干了
抽出3本送给小伙伴

活动时间
即日起至 2025 年 5 月 10 日 16:30
活动规则
关注爱可生开源社区公众号的用户均可参加; 用户可扫描下方活动程序码,参与抽奖;
邀请好友助力,成为铁杆粉丝,可增加中奖概率。

获奖说明
2025 年 5 月 10 日 16:30 系统自动开奖。
开奖后的 3 天内,获奖用户请填写中奖信息和邮寄信息,超时视为放弃。
本活动最终解释权归爱可生开源社区所有

没有中奖的小伙伴!限时折扣~

✨ Github:https://github.com/actiontech/sqle
📚 文档:https://actiontech.github.io/sqle-docs/
💻 官网:https://opensource.actionsky.com/sqle/
👥 微信群:请添加小助手加入 ActionOpenSource
🔗 商业支持:https://www.actionsky.com/sqle

