






欢迎阅读 RisingWave 2025 年 4 月产品月报!本期内容将为您带来过去一个月的产品更新、文档优化、博客发布动态,以及即将上线的精彩活动,敬请关注!

产品更新
RisingWave Cloud
Kafka 源向导(Kafka Source Wizard):我们推出了精简版 Kafka 源向导,以简化数据管道的设置。新的工作流程可以自动获取主题,根据样本数据生成 Schema,从而免去了人工检查。现在还可以将关键元数据字段(如键、分区和时间戳)直接作为表列包含在内。
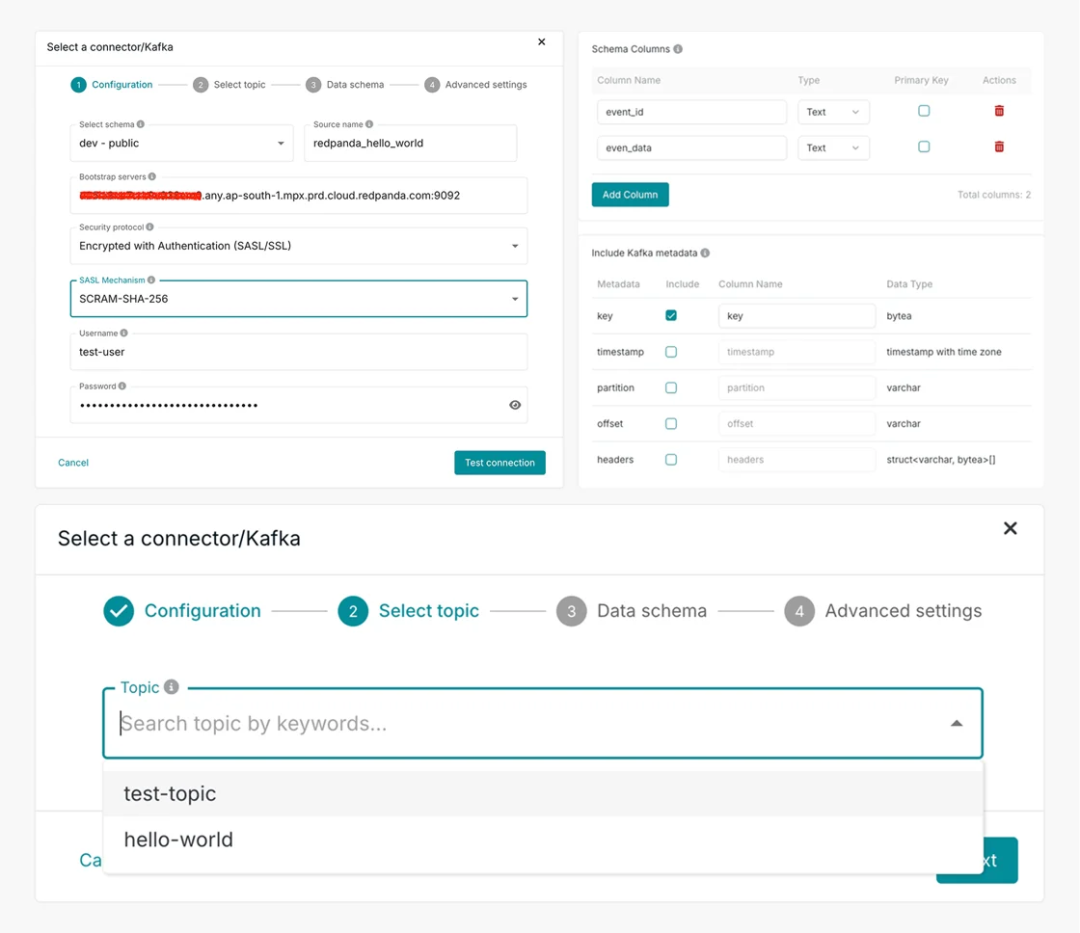
Kafka Source Wizard|图源:RW 表详情页(Table Details Page):现在可以查看表的详细信息,包括关键指标、设置和模式概览。此次更新后,RisingWave 为所有主要数据对象(Sources、 Sinks、物化视图和表)提供完整的详情页面。
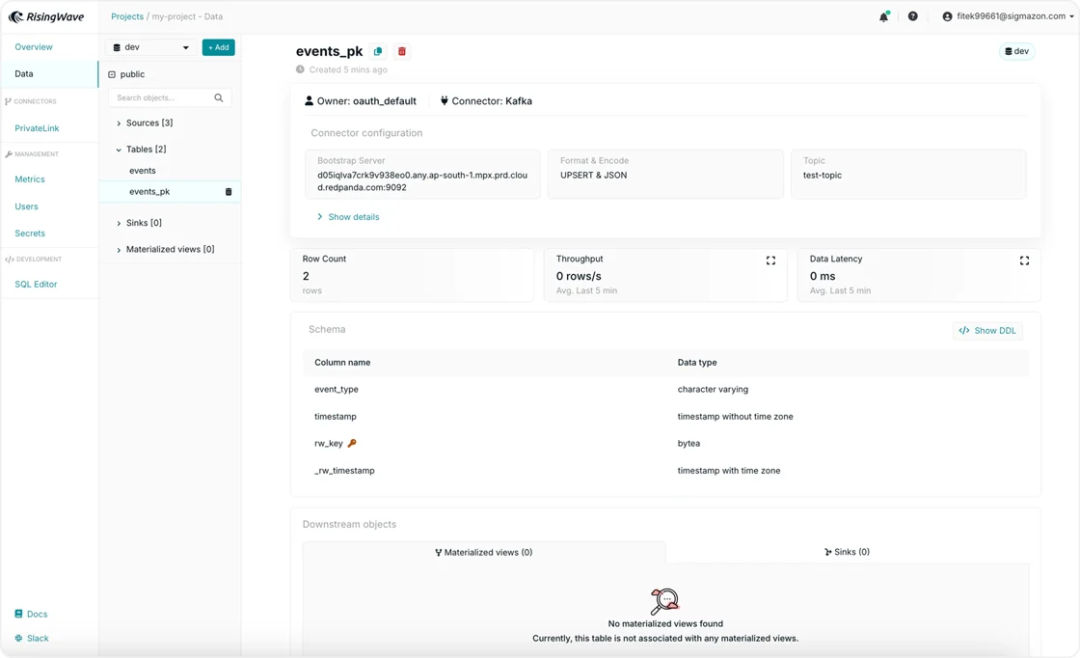
Table Details Page|图源:RW
RisingWave 现支持从 PostgreSQL 17 摄取 CDC 数据[1](此功能已处于公开预览阶段)。
RisingWave 现在支持在不中断运行的情况下动态调整共享源(Shared source)的并行度[2]。此前,共享源的并行度被锁定为与计算节点(CN)的并行度一致,每次修改都需要重启服务。 RisingWave 不断增强其 Iceberg 集成,以支持更多使用场景: RisingWave 现在可以作为 JDBC catalog[3],让用户通过第三方引擎查询托管的 Iceberg 表。 此外,目前除在 Amazon S3 和 Google Cloud Storage(GCS)上托管 Iceberg 表之外,RisingWave 还支持在 Azure Blob 存储上托管 Iceberg 表[4]。

文档更新
了解 RisingWave 全新的弹性磁盘缓存( Elastic Disk Cache)[5]如何提升性能并降低 S3 访问成本。通过使用本地磁盘(如 NVMe 或 EBS)作为缓存扩展,它可以缩短延迟并提高大规模流处理工作负载的效率。 RisingWave 已支持数据库隔离、资源组和跨数据库查制[6],使管理多个工作负载更加便捷,且能灵活访问并整合隔离环境中的数据。 RisingWave 与 Apache Flink 的详细对比[7],包括 SQL 功能、数据类型、流式操作和系统功能等各项重要指标。 端到端延迟性能指南[8]深入分析了影响 RisingWave 延迟的因素,并分享了在降低延迟与提高吞吐量之间保持平衡以优化性能的技巧。 RisingWave 提供多种与 Apache Iceberg 交互的方式,包括读取和写入外部 Iceberg 表、以 Iceberg 原生格式存储数据,以及将 Amazon S3 表作为 Iceberg 目录。请查阅官方文档[9]了解更多细节。

文章 1:RisingWave 四周年:我们的目标不只是流处理大众化[10]
四年来,RisingWave 始终致力于让流处理的强大能力触手可及。如今,我们正踏上全新征程。未来不仅关乎高效的流处理,更在于构建一个集成式、端到端的平台,将实时处理、实时服务与长期存储无缝衔接。
在流处理环境中通过 SQL 管理 Iceberg 表 原生支持 CDC 流和等值删除操作 基于标准 SQL 的实时 ETL 能力 对流数据管道的低延迟可见性 与 Iceberg 生态系统的全面兼容
我们展示了如何通过将 Databento 的市场数据与 RisingWave 的实时 SQL 处理能力相结合,构建一个用于识别欺诈性挂单(spoofing)的基础交易监控系统。我们引入了历史数据,并借助 RisingWave 的物化视图,持续识别基于挂单大小与其相对最佳买卖报价(BBO)位置的可疑撤单模式。
RisingWave v2.3 现已正式发布!此次更新包含了基于 Apache Iceberg 的列式存储、用于工作负载管理的资源组、全新的 SQL 函数等诸多新特性,为流处理工作带来了更强大的功能与更高的灵活性。
RisingWave v2.3 在管理复杂的多工作负载流处理环境方面实现了重大跃进。增强的数据库隔离机制提供了更加坚实的系统基础;资源组则带来了对计算资源、故障域与性能调优的精细化控制能力。在此之上,跨数据库查询功能打破了内部数据孤岛,使用户能够通过简单的 SQL 或基于 CREATE SUBSCRIPTION 的强大物化视图,灵活访问并整合隔离环境中的数据。

精彩活动
线上(25 年 5 月 8 日):Real-Time Data+AI[15]
伦敦(25 年 5 月 20-21 日):Current London[16]
从 PostgreSQL 17 摄取 CDC 数据: https://docs.risingwave.com/ingestion/sources/pg-cdc
[2]动态调整共享源(Shared source)的并行度: https://docs.risingwave.com/sql/commands/sql-alter-source
[3]JDBC ca talog: https://github.com/risingwavelabs/risingwave/pull/21400
[4]在 Azure Blob 存储上托管 Iceberg 表: https://docs.risingwave.com/integrations/destinations/apache-iceberg
[5]Elastic Disk Cache: https://docs.risingwave.com/get-started/disk-cache?utm_source=hs_email
[6]数据库隔离、资源组和跨数据库查询: https://docs.risingwave.com/operate/workload-isolation-interaction
[7]RisingWave 与 Apache Flink 的详细对比: https://docs.risingwave.com/faq/risingwave-flink-comparison
[8]端到端延迟性能指南: https://docs.risingwave.com/performance/troubleshoot-e2e-latency
[9]官方文档: https://docs.risingwave.com/iceberg/overview
[10]RisingWave 四周年:我们的目标不只是流处理大众化: https://www.risingwave.com/blog/risingwave-turns-four/
[11]RisingWave 引入 Iceberg 表引擎:用 SQL 管理 Iceberg 流数据: https://www.risingwave.com/blog/risingwave-iceberg-table-engine/
[12]使用 Databento 和 RisingWave 实时检测仿冒行为: https://www.risingwave.com/blog/spoofing-detection-databento-risingwave/
[13]RisingWave v2.3 亮点概览: https://www.risingwave.com/blog/highlights-of-risingwave-v23/
[14]RisingWave 中的工作负载隔离:数据库隔离、资源组和跨数据库查询: https://www.risingwave.com/blog/workload-isolation-in-risingwave/
[15]Real Time Data + AI: https://lu.ma/k2kfng9x
[16]Current London: https://current.confluent.io/london
关于 RisingWave


技术内幕
👇 点击阅读原文,立即体验 RisingWave!
