




Doris是什么
Apache Doris 是一个基于 MPP 架构的高性能、实时分析型数据库,
最早由百度内部孵化,用于解决百度凤巢统计报表的分析需求。
Doris 支持标准 SQL,兼容 MySQL 协议,
具有高并发点查询、分区、分桶、裁剪等特性,
适用于多维报表、即席查询、用户画像、实时大屏等场景
2017年正式对外开源,
2018年7月由百度捐赠给 Apache 基金会进行孵化。
2022年6月,Apache Doris 成功从 Apache 孵化器毕业,
正式成为 Apache 顶级项目
商业版的数据库是:
SelectDB
百度智能云初创人员和 Apache Doris 项目核心成员
创立的商业化公司北京飞轮科技有限公司(SelectDB)
StarRocks
基于 Apache Doris 的一个分支,但与 SelectDB 不同,
StarRocks 对 Apache Doris 进行了硬分叉,并且不再回馈社区。
StarRocks 强调其开源协议不同,并且在商业化上更早,主要面向金融和互联网市场
也是百度palo项目组成员创立的
需要说明, 百度内部人员也成立了很多公司,
包括最近比较好的 昆仑芯GPU
还报错业内比较好的百度飞桨AI框架
Doris的部署架构
Doris的部署其实比较简单:
主要是FE和BE 以及对外数据存取用的broker:
FE:
Frontend,即 Doris 的前端节点。
主要负责接收和返回客户端请求、元数据以及集群管理、查询计划生成等工作。
BE:
Backend,即 Doris 的后端节点。
主要负责数据存储与管理、查询计划执行等工作。
Broker:
Broker是Doris 集群中一个可选进程,
主要用于支持 Doris 读写远端存储上的文件和目录,
例如 HDFS、BOS 和 AFS 等
Doris Broker 通过提供一个 RPC 服务端口来提供服务,
是一个无状态的 Java 进程,
负责为远端存储的读写操作封装一些类 POSIX 的文件操作,
如 open,pread,pwrite 等等
一个简单的类比
Apache Doris 的架构中,
FE(Frontend)相当于 MySQL 的服务器层,
负责处理客户端的连接、SQL 解析、查询优化、
权限控制等任务。
FE 负责与客户端建立连接,接收 SQL 查询请求,
进行查询解析和优化,然后与 BE(Backend)通信以执行查询。
在 MySQL 中,数据库服务层通常指的是 MySQL Server 本身,
它处理客户端连接、SQL 解析、查询优化等任务。
InnoDB 是 MySQL 的一个存储引擎,负责数据的物理存储和检索。
将 Doris 和 MySQL 对比:
Doris FE 类似于 MySQL Server,负责处理客户端连接和 SQL 查询。
Doris BE 类似于 InnoDB 存储引擎,负责数据存储和检索。
极简监控
doris 其实与很多开源分布式数据库一样, 比如tidb.
都可以实现一些使用情况的暴露与监控
一个极简的监控配置如下:
配置节:
scrape_configs:
- job_name: 'doris_monitor'
static_configs:
- targets: ['xx.xxx.xxx.207:8030']
labels:
group: fe
- targets: ['xx.xxx.xxx.207:8040', 'xx.xxx.xxx.208:8040', 'xx.xxx.xxx.209:8040']
labels:
group: be
Grafana监控界面导入:9734
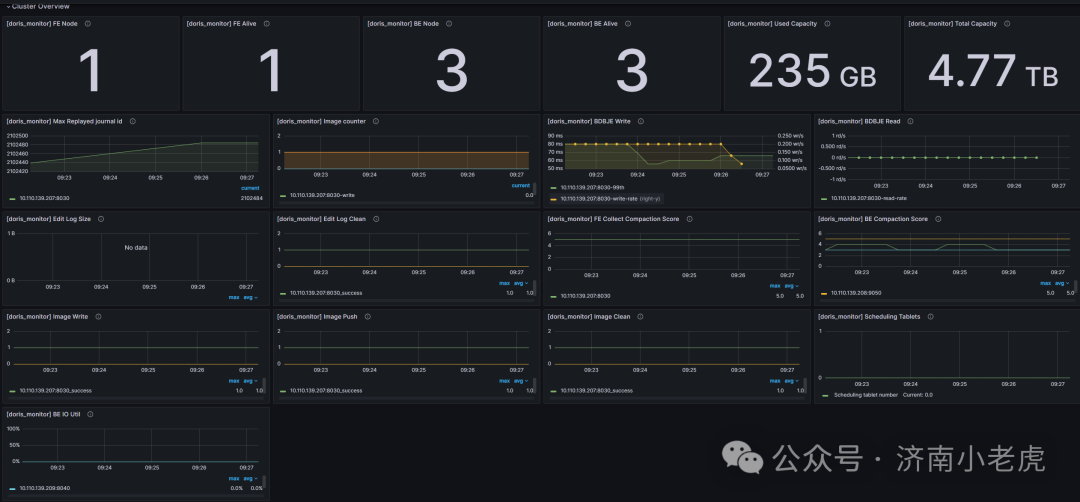
监控效果
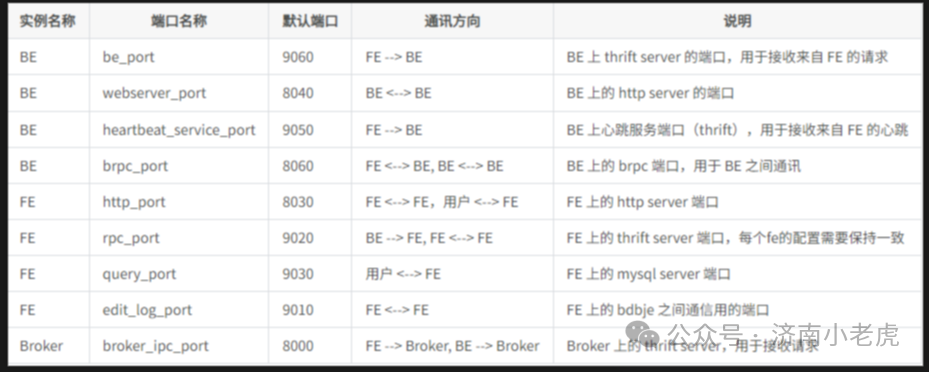
Doris的一些相关端口信息
一些分布式数据库的性能理解
现阶段很多分布式数据库都是采用LSMTree的模式进行.
在数据量变动不大的情况下.
memtable 里面能够存储很多数据.
不需要sstable的协同的话,他的处理效率是非常令人震惊的.
毕竟内存的速度至少三到六个数量级于存储.
但是他的问题就是内存数据老化,数据变动累积,
以及残酷的未变动数据的大量读放大
会导致存储层的性能下降.
并且因为不管是通过go还是通过java改写mysql/pg的SQL解析层
他的效率很难跟mysql原生比拟, 更遑论Oracle.
不过分布式开源数据库一个很大的优点是
不管是Doris的FE还是TIDB里面的TiDB组件
都可以增加多个节点.并且也可以对应多个后端BE/TiKV
可以将并发的任务分散到不同的节点上来.
一方面可以到不同的SQL解析引擎(FE),避免hard parse消耗过多.
另一方面通过多副本的存储机制, 不同副本可以再不同BE上面进行IO和计算
这样可以实现 1+1+1>1效果.
虽然因为 多副本之间的同步,有一定的commit延迟.
但是通过高速网络和 memtable 写入就返回,不需要入盘的模式来看
他的效果肯定要比redo日志入库要快的.
唯一的缺陷还是缺少Oracle这样五十余年的积累.
复杂SQL复杂场景的适应性还是有所欠缺.
买得起贵东西的人可能没你聪明, 但是眼光肯定比你好.
文章转载自济南小老虎,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
