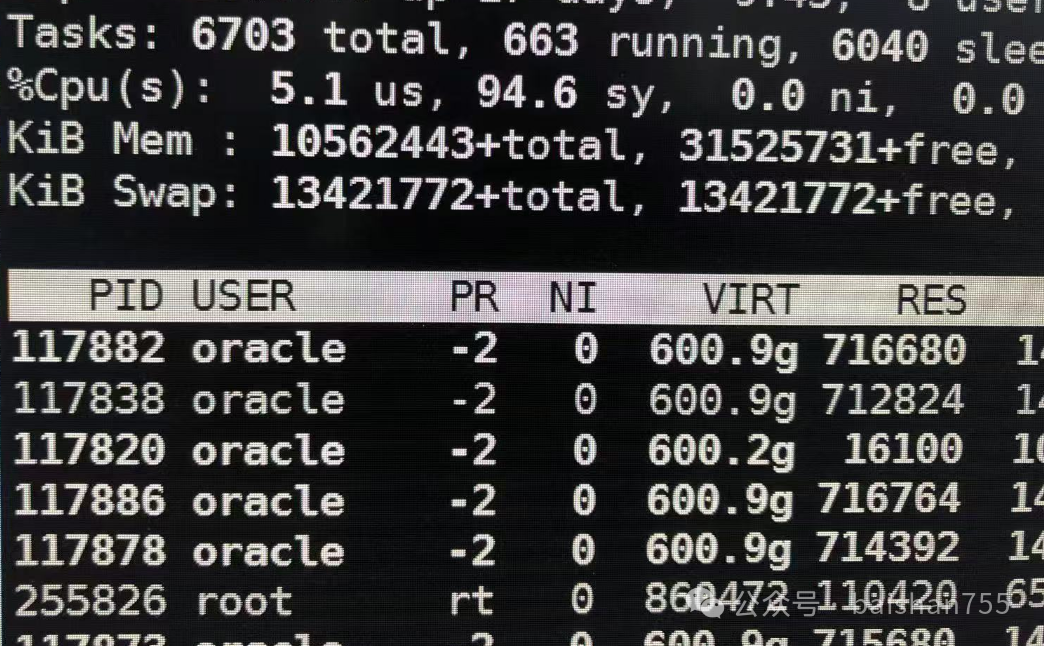
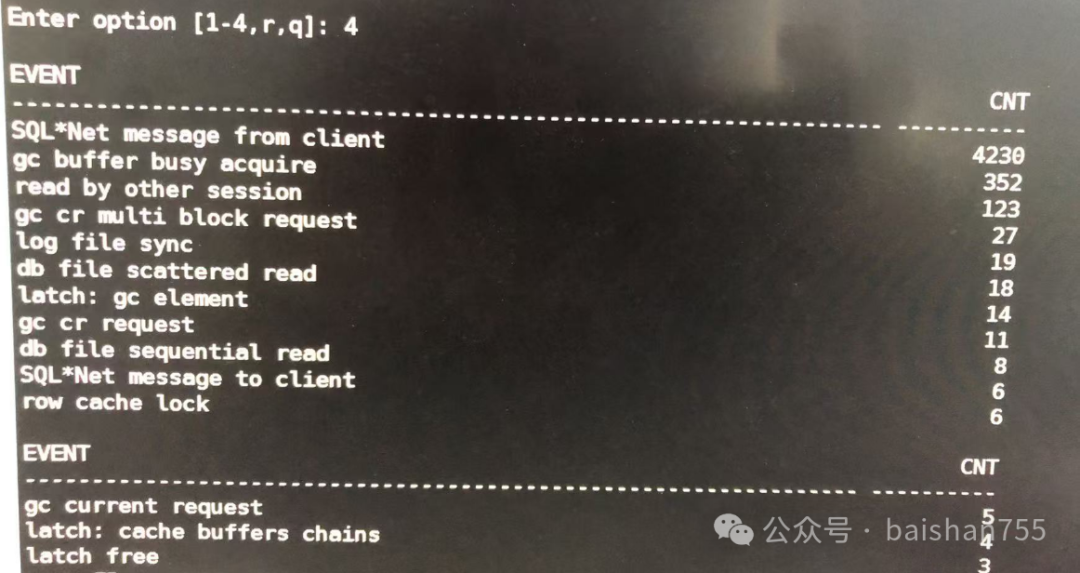
前两天一个客户微信上发来一个top的截图,让我看看,是不是CPU不正常。我一看,CPU太不正常了,USR才5.1%,SYS 94.6%,这种情况一般来说闩锁有问题的可能性比较大,SPINLOCK争用很严重才会出现的。最为常见的是共享池问题、DB CACHE的CBC,热快,GC争用等。我问他应用现在怎么样?他说有点慢。如果手头的监控运维手段有限,那么最简单,最快速定位问题的方法是通过v$session看看等待事件,因为目前采集AWR估计也会相当慢。上面的信息已经相当明确了,大量的热块冲突引发了这个问题,一般都是与SQL有关的。下一步有一个十分快速定位问题的方法,那就是通过等待gc buffer busy acquire和read by other session的会话正在执行的SQL去快速定位问题。这种情况下,大概率是这些SQL都在访问1、2张表。客户那边很快反馈了,确实是集中到十几条SQL上,这些SQL都是和SELECT一张表有关的。那么下面如何更加快速地逼近问题的根因呢?以我的经验,大概率是执行计划或者执行频率出现了问题。客户认为业务量是正常的,所以很可能是执行计划的问题。经过分析确实发现了一个本该走索引的查询执行了全表扫描。重新做了表分析后,杀掉积压的会话,系统慢慢恢复正常了。此类问题是DBA经常会遇到的紧急处置场景,而且往往都发生在核心的交易系统上。快速处置是应对的关键,因此这种情况下,可能没有太多时间让你去查知识库、找二线专家。不过这种时候也往往是体现DBA价值的时候,因此掌握一种快速处置方法十分关键。这个方法的关键是找到问题,找到临时解决问题的方法,然后一边杀会话一边尝试解决问题。杀会话刚开始的时候是让系统能够不至于崩溃,确保业务还能缓慢运行,不会被考核为故障。不过大多数时候光杀会话无法解决问题,这时候就需要找到临时性或者终极解决方案了。很多DBA习惯第一时间查AWR报告,实际上这种情况下,看AWR已经不够快了。直接对v$session进行统计分析是更快定位问题的方法。如果看到了我遇到的这些等待事件,那么大概率是和SQL有关的。直接分析等待这些等待事件的SQL,特别是找到那些start_exec时间和当前时间相减超过1秒的SQL(有些时候可能是超过100ms,也就是比平时慢很多的),看这些SQL的共同特点,比如访问了同一张表,还有一种比较大可能遇到的就是访问某个sequence。如果是GC/BBW/CBC类的等待事件,大概率是执行计划错了,相关表重新统计或者用SQL PROFILE/HINT强制走回正确的执行计划就能暂时解决问题了。如果是共享池相关的,可能会与解析相关。回到这个案例,纠正了执行计划之后,可能还会有一些SQL在沿用老的执行计划,大概率最后应用还是会报错,所以最好的方法是直接把这些会话杀干净。这个三板斧在二十年前,是经常被我们团队用来救命的,这个案例中,最后还是在没有被记录故障的前提下完成了应急处置。对于其他数据库,甚至大多数国产数据库,这个方法依然有效,只不过找问题根因的方法不同,也更麻烦一些。希望我介绍的这个小技巧能够在未来的国产数据库运维中对你有所帮助。