




数据库管理323期 2025-05-09
数据库管理-第323期 Oracle如何统计表数据量(20250509)
作者:胖头鱼的鱼缸(尹海文) Oracle ACE Pro: Database PostgreSQL ACE Partner 10年数据库行业经验 拥有OCM 11g/12c/19c、MySQL 8.0 OCP、Exadata、CDP等认证 墨天轮MVP,ITPUB认证专家 圈内拥有“总监”称号,非著名社恐(社交恐怖分子) 公众号:胖头鱼的鱼缸 CSDN:胖头鱼的鱼缸(尹海文) 墨天轮:胖头鱼的鱼缸 ITPUB:yhw1809。 除授权转载并标明出处外,均为“非法”抄袭

最近拿到一个需求,就是一定要在做专项优化的时候,需要批量得到对应表当时的精确数据量,说白了就是需要count的结果,就这一操作让我觉得不大合理。
1 count
一般来说我们在做数据统计的时候会使用count(*)、count(1)和count(列名)的三种方式,只不过一般会有where条件来限制统计口径,不加限制条件就是全表统计。count(列名)最大的问题是如果列中有NULL值的数据,则不会被统计,结果则会不准确,如果有NOT NULL约束则数据准确。在Oracle中count(*)和count(1)基本是等同的,全表统计的时候执行计划会使用全表扫描(TABLE ACCESS FULL)或索引快速全扫描(INDEX FAST FULL SCAN)来执行语句,后者访问索引本身而不访问表因此效率是要高于前者的,但是也有限制,对比count(列名),在需要获取全表准确数据量的时候对应索引所包含的列至少有一列需要有NOT NULL约束。
在count(*)和count(1)时,如果使用全表扫描且表比较大的话,肯定会占用较多的IO,很可能在count过程中影响到数据库的性能,
2 Database Buffer Cache
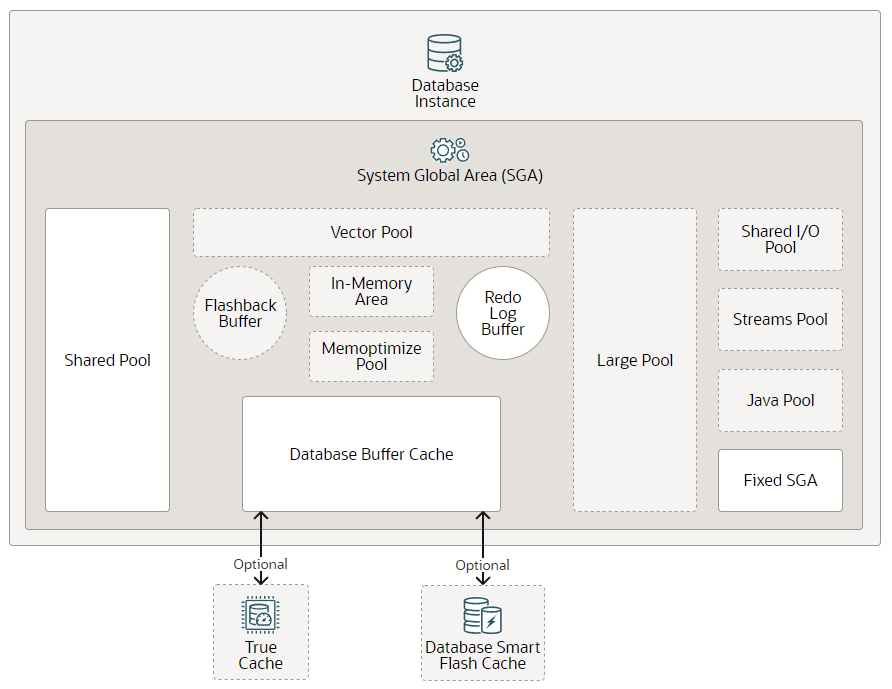
Oracle数据库,在内存的系统全局区(System Global Area,SGA)中,有一块内存区域叫Database Buffer Cache,也可称之为数据库高速缓冲缓存。其最大作用是将常用和现在需要的数据从磁盘中的数据加载内存之中,因为内存的操作读取效率是远高于磁盘的,Buffer Cache可以显著提升数据操作和查询的性能,同时因为减少了磁盘交互从而减少IO资源的占用。
从19c开始还可以使用NVMe SSD来存放要求不那么高的缓存数据(Database Smart Flash Cache)提升Buffer Cache容量,在内存和磁盘之间增加一层缓存。而23ai引入的True Cache则可以增加海量的只读内存池,进一步提升数据库的读性能。
3 LRU
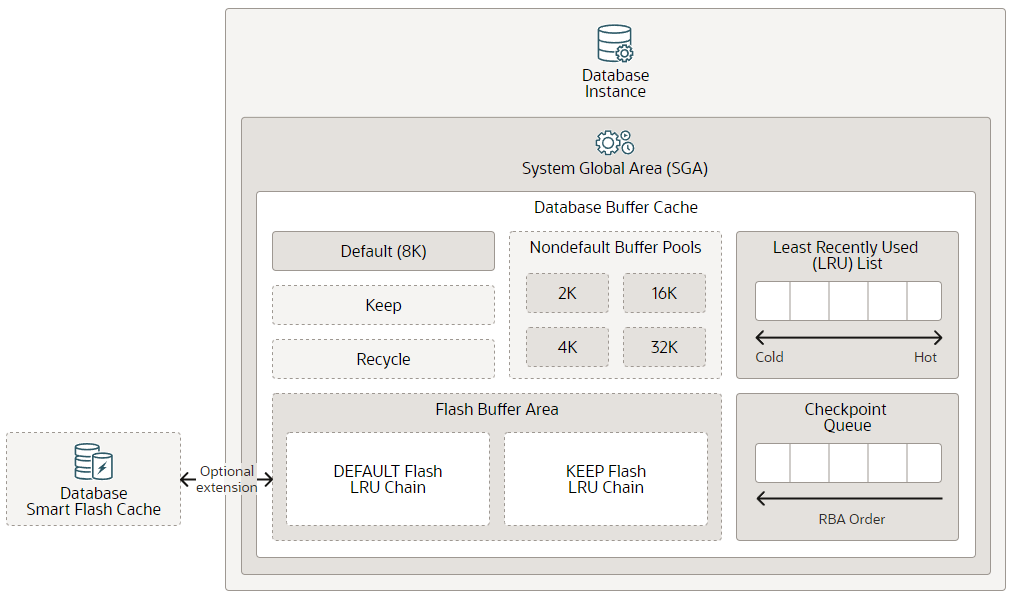
内存的容量肯定比不过磁盘,那么怎么高效的将需要的数据缓存到Buffer Cache中成为了数据库自我维护管理的重要一环,在Buffer Cache有这样一块区域叫做LRU链表(Least Recently Used List),里面会判断并记录哪些数据是常用的热数据,哪些数据是不常用的冷数据,在LRU链表中有冷热两端,冷端是最近未被访问的缓存数据,热端则是经常被访问或者刚刚被使用的缓存数据,缓存数据会根据根据时间和使用频率在冷热端进行移动。空间不足需要缓存新数据时会从冷端腾出空间进行缓存。
接下来是来自于吕海波老师的信息:
在Buffer Cache总共有两种LRU:主LRU和辅助LRU,大表的全表扫描只会进入辅助LRU,辅助LRU大概占用Buffer Cache的25%左右。
因此使用count统计表数据量并不是一个合理的选项,该操作是可能会影响到Buffer Cache的缓存数据进而影响数据库性能,更大的隐患则是对LRU链表的冲击,数据库可能需要更多的时间重新评估LRU。
4 统计信息
在数据库系统视图USER|ALL|DBA_TABLES展示了表的多项统计信息数据,其中有一列就是表行数的统计信息:


一般来说这个数值和表数据量比较接近,在《数据库管理-第九十八期 统计信息是多么重要(20230812)》中也提到过,虽然数据库有定时统计信息收集的维护任务,也有一些机制会触发统计信息收集,但数据库的统计信息不是实时的,在实际生产中对于持续进行增量写入的表统计信息和实际数据量往往会有较大差值(我遇到过的两次维护窗口之间最大差值可达20%)。虽然在19c中引入了实时统计信息的功能,其主要作用是减少优化器被过时统计信息误导的可能性。在DML操作时,数据库会动态计算最基本统计信息的值。这里需要注意的是实时统计信息收集是增强而不是取代传统统计信息,仍要确保自动统计信息收集任务正确执行,而且在一些版本上存在一些BUG。
前面说到了count的主要问题是占用IO资源和影响Buffer Cache效率,虽然通过DBMS_STATS手动收集统计信息也会带来额外开销,不建议在生产时段使用,但其的整体影响还是是小于使用count,如果必须要获取相对精确的表数据量信息,还是手动收集统计信息吧。
当然在出现比较严重的性能问题的时候,需要排查是否是统计信息导致的执行计划生成不准确,从及时溯源的角度还是得用count来评估数据量和统计信息的差值,然后再手动收集统计信息。
总结
在数据库日常管理中,非必要情况下不建议通过实时查询(如 COUNT(*))来获取表的精确行数,这类操作开销大、影响性能,应优先依赖统计信息或近似估算。
老规矩,知道写了些啥。
